python爬虫-乱码问题终极解答
我们辛辛苦苦编写的爬虫程序终于爬到了内容,但内容却是乱码,有没有一种准备了一顿丰盛的午餐的原料,但是做出来的饭却非常的难吃的感觉。这怪谁?当然怪厨师啦!
本文将以python爬虫为例,解决乱码问题,经过笔者实测,只要通过浏览器正常访问正常的网站,95%以上的网站都可以获得能正常阅读的格式
乱码是因为没有设置网站编码的格式或者设置了错误的编码。但是如何去设置正确的编码呢
resp = requests.get('http://www.baidu.com',headers=headers,timeout=10)
resp.encoding='utf-8'
一般我们通过指定特定的编码格式,比如’utf-8‘,但现在并不是所有的网站都是utf-8,那么我们每次写爬虫都要去替换相对应的网站编码,这样非常麻烦。
那我们如何去自动获取正确的编码呢
首先了解一下有几种获取编码的方式
1、直接打印resp.encoding
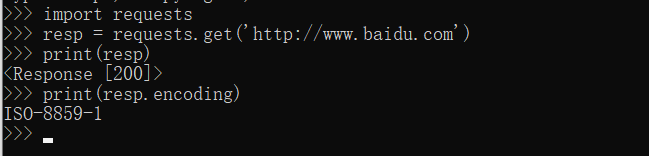
但是这个编码感觉不太对,经过多次试验发现,部分网站获取的是正常的。一般编码为utf-8,gkb,gb2312(不区分大小写)或其它常见的编码我们就认为获取了正确的编码
2、打印apparent_encoding
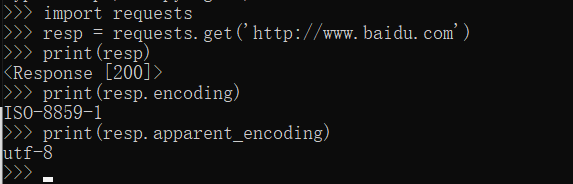
utf-8应该是网站的正确编码了,但有时会出现'UTF-8-SIG'和'ascii'这两种编码,多次试验发现'UTF-8-SIG'可以认定为utf-8,但显示'ascii'的一般还需要继续研究
3、如果网页里写了charset的属性,则可以通过提取网页中设置的编码直接设置为网页编码,一般英文不会乱码,所以只要写了charset的基本都可以提取
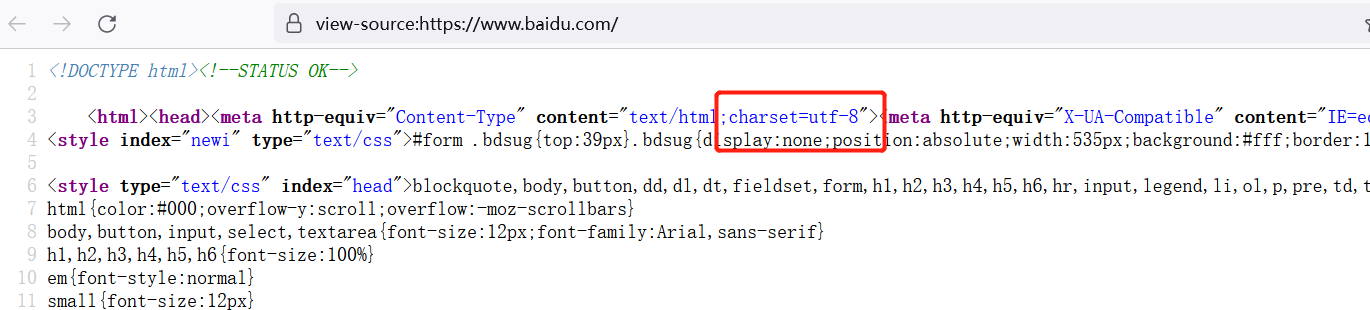
从网页里提取charset方式很多,我这介绍两种。
一种是通过正则提取,一种是通过python中写好的功能模块提取
正则提取
obj1 = re.compile(r'charset=[\S]*?([a-zA-Z0-9_-]*)\S',re.S|re.I)
result1 = obj1.search(resp.text)
encode = result1.group(1).strip('"').strip("'").strip('\\')
功能模块提取
from lxml import etree
html =etree.HTML(resp.text)
charset_x = html.xpath('//meta/@charset')#获取meta节点下的charset属性
多次试验发现通过网页中提取charset的方法获取正确编码存在以下问题:
(1)部分网页中不存在charset设置,所以无法通过正则和模块获取编码
(2)网页中存在多个charset类型,脚本本身无法确定正确编码是哪一个
(3)匹配到了网页中的编码,但依旧乱码
综上所述,结合实际经验,现给出python脚本(代码无关美丑,能用就行,解决你99%的问题)

def getCharset(z):#传入url
encode = ''#存储最终的编码
encode1 = ''#
encode2 = ''
try:
resp = requests.get(z,headers=headers,timeout=10)
if resp.status_code == 200:
if resp.text != '':
encode1 = resp.apparent_encoding
encode2 = resp.encoding
if encode == '':
if encode1 == 'UTF-8-SIG':
encode = 'utf-8'
elif encode1 == 'ascii':
encode = ''
else:
encode =encode1
if encode == '':
if encode2 != '':
if encode2 != 'ISO-8859-1':
encode = encode2
if encode == '':
if encode2 == 'ISO-8859-1':
html =etree.HTML(resp.text)
charset_x = html.xpath('//meta/@charset')#获取meta节点下的charset属性
if charset_x != []:
encode = charset_x[0]
if charset_x == []:
try:
result1 = obj1.search(resp.text)
encode = result1.group(1).strip('"').strip("'").strip('\\')
except AttributeError:
print(z+"\t编码匹配错误!")
except Exception as e:
print(z+"\t出错原因1:",e)
if encode == '':#无能为力,只能盲猜GBK
if 'utf-8' in resp.text or 'UTF-8' in resp.text:
encode ='utf-8'
if 'gbk' in resp.text or 'GBK' in resp.text or 'gb2312' in resp.text or 'GB2312' in resp.text:
encode = 'gbk'
if encode == '':
encode = 'utf-8'
encode = encode
except ReadTimeout:
print(z+'\t异常:ReadTimeout')
except HTTPError:
print(z+'\t异常:HTTPError')
except RequestException:
print(z+'\t异常:RequestException')
return encode
如果有问题请提醒


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具