爬虫基础
一. 简介
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。其实爬虫本质上是模拟浏览器向后端发送请求,获取数据,解析并且获得想要的数据,然后存储。
爬虫的价值主要体现在数据方面,爬取数据大致分为四步:发送请求--》获得数据--》解析数据--》存储数据。
因为爬虫与网络息息相关,所以需要对http协议有一定的了解。
这里简单提一下http协议中需要关注的。首先,一次请求分为请求与响应两部分。
请求中需要注意的:
#URL:指明要去哪里 比如https://www.baidu.com #method : 请求方式 GET: 传递数据,会将数据直接拼至URL后面,比如 https://www.baidu.com/?name=xx&age=18 POST:请求数据均存放在请求体中 formdata:存放普通的键值对数据 files:存放二进制流文件,比如视频、音频、图片等 json:存放json格式数据 # 请求头 Cookie:除了存放用于辨别客户端身份的信息外,还能存取其他数据 Referer:告诉服务器你是从哪里过来的,一般用于防盗链 User-Agent:告诉服务器你的身份,比如你是什么浏览器等
响应中需要注意的:
#Status Code:状态码,不过并不能什么时候都以该状态码作为标准,因为程序的状态码是可以程序员自定义的 1xx:服务器已收到请求,正在处理 2xx:请求成功 3xx:重定向 4xx:客户端操作不当,其中403表示权限不足,404表示资源不存在 5xx:服务器错误 #响应头: location: 跳转地址 set_cookie:设置cookie # 响应体 1.HTML代码 2.二进制:图片、视频、音乐 3. json格式
二. 常用请求库
使用请求库时,可以使用测试网站:
pip install requests
响应对象 = requests.get(......) **参数:** url: # 请求的url 如https://www.baidu.com headers = {} # 优先级高于cookies,如果里面写了cookie键值对,那么下面的cookies参数不生效 cookies = {} params = {} # 里面的参数会采用get请求参数传递的方式拼至url后面 proxies = {'http':‘http://端口:ip’} # 代理池,根据请求的url确定协议是http或https timeout = 0.5 # 超时时间,如果此时请求还未完成,会直接抛出ConnectionTImeout异常,from requests.exceptions import ConnectTimeout allow_redirects = False # 为False时表示禁止重定向。比如这样可以通过location获取跳转的url。
2.12 post请求
响应对象 = requests.post(参数1, 参数2,......),参数同get的很多参数一致。
响应对象 = requests.post(......) **参数:** url: # 请求的url 如https://www.baidu.com headers = {} # 优先级高于cookies,如果里面写了cookie键值对,那么下面的cookies参数不生效 cookies = {} data = {} # 存放普通键值对数据 json = {} # 存放json格式数据 files = {‘file’:open(...,‘rb’)} # 存放二进制数据,如图片、视频、音频等二进制流 timeout = 0.5 # 超时时间,如果此时请求还未完成,会直接抛出ConnectionTImeout异常,from requests.exceptions import ConnectTimeout allow_redirects = False # 为False时表示禁止重定向。比如这样可以通过location获取跳转的url。
2.13 自动保存cookie的请求
因为爬虫需要模拟浏览器朝后端发送请求,为了让后端认为你是真正的浏览器,必须携带cookie,requests中提供了方法来自动记录访问过的网站的cookie,并根据url自动从记录中查找。
session = requests.session() # 生成可以保存cookie的对象,在原先的reqeusts对象上多了一个自动保存cookie的功能 r = session.get(......) r = session.post(......) # 补充:(保存cookie到本地) import http.cookiejar as cookielib session.cookie = cookielib.LWPCookieJar() # 覆盖session的cookie,让其具有.save方法 session.cookie.save(filename='1.txt') # 将session对象访问过的cookies全部保存至文件,filename需要一个路径,这里是相对路径 session.cookies.load(filename='1.txt') # 读取用.save方法保存的文件,将其中的cookies全部读取出来。该方式可以用于养号,
# 比如爬一个网站时,可以养一堆号,每次随机取出一个cookie让一个号携带去爬该网站,同时将爬取的频率降低,降低被封ip的的概率。
2.14 响应
有请求就一定会有响应,requests.get()与requests.post()返回的响应对象也具有很多方法:
r.url # 获取请求的url r.text # 字符串格式的请求页面 r.encoding = 'gbk' # 针对r.text的编码 r.content # 二进制流的请求html页面 r.json() # 实际是json.loads(r.text),所以使用时我们需要确保获取的是json数据,不然会报错,一般可以在检查--》 r.status_code # 获取状态码 r.headers # 获取请求的头部信息 r.cookies # 获取请求的cookies r.history # 返回一个列表,里面保存着重定向前的对象
如果编码与解码采用的字符集不同,就好产生乱码。准确拿到一个页面的编码格式,有两种方式:
方式一:pycharm中新建一个file文件,将r.text的内容保存在其中,如果页面的字符集跟你设定的字符集不同,那么pycharm会自动提示页面对应的字符集。
方式二(建议使用该方式):在对应的网页中打开控制台,使用document.charset查看
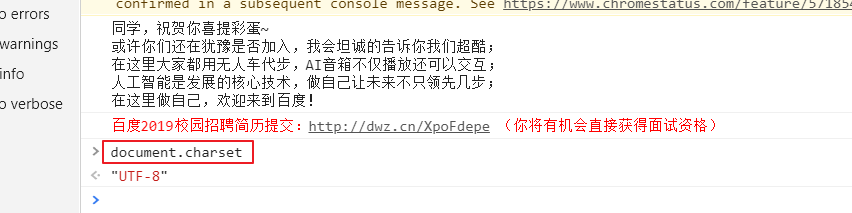
接下来演示一下响应中的一些方法,大多数都使用测试网站
2.141 r.url、allow_redirects=False、r.history
r.url是返回请求对象的url,而allow_redirects=False是禁止重定向,这意味着url写错了就无法正常跳转。然后r.history是获取重定向前的Response对象,也就是说没有重定向时r.history是空的。这里以天猫为例:
import requests session = requests.session() url = 'http://www.tmall.com' r = session.get(url=url) print(r.url) # https://www.tmall.com/ print(r.history) # [<Response [302]>]
可以看到自动将http变为了https,这意味着重定向了。接下来将allow_redirects=False加上:
import requests session = requests.session() url = 'http://www.tmall.com' r = session.get(url=url, allow_redirects=False) print(r.url) # http://www.tmall.com/ print(r.history) # []
即无法进行重定向,所以r.history为空。
2.142 timeout
可以给请求设定超时时间,当改时间内请求未结束时,会直接抛出异常:
import requests session = requests.session() url = 'http://www.tmall.com' r = session.get(url=url, timeout=0.001)
可以导入一个模块来捕获该异常:
from requests.exceptions import ConnectTimeout

2.143 r.json
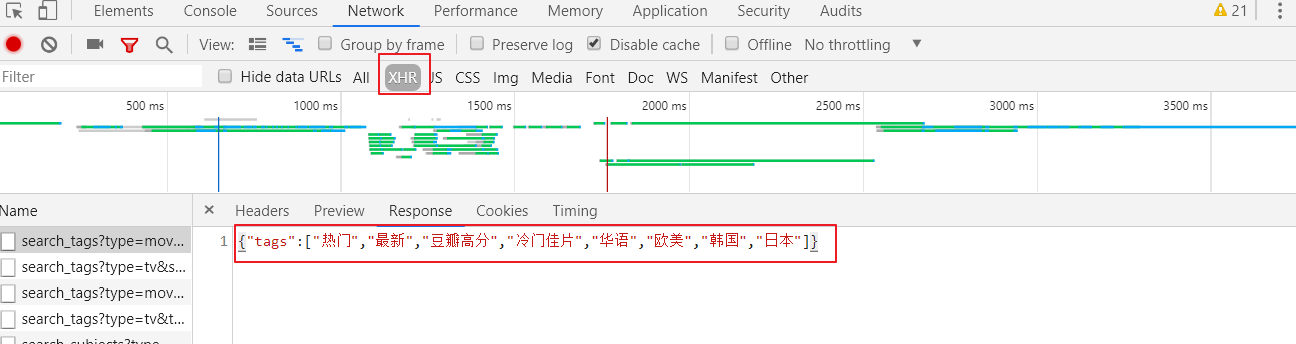
r.json实际上就是json.loads(r.text),这就要求r.text返回的必须是json对象,一般可以在浏览器检查NETWORK中的XHR中查找,这里以豆瓣电影为例:
import requests session = requests.session() url = 'https://movie.douban.com/j/search_tags?type=movie&source=index' r = session.get(url=url) print(r.json())
2.144 浏览器补充
2. 145 r.status_code
r.status_code是用于返回当前请求的状态码,因为状态码是可以程序员自定义的,所以不能每次都以200判断请求成功,不过200可用于IP代理池,用于判断IP代理池中的某个IP是否有效。
三. 常用解析语法
解析语法有CSS与xpath等,两个其实会一个就行了,不过有兴趣可以都看看。xpath:https://www.w3school.com.cn/xpath/index.asp。
这里只举css常用的语法,不过这些语法足以找到所有的标签:
### css选择器 1、类选择器 .类名 2、id选择器 #id名 3、标签选择器 标签名 4、后代选择器 选择器1 选择器2 5、子选择器 选择器1>选择器2 6、属性选择器 [属性] #有该属性的所有标签 [属性=值] #属性值为此处给的值的所有标签 [属性^=值] #属性值以此处给的值开头所有标签 [属性$=值] #属性值以此处给的值结尾所有标签 [属性*=值] #属性值包含此处给的值所有标签 7、群组选择器 选择器1,选择器2,.... #各选择器间是or的关系 8、多条件选择器 选择器1选择器2,.... #各选择器间是and的关系
四. requests-html
相比requests模块,requests-html显的更加强大,它内部封装了一个html对象,提供更多更方便的操作Response对象的方法。
首先安装模块:
pip install requests-html
4.1 requests-html的参数
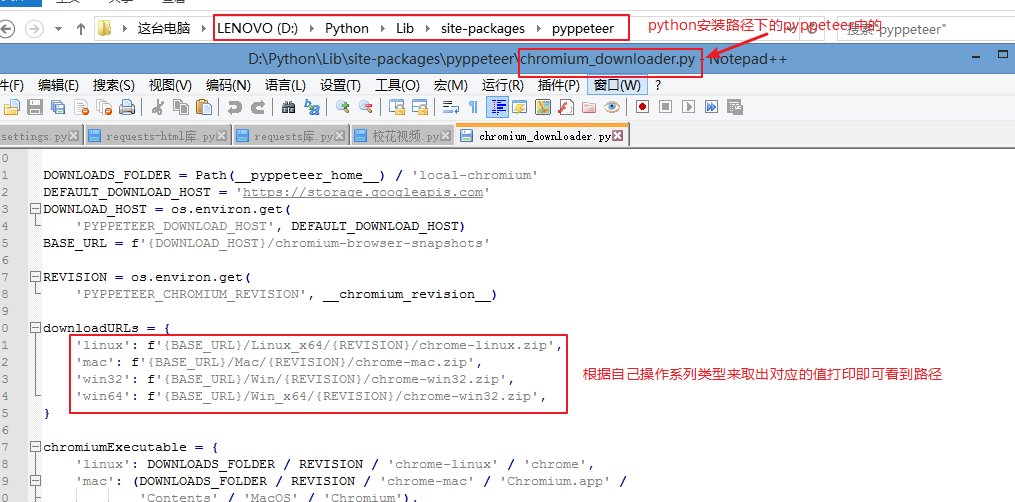
一般导入其中的HTMLSession对象进行实例化,因为很多页面的数据是动态渲染的,对应的requests-html内部也提供了使用浏览器内核渲染页面的功能。在第一次使用HTML对象的render方法时,会自动将该浏览器下载至我们本地,如果在提示下载失败,可以在cmd窗口中允许程序,使用r.html.render(),以此来通过cmd下载,因为下载是从外网直接下载,所以可以考虑FQ。下载的路径可以在允许render的python版本中的文件中找到(见下图):
使用时请求与响应的常用参数(参数很多同requests一样,所以下面没写)如下:
from requests_html import HTMLSession session = HTMLSession() **参数:** browser_args = [ # 浏览器运行配置 '--no-sand', # 以最高权限运行浏览器 '--user-agent=XXXXX' #=号左右两边千万不能有空格,不然运行没反应 ] 响应对象 = session.request(......) # 需要用method参数指定请求的方式 响应对象 = session.get(......) 响应对象 = session.post(......)
4.2 html对象的属性与方法
html对象属性:
from requests-html import HTML html = HTML(html='') # 里面可以传一个字符串,得到的html对象等同r.html,也可以使用render进行渲染。所以可以读取本地的文件,将其进行渲染 r.html.absolute_links # 将页面所有的链接都变为绝对链接返回,以集合的形式,进行了去重 .links # 返回页面中的原始链接 .base_url # 返回页面的基地址 .html # 返回页面的html代码 .text # 返回所有的文本信息 .encoding = 'gbk' # 编码针对r.html .raw_html # 返回二进制流 .qp # 返回PyQuery对象,可以调用PyQuery的方法
html对象方法:
r.html.find('css选择器') # [element对象, element对象] .find('css选择器',first = True) # element对象 .xpath(‘xpath选择器’) .xpath('‘xpath选择器',first = True) .search(‘模板’) # 返回一个parse.Result对象, 可以用dir方法来查看对象内部的属性与方法;对象的text与full_text的区别是前者只会返回文本,而后者会把空格等也返回;attrs会将标签的所有属性与值以字典的形式返回; (‘xxx{}yyy{}’)[0] (‘xxx{name}yyy{pwd}’)[‘name’] .search_all('模板') # 列表套parse.Result对象 .render(.....) # 第一次使用render时会下载一个浏览器chromium(开发者版本)。浏览器分为有头与无头,有头是指打开时会有浏览器窗口弹出,无头则不然,只会在后台运行。默认安装在这下面C:\Users\计算机名\AppData\Local\pyppeteer\pyppeteer\local-chromium **参数:** scripy:“”“ ( ) => { # 固定写法,如果里面return比如return document.charset,那么调用render就能得到该返回值 js代码 js代码 } ”“” scrolldow:n # 滚轮滚动的次数,自动翻 sleep:n # 滚轮每滚动一次停留的时间 keep_page:True/False # True允许通过r.html.page与浏览器进行交互
()=>{ # 写在scripy中,当做script的参数传入
Object.defineProperties(navigator,{
webdriver:{
get: () => undefined # 因为正常的浏览器webdriver是undefined,而爬虫用浏览器内核渲染的是true
}
})
}
4.3 与浏览器交互 r.html.page.xxx
使用前一定要将render中的keep_page参数设置为True,这里以获取一个页面的编码格式为例,不过首先要先改写源码,将无头该有有头(有头即我们平时使用的浏览器的样子,具有交互界面):
from requests_html import HTMLSession
进入HTMLSession,发现实例化时是调用父类BaseSession的__init__方法。
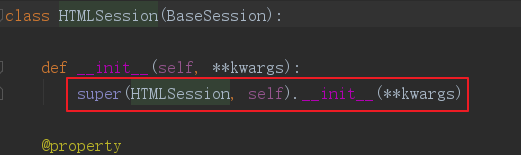
然后进入BaseSession,先增加一个参数,并加入实例化对象的名称空间:
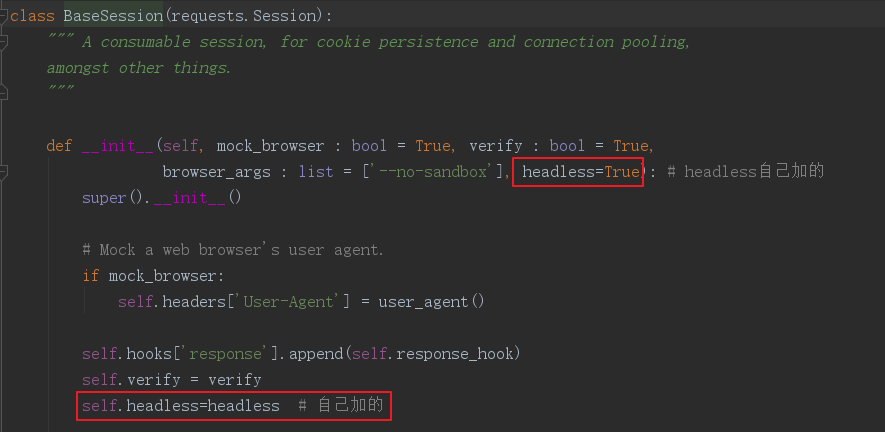
再继续下拉一点点,修改其中的browser函数:

上述的async表示协程,这样就修改完毕了。
from requests_html import HTMLSession session = HTMLSession( browser_args=[ '--no-sand-', # 以最高权限运行浏览器 '--user-agent=Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' ], headless=False # 有头浏览器 ) url = 'https://movie.douban.com' # 此处以豆瓣为例 r = session.get(url=url) charset = r.html.render( # 获取对应详情页的字符编码 keep_page=True, # 该参数设置为True时才能与浏览器进行交互 script=''' # js语法,进行js注入 ()=>{ return document.charset } ''' ) print(charset)
使用上述方式会打开渲染的页面,执行完毕后自动关闭,不要手动将弹出的浏览器关了。
4.31 与浏览器交互的方法以及协程的使用
先说协程,在python中使用协程时可以使用以下方式:
import asyncio async def 函数名(参数, 参数....): await r.html.page.screenshot({'path':'1.png'}) asyncio.get_event_loop().run_until_complete(函数名(参数, 参数....))
不过使用requests-html使用时,可以直接用实例化出的对象调用loop来实现:
async def main(): await r.html.page.screenshot({'path':'1.png'}) session.loop.run_until_complete(main())
先补充一点,有些方法需要我们提供x,y参数,即页面中的位置,我们可以使用.x .y来获取标签相对于屏幕的位置。offsetLeft等方法获得的位置是对于其父级标签而言的。
与浏览器交互的方法:
asynic def xxx(): # 协程
await r.html.page.XXX
session.loop.run_until_complete(xxx())
.screenshot({'path':路径 'clip': {'x':200, 'y':200,'width':400, 'height': 400}})
.evaluate('''() =>{js代码}’‘’}) # js注入
.cookies() # 浏览器渲染之后获取的cookie
.type('css选择器',’内容‘,{’delay‘:100}) # delay延迟输入,单位是毫秒
.click('css选择器')
.focus('css选择器') # 输入框的聚焦,可以配合键盘事件的type使用,不过聚焦时没有任何提示,没有光标闪动
.hover('css选择器')
.waitForSelector('css选择器') # 等待元素被加载
.waitFor(1000) # 等待时间,单位毫秒
4.32 键盘事件r.html.page.keyboard.xxx
.down('Shift') # 就算一直按着,也只会触发一次该事件 .up('Shift') # 键按下,键盘事件直接写键盘上对应按键上面写的字即可 .press('ArrowLeft', {‘delay’:100}) # down+up,此处的100依旧是毫秒 .type('喜欢你啊',{‘delay’:100}) # 输入,可以配合浏览器的focus事件使用
4.33 鼠标事件r.html.page.mouse.xxx
.click(x,y,{ 'button':'left', 'click':1 # 点击的次数 'delay':0 # 点击的间隔 }) .down({'button':'left'}) # 不写默认就是左键 .up({'button':'left'}) .move(x,y,{'steps':1}) # steps是分几次过去,越大越慢
五. 爬虫小例子
这里以爬取校花网的图片与vip为例子,首先单线程即可,不然校花网容易崩,我们要温柔的爬。
由于校花网内容容易引起身体不适,这里只给出代码及部分说明。
5.1 爬取校花网-大学校花图片
首先进入该网站:http://www.xiaohuar.com/hua/,用检查点击任意一张图片

然后找到该标签,获取src与alt,然后因为有很多页,点击页数:
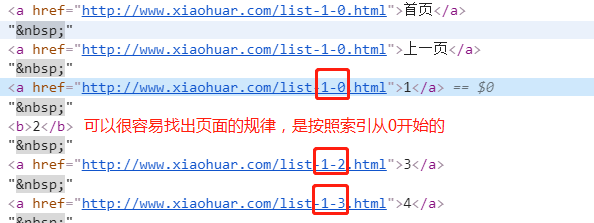
其中很容易就能找出页面的规律,这样我们就能直接先获取页面的url进行解析,获取页面中所有的图片名称与src,然后再解析对应的src,将图片保存至本地即可。代码如下:


#校花网页码 # http://www.xiaohuar.com/list-1-0.html 第一页 # http://www.xiaohuar.com/list-1-1.html 2 # http://www.xiaohuar.com/list-1-2.html 3 #生成所有页码url def get_page_url(): for i in range(46): yield 'http://www.xiaohuar.com/list-1-{}.html'.format(i) from requests_html import HTMLSession import os session = HTMLSession() #解析页面,获取图片名和url def parse_page(url): r = session.request(method='get',url=url) img_element_list = r.html.find('[class="img"] img') # 找到图片的标签 for img_element in img_element_list: # 处理图片名称中的/与\,防止路径拼接出现错误 file_name = img_element.attrs.get('alt').replace('/','').replace('\\','') # 获取图片的url file_url:str = img_element.attrs.get('src') file_url = r.html.base_url[:-1] + file_url if not file_url.startswith("http") else file_url save_file(file_name,file_url) def save_file(name,url): base_path = '校花图片' file_path = os.path.join(base_path,name) # 朝图片的url发起解析 r = session.get(url=url) with open(file_path,'wb') as f: f.write(r.content) print('%s下载成功'%name) if __name__ == '__main__': for page_url in get_page_url(): parse_page(page_url)
5.2 爬取校花网-美女视频
校花网中视频是需要vip,而其中的视频播放分为两类,一类是使用video标签,通过src属性给予视频url进行播放;一类是使用播放器,使用该方式时肯定会给予对应的视频文件播放列表,一般是m3u8,像腾达等都采用m3u8格式视频,将很多m3u8格式的视频拼接成一个,这样播放时无论进度条怎么拉,都只需加载对应的m3u8文件即可,而m3u8视频文件通常都不大,这就意味着加载会很快,让用户体验更佳。
首先同下载图片,先找一下页码:
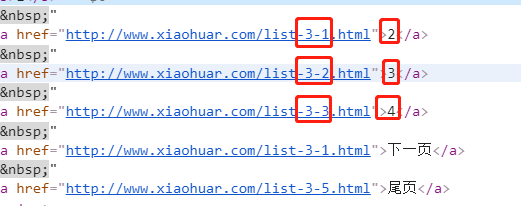
同样很容易就能使用字符串替换拼接出对应的页面url,接下来只需获取所有视频详情页的url,然后根据详情页中视频的url获取视频即可,先看一下video标签:
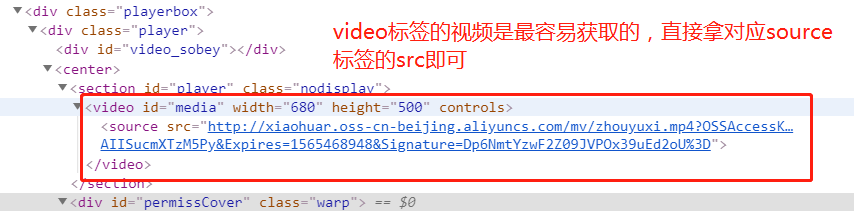
再看下第二种方式:
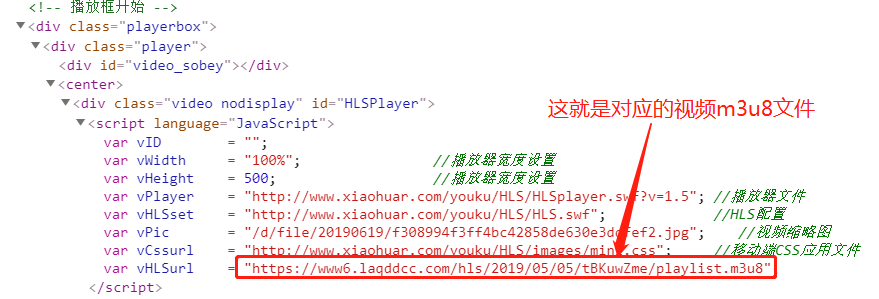
只需要将该链接打开就能获取对应的m3u8文件,下载之后我们看一下里面的内容:
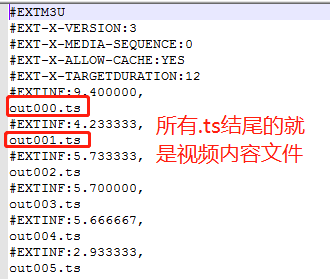
此时我们只需要将里面out000.ts等复制出来,逐个替换掉playlist.m3u8的路径就是对应的视频文件。比如https://www6.laqddcc.com/hls/2019/05/05/tBKuwZme/out000.ts,这用endswith和循环就能实现下载所有的m3u8视频。所有代码如下:
from requests_html import HTMLSession import os session = HTMLSession() # http://www.xiaohuar.com/list-3-0.html #获取索引页url def get_index_page(): for i in range(6): url = 'http://www.xiaohuar.com/list-3-%s.html'%i yield url #解析索引页获取详情页url def get_detail_page(url): r = session.get(url=url) for element in r.html.find('#images a[class="imglink"]'): yield element.attrs.get('href') #解析详情页获取视频url,名字 def get_url_name(url): r = session.get(url=url) r.html.encoding = "gbk" # 指定编码,可以使用document.charset获取 file_name = r.html.find('title',first=True).text.replace('\\','') # 替换掉\是防止文件路径拼接出错 print(file_name) element = r.html.find('#media source',first=True) if element: # video标签的视频 vurl = element.attrs.get('src') vtype = 'mp4' else: # m3u8格式视频,search相当于正则 vurl = r.html.search('var vHLSurl = "{}";')[0] vtype = 'm3u8' return file_name,vurl,vtype #保存文件 def save(file_name,vurl,vtype): if vtype == "mp4": file_name += ".mp4" r = session.get(url=vurl) with open(file_name,'wb') as f: f.write(r.content) elif vtype == "m3u8": save_m3u8(file_name,vurl) #处理m3u8 def save_m3u8(file_name,vurl): if not os.path.exists(file_name): os.mkdir(file_name) r = session.get(url=vurl) m3u8_path = os.path.join(file_name,'playlist.m3u8') with open(m3u8_path,'wb') as f: f.write(r.content) for line in r.text: if line.endswith('ts'): ts_url = vurl.replace('playlist.m3u8',line) ts_path = os.path.join(file_name,line) r0 = session.get(url=ts_url) with open(ts_path,'wb') as f: f.write(r0.content) # save_m3u8('xxx','https://www6.laqddcc.com/hls/2019/05/05/BRsIeDpx/playlist.m3u8') if __name__ == '__main__': for index_page in get_index_page(): for detail_url in get_detail_page(index_page): file_name, vurl, vtype = get_url_name(detail_url) save(file_name, vurl, vtype)
更多爬虫知识:https://www.cnblogs.com/kermitjam/p/10863846.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号