参考:
http://blog.yoqi.me/wp/2580.html
https://blog.csdn.net/weixin_42345229/article/details/98217488
https://www.csdn.net/tags/MtTaEgzsMTk4MzA3LWJsb2cO0O0O.html
https://blog.csdn.net/u014756380/article/details/103014151
https://www.cnblogs.com/jhxxb/p/11558300.html
问题记录:
1、flume字符转换异常问题,java.nio.charset.MalformedInputException: Input length = 1,可以在配置文件中增加如下配置项解决:
a1.sources.r1.inputCharset = ISO8859-1
备注:网上很多说是改为GBK, 但是我在win10环境建的文件不行,改为ISO8859-1就行了。
2、报这个错:
FLUME
com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
原因是:hadoop 与flume jar包冲突。
解决方式:https://blog.csdn.net/walykyy/article/details/111911947
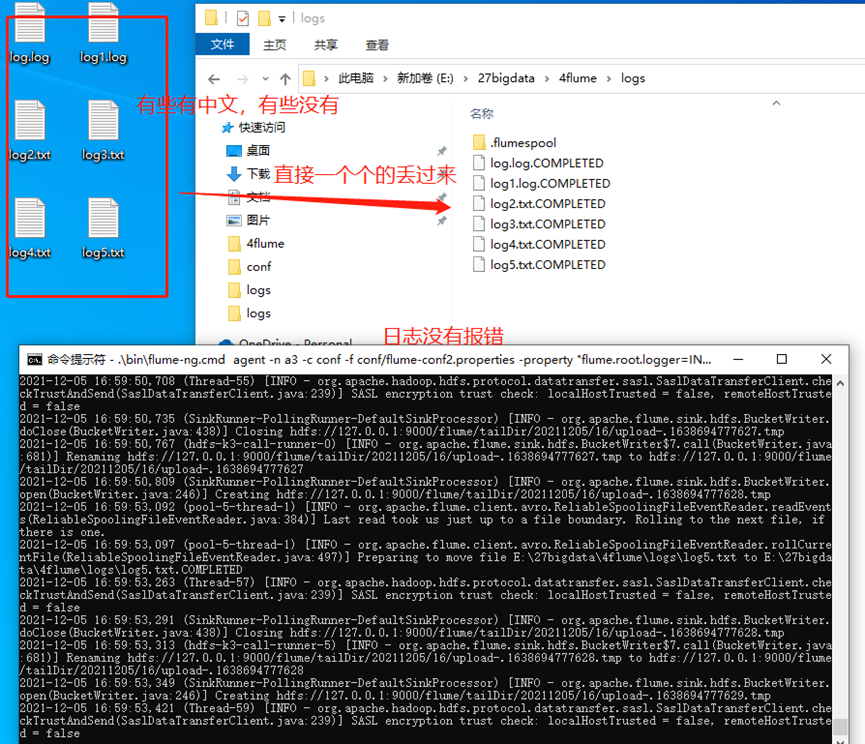
3、win10环境配置source 的类型为TAILDIR 会报错, 了解后可能是源码在win10下有bug, 最后改为spooldir。
开始前,安装flume1.9.0:https://www.cnblogs.com/maohuidong/p/15623855.html
开始:
1、编写flume-conf2.properties
内容:
a3.sources=s1
a3.channels=c1
a3.sinks=k3
# 以下四行,window不支持,TAILDIR,源码在window下有bug,报的错解决不了,所以放弃了。
#a3.sources.s1.type=TAILDIR
#a3.sources.s1.positionFile=E://27bigdata/4flume/taildir_position.json
#a3.sources.s1.filegroups=f1
#a3.sources.s1.filegroups.f1=E://27bigdata/4flume/sogou.log
a3.sources.s1.type=spooldir
a3.sources.s1.spoolDir=E://27bigdata/4flume/logs
a3.sources.s1.fileHeader = true
a3.sources.s1.inputCharset = ISO8859-1
a3.sources.s1.ignorePattern= ^(.)*\\.tmp$
#监控目录及子目录
#a3.sources.s1.recursiveDirectorySearch=true
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://127.0.0.1:9000/flume/tailDir/%Y%m%d/%H
# 上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
# 是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
# 多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
# 重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = minute
# 是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
# 积攒多少个 Event 才 flush 到 HDFS 一次,可以设置为100
a3.sinks.k3.hdfs.batchSize = 5
# 设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
# 多久生成一个新的文件,可以设置为60
a3.sinks.k3.hdfs.rollInterval = 6
# 设置每个文件的滚动大小大概是 128M(值为134217700)
a3.sinks.k3.hdfs.rollSize = 2
# 文件的滚动与 Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
a3.channels.c1.checkpointDir=E://flume-test//checkpoint
a3.channels.c1.dataDirs=E://flume-test//data
# Bind the source and sink to the channel
a3.sources.s1.channels = c1
a3.sinks.k3.channel = c1
2、启动hadoop:
启动后,我执行了以下两个命令: hadoop dfsadmin -safemode leave ; hadoop fs -chmod -R 777;
3、启动flume:
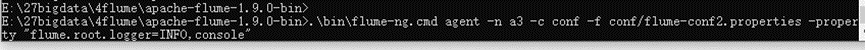
.\bin\flume-ng.cmd agent -n a3 -c
conf -f conf/flume-conf2.properties -property
"flume.root.logger=INFO,console"
看到source,channel,sink有启动成功的标识才算成功, 否则有可能是配置不对,监控不到的原因。
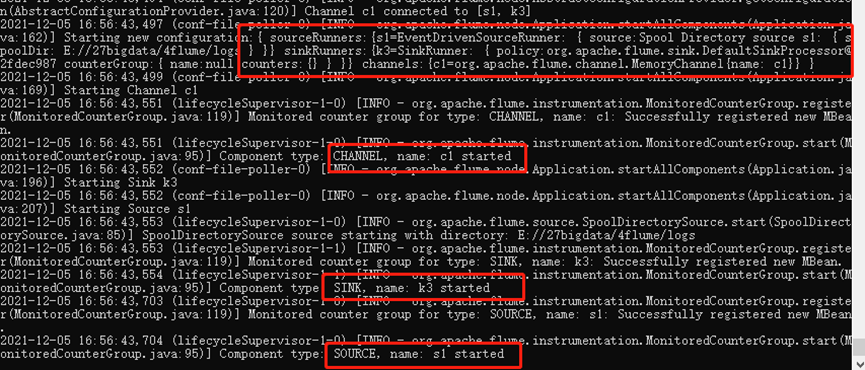
4、测试是否可以输出到hdfs: