
一、要解决的场景与分页导致的问题
场景:(1)排行榜(按分数 或 点赞数 倒排序),文章列表(按 点赞数,评论数,热度 倒排序) 分页查询的场景
(2)分页查询中,like效率低的场景
特点:访问量相对较高,数据量动态变化,排序动态变化(即便数据量不变,比如点赞数变化也会导致排序变化), 一般通过滑动自动加载下一页,不需要知道总的数据量。
分页导致的问题:
现在服务端为了方便分页,一般使用pageHelper组件:
Page<PlayRecordBaseExtendVO> page = new Page<>(playRecordPageDTO.getCurrent(), playRecordPageDTO.getSize());
IPage<PlayRecordBaseExtendVO> pageList = this.baseMapper.getPlayRecordBaseExtendByPage(page, playRecordPageDTO);
执行的sql 类似:
select col1,col2,col3.... from tableName where col1 = 'xx' and col2 like '%xx%' order by col1,col2
pageHelper帮助程序员实现分页(总记录数,页数,每页的记录数)。
问题:(1)pageHelper内部两次查询数据库,一次是查数据总量,用于计算页数,一次是limit分页,查询当前页记录数,在不需要知道数据量的场景中,查询数据总是是多余的。
解决方式:
Page<PlayRecordBaseExtendVO> page = new Page<>(playRecordPageDTO.getCurrent(), playRecordPageDTO.getSize(),Boolean.FALSE);
(2)在数据总量短时间内变化不大,分页要求不高的情况下,这样开发没问题,但数据量变化频繁的情况下,会有如下问题:
查询不同的页,可能出现同一条数据在不同页; 在连续的两次查询同一页,可能出现同一页的数据不一样。
(3) like效率本来就低, 再加上排序 ,性能会更低。
二、简单优化
where 条件 和 order by 字段 添加 组合索引。
优化时注意两种情况:
先看一个例子:
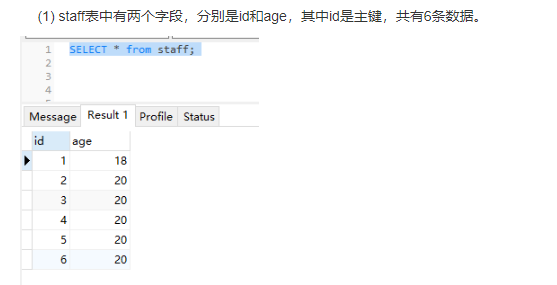
(1) staff表中有两个字段,分别是id和age,其中id是主键,共有6条数据。
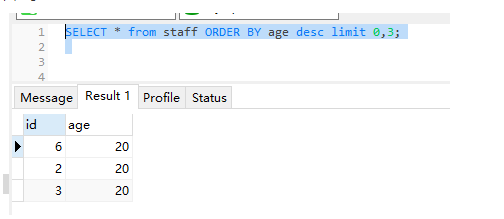
(2) age倒序,查询第一页
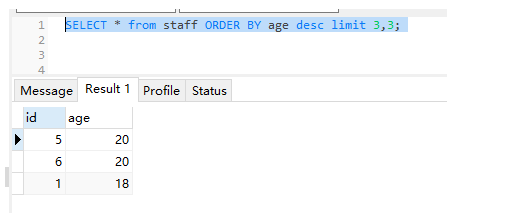
(3)age倒序,查询第二页
(4)age倒序,查询第三页:
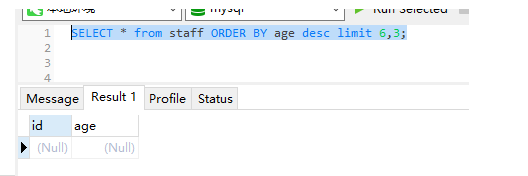
发现查询的数据有问题没??? 啥原因???如何解决???
id=6的这条数据出现在 第一页和 第二页上。 这是数据库内部排序算法造成的, 只需要order by age desc,id desc 就行了, age相同再根据id排序一次。
注意事项:order by 多个字段时, 要么都降序, 要么都升序, 否则索引利用不全。
另外一个例子, like ‘%xx%’ 一定不走索引吗?

三、优化查询
参考:https://dandelioncloud.cn/article/details/1473227573223317506
https://blog.csdn.net/weixin_39690625/article/details/113229887
https://blog.csdn.net/dianzizhongds1302/article/details/105616314/
(1)instr函数
INSTR(STR,SUBSTR) 在一个字符串(STR)中搜索指定的字符(SUBSTR),返回发现指定的字符的位置(INDEX);
STR 被搜索的字符串
SUBSTR 希望搜索的字符串
例子:select id,title from play_record_base_extend_audit WHERE activity_id=7430 and instr(title,'cccc') limit 100,10;
结论:性能提升不明显。
(2) 模糊查询字段加普通索引, 先子查询(select id from xx where xx like ‘%xx%’and id > xx limit 1000) 取id 列表,然后再根据id列表查需要的字段。
适合表比较大,一条记录字段比较多,like字段不太长(比如nickName,title)的情况。
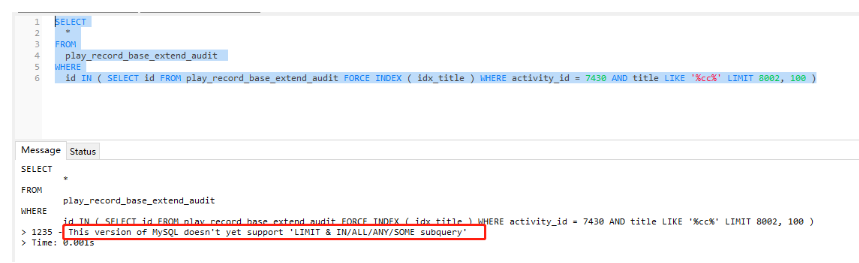
explain
SELECT * from play_record_base_extend_audit WHERE id in
(
SELECT id from
(
SELECT id from play_record_base_extend_audit force index(idx_title) WHERE activity_id=7430 and title like '%cc%' limit 8002,100
)as t
)
加中间表的原因:
下面这个性能可能更高点:
explain
SELECT * from play_record_base_extend_audit
INNER JOIN
(
SELECT id from play_record_base_extend_audit force index(idx_title) WHERE activity_id=7430 and title like '%cc%' limit 8000,100
)as t on play_record_base_extend_audit.id=t.id
(3) 模糊查询加全文索引
mysql 默认全文索引的最小单词是四个字符,可以通过ft_min_word_len设置,重建索引,全文索引查的是单词,像这样的dddkkkl通过全文索引也是查不到的。
全文索引,InnoDB也支持全文索引。
like与全文索引对比:
select * from play_record_base_extend_audit WHERE activity_id=7430 and title like '%thepaper%' limit 0,100

select * from play_record_base_extend_audit WHERE activity_id=7430 and match(title) against('thepaper') limit 0,100
通过子查询,like与全文索引对比:
SELECT * from play_record_base_extend_audit
INNER JOIN
(
SELECT id from play_record_base_extend_audit force index(idx_title) WHERE activity_id=7430 and title like '%thepaper%' limit 0,100
)as t on play_record_base_extend_audit.id=t.id;

SELECT * from play_record_base_extend_audit
INNER JOIN
(
SELECT id from play_record_base_extend_audit force index(idx_title) WHERE activity_id=7430 and match(title) against('thepaper') limit 0,100
)as t on play_record_base_extend_audit.id=t.id;
(4) 用ES,solor等搜索引擎。(略)
延伸一个问题: 排行 通用使用redis zset 排名, 但分页比较麻烦, 如何实现分页呢?
数据库中添加分数字段, 分页时使用分数字段分页排名。
四、数据总量变化速度快的情况
(1) 一次性取出所有数据
只适用于本身数据量不多 或 展示的数据量不多的场景, 比如 排行榜只展示前100名。
(2) 查询数据库中最大的记录id, 后续只在<=次id内查询
其实就是以用户第一次查询时间为节点,后续数据库新增的记录舍弃。
只要用户不是重新从第一页查询,则每次都要带着此id到后端。
(3) 写一个定时脚本,每5分钟生成一次快照, 查询时只查快照内的数据
接口请求时直接从快照中取数据,这一定程度上解决了列表排序一直在变化问题。这里之所以说只解决了一定程度,是因为在每次刷新快照数据的时候,
可能有用户刚好卡在这个时间点之间去请求(刷新快照前用户请求了第一页数据,刷新快照后用户请求第二页,这就出现传统分页同样的 问题了)。
可以通过在快照中加上 版本号 来解决问题。例如在生成快照的时候以当前时间戳作为版本号跟快照数据一起保存,同时需要系统保存多份快照数据以便用户获取旧快照数据。
请求接口时默认拿最新版本的快照,如果接口传入了版本号就拿对应版本号的快照数据。
优点:
- 通俗易懂,传参方式跟 传统分页 类似。
- 请求处理效率高,生成快照时可以把数据进行处理再保存(例如日期格式转换、类型key值转类型名字等),使得请求到来时获取的数据可以直接返回给用户,无需再做处理。
- 易于测试和排查,在生成快照那一刻已经决定了整个列表的数据展示,测试和错误排查很方便。
缺点:
- 实时性比较差,用户拿到的数据不是最新的。
- 需要额外存储空间,需要额外的地方存储多个版本的快照数据。
- 需要定时器,对于本来存在定时器的系统架构,这一点不算缺点。
(4)通过变动记录表查询数据
记录变记录着数据每次变动前后的变化和变动时间,这一特性为使得数据的每次变动都有迹可循。
前端需要记录发起第一次请求时的时间,以后每页的请求都带着这个时间。
优点:
- 无需额外存储数据,利用系统原有数据结构来解决数据变动问题,也无需做多版本控制。
- 数据相对实时,每次拿到的排行榜数据都是请求第一页那一刻最新的数据。
缺点:
- 效率相对较差,由于数据需要实时排序和获取,效率相比排行榜要低。而且上面例子只取了记录表中最基础的数据,实际需求中一般需要关联更多的表去取信息,所以效率将随着需求负责度增大而降低。
- 只适用于用户量不大的情况,由于数据变动记录表的数据量随着用户量的递增是呈倍数递增的,所以用户量达到一定程度的情况下,这个方式效率会变得相当低。
(5) 分页的数据加缓存
缓解了数据变动,但没有从根本上解决问题。
五、分页如何应对高并发
加redis缓存 或 本地缓存
缺点:
对搜索类加缓存 作用不大。
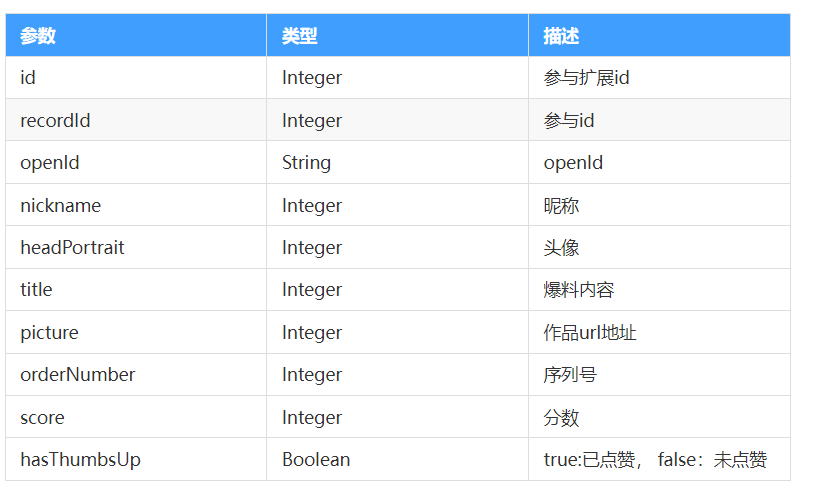
注意事项: 对于请求的用户,缓存的数据,有些字段是需要实时更新的,比如下面的score(记录的点赞分数),hasThumbsUp(查询人是否已点赞)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号