
1 线程基础
1.1 线程状态
线程有5种状态,状态转换的过程如下图所示:

1.2 线程同步——锁
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样,其实Python中是伪多线程)。但是当线程需要共享数据时,可能存在数据不同步的问题。考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态—锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。经过这样的处理,打印列表时要么全部输出0, 要么全部输出1,不会再出现一半0一半1的尴尬场面。
线程与锁的交互如下图所示:
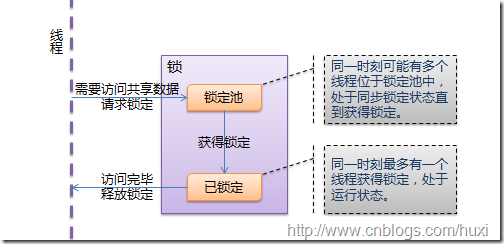
1.3 线程通信(条件变量)
然而还有另外一种尴尬的情况:列表并不是一开始就有的;而是通过线程"create"创建 的。如果"set"或者"print" 在"create"还没有运行的时候就访问列表,将会出现一个异常。使用锁可以解决这个问题,但是"set"和"print"将需要一个无限循环——他们不知道"create"什么时候会运行,让"create"在运行后通知"set"和"print"显然是一个更好的解决方案。于是,引入了条件变量。
条件变量允许线程比如"set"和"print"在条件不满足的时候(列表为None时)等待,等到条件满足的时候(列表已经创建)发出一个通知,告诉"set" 和"print"条件已经有了,你们该起床干活了;然后"set"和"print"才继续运行。
线程与条件变量的交互如下图所示:


1.4 线程运行和阻塞的状态转换
最后看看线程运行和阻塞状态的转换。

阻塞有三种情况:
同步阻塞是指处于竞争锁定的状态,线程请求锁定时将进入这个状态,一旦成功获得锁定又恢复到运行状态;
等待阻塞是指等待其他线程通知的状态,线程获得条件锁定后,调用“等待”将进入这个状态,一旦其他线程发出通知,线程将进入同步阻塞状态,再次竞争条件锁定;
而其他阻塞是指调用time.sleep()、anotherthread.join()或等待IO时的阻塞,这个状态下线程不会释放已获得的锁定。
2 多线程
为充分利用cpu资源,减少资源浪费,Python中也提供了多线程技术,但由于存在GIL的关系,实际上同一时刻只存在一个线程在执行,即Python中不存在真正意义上的多线程,但是多线程技术还是提高了CPU资源的利用率,所以还是很有价值的。
3 线程池
我们知道系统处理任务时,需要为每个请求创建和销毁对象。当有大量并发任务需要处理时,再使用传统的多线程就会造成大量的资源创建销毁导致服务器效率的下降。这时候,线程池就派上用场了。线程池技术为线程创建、销毁的开销问题和系统资源不足问题提供了很好的解决方案。
3.1 优点:
(1)可以控制产生线程的数量。通过预先创建一定数量的工作线程并限制其数量,控制线程对象的内存消耗。
(2)降低系统开销和资源消耗。通过对多个请求重用线程,线程创建、销毁的开销被分摊到了多个请求上。另外通过限制线程数量,降低虚拟机在垃圾回收方面的开销。
(3)提高系统响应速度。线程事先已被创建,请求到达时可直接进行处理,消除了因线程创建所带来的延迟,另外多个线程可并发处理。
“池”的概念使得人们可以定制一定量的资源,然后对这些资源进行复用,而不是频繁的创建和销毁。
3.2 注意事项
虽然线程池是构建多线程应用程序的强大机制,但使用它并不是没有风险的。在使用线程池时需注意线程池大小与性能的关系,注意并发风险、死锁、资源不足和线程泄漏等问题。
1、线程池大小。多线程应用并非线程越多越好,需要根据系统运行的软硬件环境以及应用本身的特点决定线程池的大小。一般来说,如果代码结构合理的话,线程数目与CPU 数量相适合即可。如果线程运行时可能出现阻塞现象,可相应增加池的大小;如有必要可采用自适应算法来动态调整线程池的大小,以提高CPU 的有效利用率和系统的整体性能。
2、并发错误。多线程应用要特别注意并发错误,要从逻辑上保证程序的正确性,注意避免死锁现象的发生。
3、线程泄漏。这是线程池应用中一个严重的问题,当任务执行完毕而线程没能返回池中就会发生线程泄漏现象。
3.3 线程池设计的关键点
1、取任务数与线程数的最小值来决定开启线程的数量,即min(任务数,线程数);
2、当前线程池中线程的状态,即正在运行的线程数量和正在等待的线程数量;
3、关闭线程。


1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import Queue 5 import threading 6 import time 7 8 ''' 9 要点: 10 1、利用Queue队列特性,将创建的线程对象放入队列中; 11 2、当执行任务时,从queue队列中取线程执行任务; 12 3、当任务执行完毕后,线程放回线程池 13 ''' 14 15 #线程池类 16 class ThreadPool(object): 17 def __init__(self,max_thread=20): #默认最大线程数为20 18 self.queue = Queue.Queue(max_thread) #创建队列,大小为max_thread 19 #把线程对象(线程类名)加入到队列中,此时并没有创建线程对象,只占用很小内存 20 for i in xrange(max_thread): 21 self.queue.put(threading.Thread) #注意此处是类名,如果这里self.queue.put(threading.Thread())(即把创建的对象放入队列中),那么每次都要在内存中开辟空间,这样内存浪费很大 22 23 24 def get_thread(self):#从队列里获取线程 25 return self.queue.get() 26 27 def add_thread(self):#在队列里添加线程 28 self.queue.put(threading.Thread) #注意此处是类名 29 30 pool = ThreadPool(10) #创建大小为10的线程池 31 32 #任务函数 33 def func(arg,p): 34 print arg 35 time.sleep(2) 36 p.add_thread() #当前线程执行完,在队列里增加一个线程 37 38 for i in xrange(300): 39 #获取队列中的线程对象(此时线程对象还没创建),默认queue.get(),如果队列里没有线程就会阻塞等待。 40 thread = pool.get_thread() 41 t = thread(target=func,args=(i,pool)) #此时才真正创建线程对象,并传递参数 42 t.start() #开启线程 43 44 ''' 45 for i in xrange(300): 46 thread = pool.get_thread() 47 t = thread(target=func,args=(i,pool)) 48 t.start() 49 在threading.Thread的构造函数中:self.__args = args self.__target = target 50 51 #当然也可以通过下面方法赋值,但是不推荐(对于私有字段,一般建议在构造函数中传参赋值) 52 for i in xrange(300): 53 ret = pool.get_thread() 54 ret._Thread__target = func 55 ret._Thread__args = (i,pool) 56 ret.start() 57 '''
3.4 复杂线程池预备知识
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import Queue 5 6 obj = object() #先创建一个object对象obj 7 q = Queue.Queue() #创建队列 8 9 #把obj对象放入队列,注意此处与上述例子中的区别,上例是每次都创建对象,那么每个对象都会占用内存; 10 #而此处是先创建对象,再把此对象加入队列,即对象只创建了1次,而队列中加入了10次,那么对象只会占用一份内存 11 for i in range(10): 12 q.put(obj) 13 14 for i in range(10): 15 print id(q.get()) #实验结果是此处id完全相同
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 import contextlib 5 import threading 6 import time 7 import random 8 9 doing = [] #线程列表 10 11 #打印正在运行的线程个数函数 12 def num(l2): 13 while True: 14 print len(l2) 15 time.sleep(1) 16 17 #单独创建一个线程,用于打印当前正在运行的线程数量 18 t = threading.Thread(target=num,args=(doing,)) 19 t.start() 20 21 #管理上下文的装饰器 22 @contextlib.contextmanager 23 def show(l1,item): 24 l1.append(item) #把正在执行的当前线程加入列表 25 yield #运行到此处,程序就会跳出当前函数,去执行with关键字中的内容,执行完后在进入当前函数执行 26 l1.remove(item) #当前线程执行完成后,则从列表中移除 27 28 #任务函数 29 def task(i): 30 flag = threading.current_thread() 31 with show(doing,flag): #with管理上下文,进行切换 32 print len(doing) 33 time.sleep(random.randint(1,4)) #等待 34 35 for i in range(20): #创建20个线程 36 temp = threading.Thread(target=task,args=(i,)) 37 temp.start()
更多with上下文管理知识请参考:
http://www.cnblogs.com/alan-babyblog/p/5153343.html
http://www.cnblogs.com/alan-babyblog/p/5153386.html
3.5 twisted源码中经典线程池的实现
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 from Queue import Queue 5 import contextlib 6 import threading 7 8 WorkerStop = object() 9 10 class ThreadPool: 11 workers = 0 12 threadFactory = threading.Thread #类名 13 currentThread = staticmethod(threading.currentThread) #静态方法 14 15 def __init__(self, maxthreads=20, name=None): 16 self.q = Queue(0) #创建队列,参数0表示队列大小不限,队列用于存放任务 17 self.max = maxthreads #定义最大线程数 18 self.name = name 19 self.waiters = [] #存放等待线程的列表 20 self.working = [] #存放工作线程的列表 21 22 def start(self): 23 needSize = self.q.qsize() #获取任务所需的线程数 24 while self.workers < min(self.max, needSize): #wokers初始值为0 25 self.startAWorker() #调用开启线程的方法 26 27 def startAWorker(self): 28 self.workers += 1 #workers自增1 29 newThread = self.threadFactory(target=self._worker, name='test') #创建1个线程并去执行_worker方法 30 newThread.start() 31 32 def callInThread(self, func, *args, **kw): 33 self.callInThreadWithCallback(None, func, *args, **kw) 34 35 def callInThreadWithCallback(self, onResult, func, *args, **kw): 36 o = (func, args, kw, onResult) #把参数组合成元组 37 self.q.put(o) #把任务加入队列 38 39 #上下文管理装饰器 40 @contextlib.contextmanager 41 def _workerState(self, stateList, workerThread): 42 stateList.append(workerThread) #把当前执行线程加入线程状态类表stateList 43 try: 44 yield 45 finally: 46 stateList.remove(workerThread) #执行完后移除 47 48 def _worker(self): 49 ct = self.currentThread() #获取当前线程id 50 o = self.q.get() #队列中获取执行任务 51 52 while o is not WorkerStop: #当获取的o不是workstop信号时,执行while循环 53 with self._workerState(self.working, ct): #上下文切换 54 function, args, kwargs, onResult = o #元组分别赋值给变量 55 del o #删除元组o 56 try: 57 result = function(*args, **kwargs) 58 success = True 59 except: 60 success = False 61 if onResult is None: 62 pass 63 else: 64 pass 65 66 del function, args, kwargs 67 68 if onResult is not None: 69 try: 70 onResult(success, result) 71 except: 72 #context.call(ctx, log.err) 73 pass 74 75 del onResult, result 76 77 with self._workerState(self.waiters, ct): 78 o = self.q.get() #获取任务 79 80 def stop(self): #关闭线程 81 while self.workers: #循环workers 82 self.q.put(WorkerStop) #在队列中增加一个信号~ 83 self.workers -= 1 #workers值-1,直到所有线程关闭 84 85 def show(arg): 86 import time 87 time.sleep(1) 88 print arg 89 90 pool = ThreadPool(10) 91 92 #创建500个任务,队列里添加500个任务 93 #每个任务都是一个元组(方法名,动态参数,动态参数,默认为NoNe) 94 for i in range(100): 95 pool.callInThread(show, i) 96 97 pool.start() #开启执行任务 98 99 pool.stop() #执行关闭线程方法
参考资料:
http://www.cnblogs.com/huxi/archive/2010/06/26/1765808.html
http://www.cnblogs.com/wupeiqi/articles/4839959.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号