
FlowNet:simple / correlation 与 相关联操作
FlowNet : simple / correlation 与 相关联操作
上一篇文章中(还没来得及写),已经简单的讲解了光流是什么以及光流是如何求得的。同时介绍了几个光流领域的经典传统算法。
从这一章以后,我们从最经典的网络结构开始,介绍一些基于深度学习的光流预测算法。
1 简介
提到用深度学习做光流预测,大部分研究都绕不开这篇Flow Net文章,原因很简单,这个网络太经典了! (原文传送门)
在FlowNet横空出世之前,大部分光流预测模型使用的都是传统的手工计算方法,例如Lucas-Kanade,或者Epic Flow等等。尽管其中一些算法也可以实现稠密光流的预测,有些网络甚至还有着不错的算法识别效率,但这些基于手工学习的算法总有各种各样的缺陷,只能针对特殊的引用场景使用。当然更重要的一点是:ML, DL技术实在是大势所趋,于是到了2015年,作者大声喊道:"Let there be FlowNet!"。
FlowNet源于一个相当简单的思路:既然光流是一种针对两张图片见对应像素点的映射关系(F(x,y) = u,v),而同时,不少深度学习模型的本质就是提供了一种线性或者非线性的映射关系。那么能否通过深度学习来完成这种从图片到目标光流的映射,来实现光流预测呢?
这篇FlowNet1.0 证明了这种思路是可行的。
FlowNet 同时也是第一个利用CNN实现了光流预测的模型(至少作者是这么说的,hhhh),从这一点来讲,FlowNet就已经为现在的光流领域发展留下了不小的贡献。
当然Flow Net的贡献不止这些。这篇文章的另一点重大贡献在于提供了一种相关联操作,用于对不同特征值进行比较。Somehow,这种相联操作已经成为了当前不同研究中的基础(就像特征提取那样),因此学习它是十分有必要的。
发表于2015年的这篇Flow Net中提出了两个相似的模型用于实现光流的预测,分别为Flow Net Simple 和Flow Net Correlation。我们先对这两个模型有一个简单的overview:
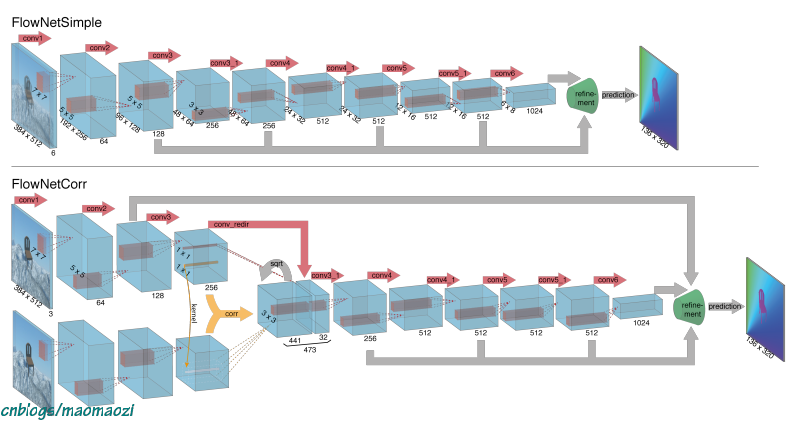
简单来讲,两个模型的后半部分网络结构比较相似,只是前半部分稍有区别,都经过了特征提取,再到输出光流图的过程。区别在于,FlowNetS把两张图片直接堆叠起来进行特征提取,而FlowNet corr稍微复杂一点,两张图片分别进行特征提取再通过了一个名为”correlation“的操作,下面展开描述一下两个网络的实现思路和细节。
2 Approaches & estimate
2.1 Flow net Simple
各位看官老爷可能已经感觉出来了,FlowNet S是一个相当原始粗暴的网络。前文已经提到,flow net 1.0企图利用CNN网络来拟合这种图片->光流的映射关系,因此设计者就用了一连串的卷积层来实现这种映射关系。(例如,1*1的卷积核本质上就是一种线性映射)
以任意两帧在时间上相邻的画面作为输入,模型会首先把这两张图片在channel上进行合并,重叠在一起,之后进入上如所描述的若干网络层。尽管不同网络层的设计目的不尽相同,但是其大致可以分为以下几个阶段:
首先,模型需要对输入的张量进行特征提取。特征提取是一个漫长的阶段,经过了多次的卷积层。在这个过程中图片尺寸逐渐缩小,最后变成一个1024channels 的tensor。下一步模型会有特征值向光流做映射,这一步是由一个简单的卷积层来实现的。最后,经过一个refinement模块,光流图片的分辨率会被恢复到合理的大小。
获取光流
从网络结构来看,不同卷积层的fliter是一个逐渐缩小的过程。这一点符合常识对模型结构的判断,也是很多模型会采取的设计方法(尽管在后续研究中已经证明多个33的卷积核足以替代7**7的卷积核)。先用一个大感受野fliter对输入图片进行early downsampling,之后逐渐缩小卷积核的大小,同时,通过控制卷积层的步长来不断的缩小分辨率。
用来实现特征--光流映射的部分反而相对简单,仅由一层out channel =2 的卷积层构成。
Refinement
在前一个部分中,模型利用卷积层实现了特征的提取与映射,得到了一个低分辨率版的光流信息。之所以是低分辨率,是因为前文中的网络调整了卷积核的步长、并进行了池化。因此很有必要在经过了这些网络结构之后,设计一个refinement 部分,将光流恢复至原图的分辨率大小。这一部分中主要应用到的是一种“反卷积”操作,还是看一下网络结构图:
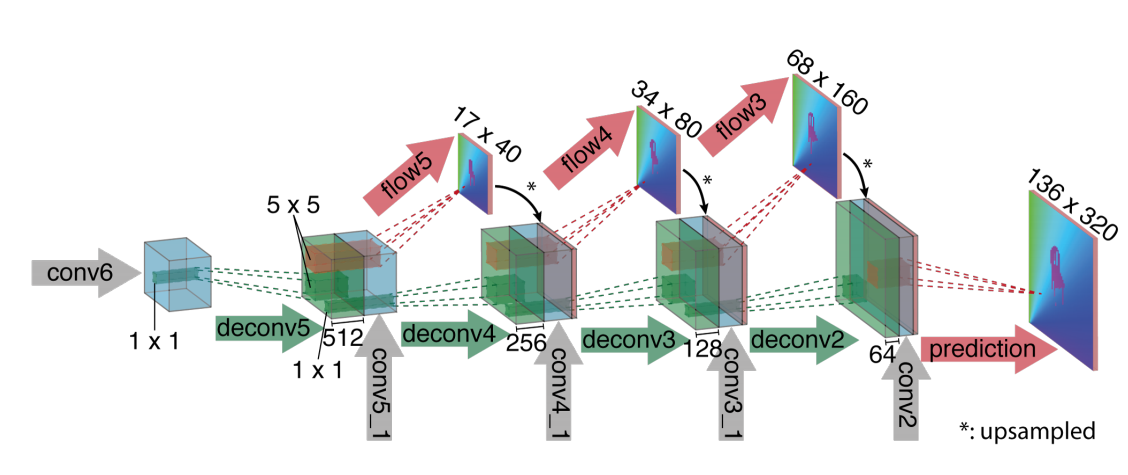
这种反卷积的思路FlowNet之前就已经提出了,如这篇文章 , 有兴趣的老哥可以深入了解一下,这里不再详细展开。简单来讲,反卷积就是一个unpooling + 一个卷积层。现在的pytorch都已经帮我们封装好了这一操作,直接调用 nn.ConvTranspose2d 就好了(就像调用nn.conv2d那样)。
重点在于为什么使用反卷积,而不是简单的上池化操作来还原分辨率。要知道,额外设计卷积层会增加很多参数,拖慢训练速度。个人觉得很重要一个原因在于单纯的上池化是不包含有效信息的。可以看一下下图:(图片摘自《Learning Deconvolution Network for Semantic Segmentation》)
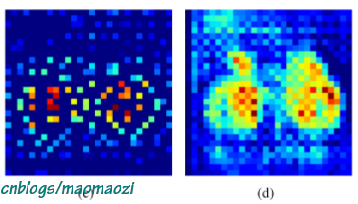
左图是简单的上池化结果,右图则是反卷积的结果。对于即将得出的稠密光流图来说,显然仅仅做到左图是不够的。这样子得到的图片即便对剩余的分辨率进行了填充,也不能够符合预期。因此这一步额外的卷积操作是必要的。虽然如此,但从训练结果来看这部卷积操作并不会对光流的整体预测效果产生巨大影响,因此被称作“refinement”。
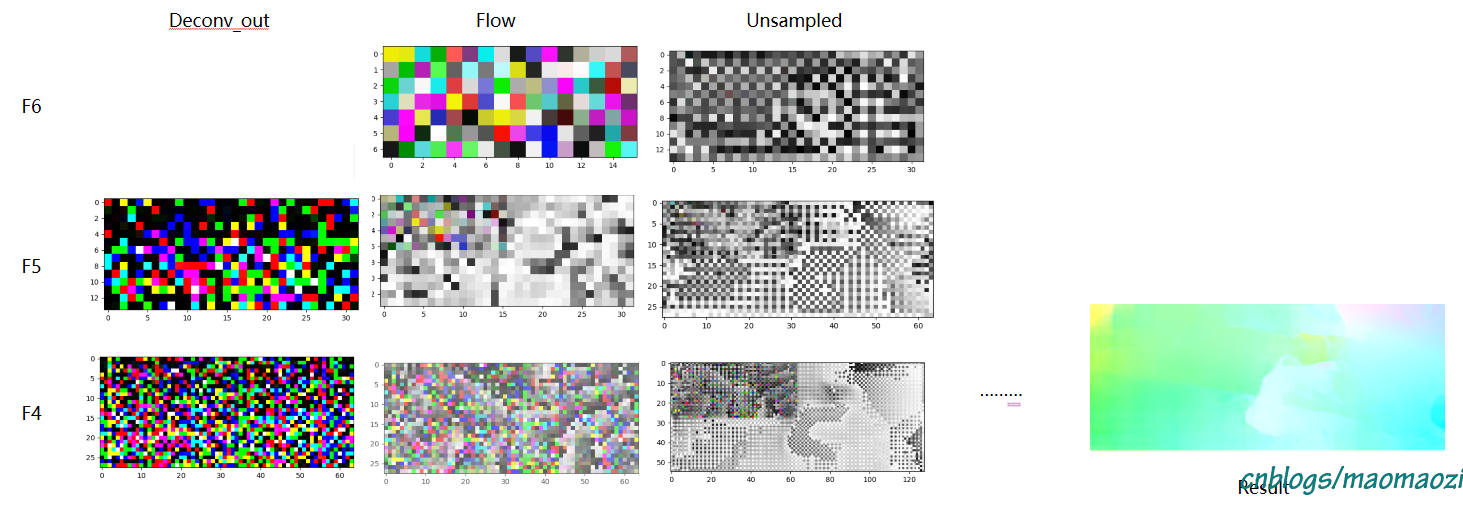
(上图是我用sintel数据集跑的结果。可以看到整个反卷积中分辨率逐渐扩大的过程)
想法虽然简单易懂,但是这个模型的缺点同样十分明显。
首先,模型的计算量很大。这一点稍加判断即可得知:在模型的中间设计了很多512in&&512out的卷积层。尽管卷积核大小为3,这些层次结构所带来的需要迭代的参数和计算量也是巨大的。
同时,网络不同位置的收敛速度不一样。由于其思路非常简单,把很多工作都交给了反向传播算法来完成。模型往往只能达到局部参数最优点,整个网络则很难达到一个平衡。
2.2 Flow net correlation
针对上面提出的种种问题,原文作者在同一篇文章中提出了另一种替代性的模型:FlowNet Corr。表面上这一模型的并没有对模型结构带来很大的改动,但实际上却成了FlowNet最重要的贡献之一。
特征提取&光流生成
同样先对这个模型给出一个简单的overview。两个模型最直观的区别在于,对Corr来讲,模型的特征提取是先分开进行之后再合并的。模型将分别对Img1和Img2进行特征提取(虽然使用了同样的网络结构,但区别于现在channel上合并再做卷积,FlowNet Corr中选择分别对两个图片做两次相应操作),之后利用一步名为“”correlation“的操作对两个图片中的特征值进行合并激活,最后再经历卷积、反卷积的过程,输出光流结果。
Correlation : 相关联操作
在模型到达相关联层之前,已经得到了两张256channel的特征图,分别对应Img1和Img2。这时需要一种操作能够比对并激活两张特征图中相关联的向量,这步操作就是correlation。
毫无疑问,Correlation操作是整个Flow Net Corr最为重要的一步。听起来很炫酷,但这一步操作本质上就是一步卷积运算而已。只不过相比CNN中使用特定的卷积核进行卷积,这里使用一个数据对另外一个数据做卷积操作。
为什么使用两个feature map 卷积就可以得到相关联的向量?我觉得在这方面有一个比较接近的例子,各位读者可以看看这里,也许可以获得一些提示。下面给出相关联操作的数学定义:
对于两张特征图f1,f2上的两个patch来讲,这两个patch在x1,x2处的相关联值可以表示为:
其中,对应的patch为一个边长为2K+1大小的正方形。
通过这样的计算,模型确实可以比较两张特征图之间的全部像素点,使相对应的部分的到激活。但问题在于,这样的计算量是巨大的。在前一篇博客中,我们提到过计算光流时所面临的计算量过大问题。提出新的模型,理论上需要减少计算量,而不是增加计算量。然而, 在上面这个相关联计算中,计算一对patchc(x1, x2)需要进行$$ c*K^2 $$次的乘法运算,而计算两张图片的所有相关联值就至少需要$$ (w^2) * (h^2) $$次的乘法运算,这显然是不合理的。
因此,作者引入了一条新的假设来解决这一问题。这里引入假设的思路其实和传统的、手工设计的模型思路很相似。作者假设对应像素点的位移只存在于一个固定的范围内。这样在真正计算相关联信息时,模型只需要维持一个固定大小的查找窗,超出这个查找窗范围之外的东西便不予考虑了。
假设这个最大位移为d,通过限制x2的出现范围,相关联操作c(x1, x2)只会在 D=2d+1的领域内进行计算。 同时,模型还可以使用步长来进一步减少计算量。这一计算的最终结果是4维的(w*h*D^2)(这里注意是D而不是d!通常这个位移限制为d=4,因此相关联向量是w*h*81大小的),因此也经常被后续的论文称为4D相关联向量。
另外需要说明的一点是,这一部分操作是不包含可训练参数的,因此不会对模型的训练和收敛速度产生非常大的影响。
refinement
refinement这一部分的结构和FlowNet S 是一样的,因此这里不再展开。
2.3 estimate
下面简单看一下模型在不同数据集下的表现。(源于论文)
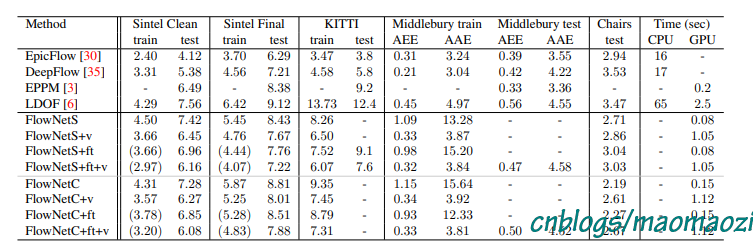
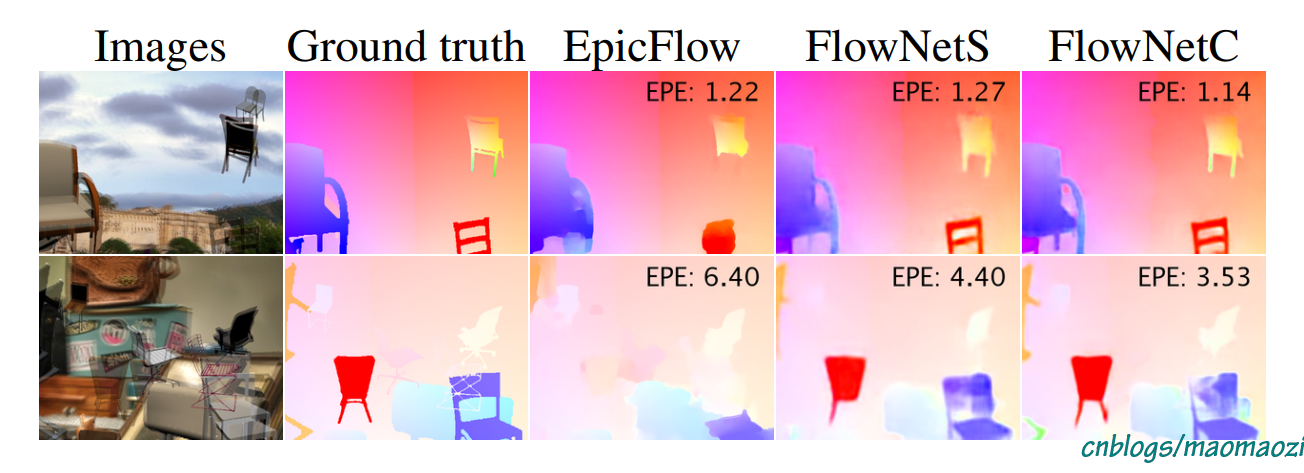
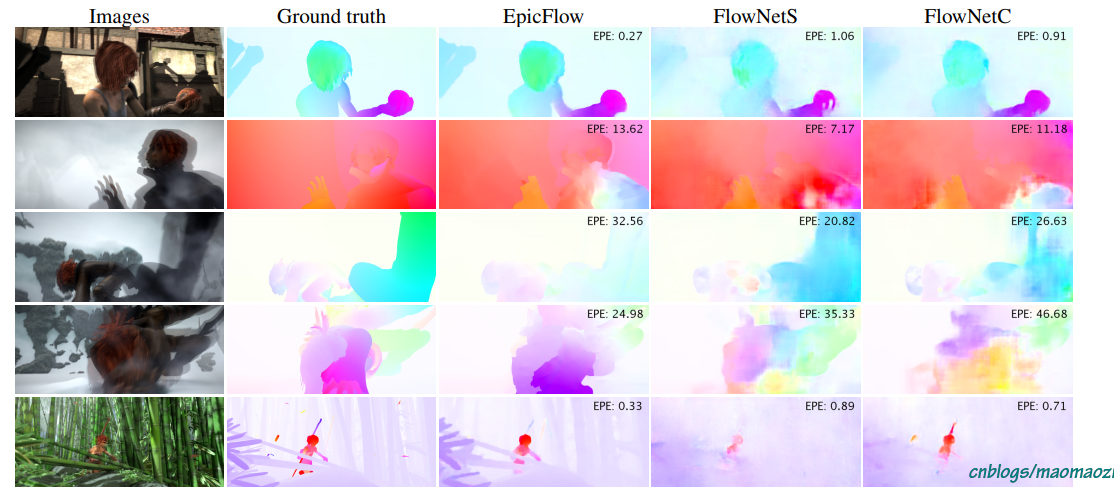
上图是FlowNet与EpicFlow 在Sintel 数据集与Flying Chairs数据集下的结果对比结果(注意Images 中的重影是因为两帧图片叠在了一起)。尽管FlowNet 的end point error 不一定完全吊打早期模型,可以还是有一些优点:首先,对于小而快速的运动物体,FlowNet有着更好的识别效果;其次,虽然epe不够,但是模型的细节保留的更好(尽管我觉得作者有自吹自擂的嫌疑,哈哈哈哈)
3 模型结论与启发
作为第一篇基于CNN的光流预测模型,FlowNet很出色的完成了自己的任务。尽管在Epe等数据上并没有完全的压制其它模型,但FlowNet确实提供了一种很优秀的思路,即:利用correlation 这一操作对相似的图片特征进行激活, 并利用卷积网络实现特征-->光流的映射。在领域内后续的一些论文中,很多都使用了相关联这一操作,甚至继承了大小为9的这一查找窗大小。因此理解FlowNet显然是对后续学习至关重要的。
FlowNet同样暴露出了基于深度神经网络实现光流预测这一方法中的几个关键问题:1,图片模糊、抖动、遮挡情况下的识别问题(同样是cv领域大部分算法的共性问题);2,高速运动物体的识别问题。在FlowNet中,模型设计了一个大小为9*9的查找窗,以限定对应像素点的移动范围。然而当物体移动方向超过这一部分之后,模型便不再能够提出有效的解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号