pandas模块学习
1. pandas的核心或基础知识点:
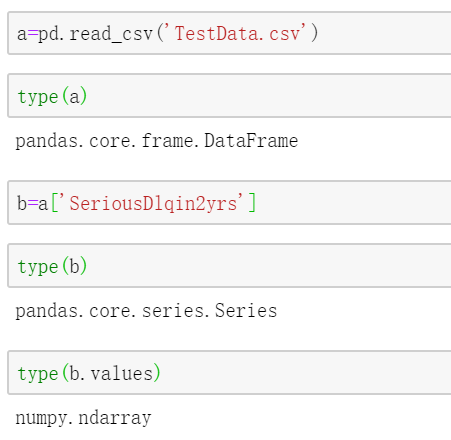
pandas的核心结构是DataFrame,它是由多个series组合而成(Series类型由一组数据及与之相关的数据索引组成),而实际值的核心结果是ndarray,故pandas是基于numpy的一种工具。
2. 各种基础函数的使用:
pd.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, encoding=None,) 导入csv或者txt文档
encoding:文件编码,默认情况下是“utf-8”,但需要注意的是,从原始数据库中导出的数据可能有各种编码,例如gb2312、latin1等,因此这里要设置为与原始数据一致的编码格式,如果报错可以试试改为encoding="gbk",绝对路径复制过来的时候要将''改为'/'

pd.read_excel() 同理pd.read_csv()函数
df.to_excel()将结果保存为excel

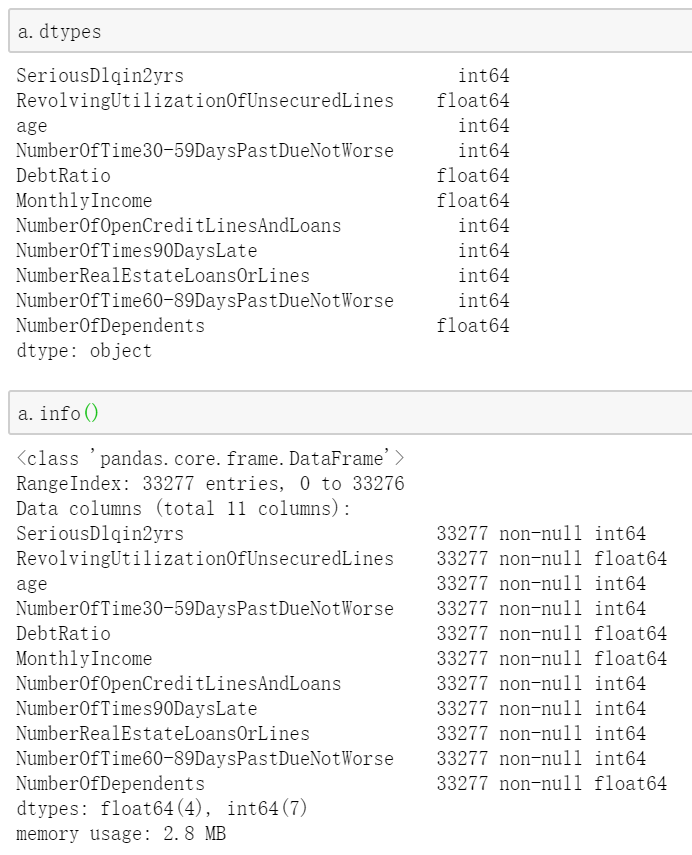
dtypes或者info()查看数据各个字段的类型
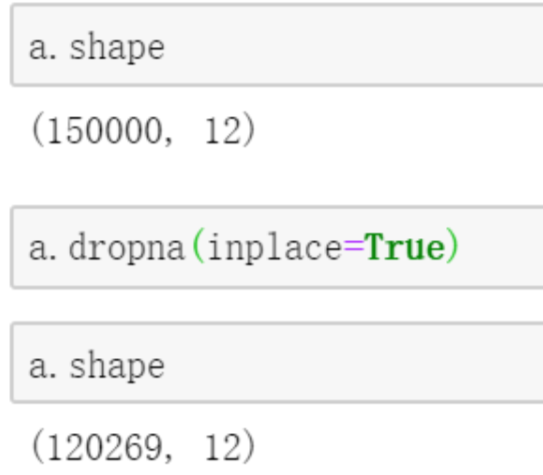
a.shape 获得数据的行和列数量与numpy不同的是numpy有两种方式
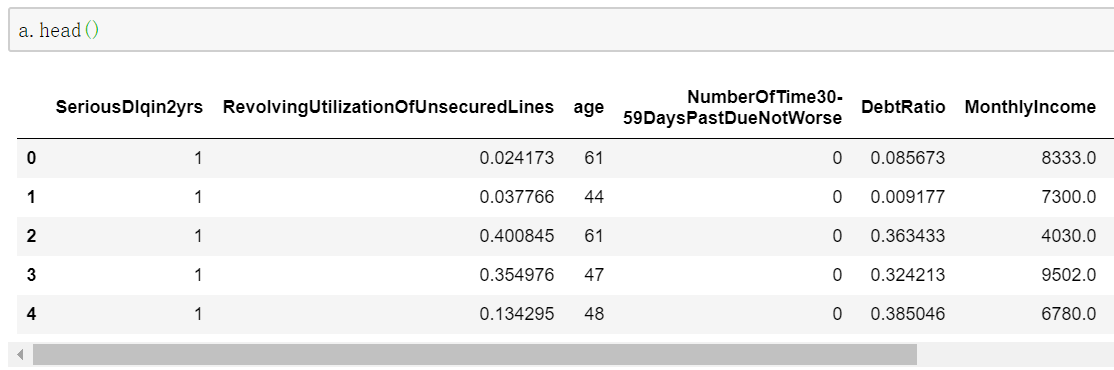
a.head(n=5) 显示前几行的数据,默认值是5
a.tail(n=5) 显示后几行的数据,默认值是5
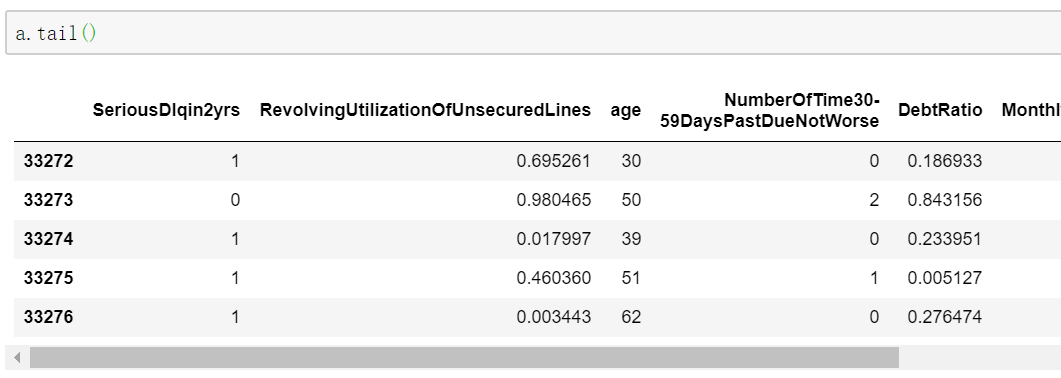
a.columns 获取数据的列名,但是返回值结构不是list,如果要想得到list类型可使用tolist()函数
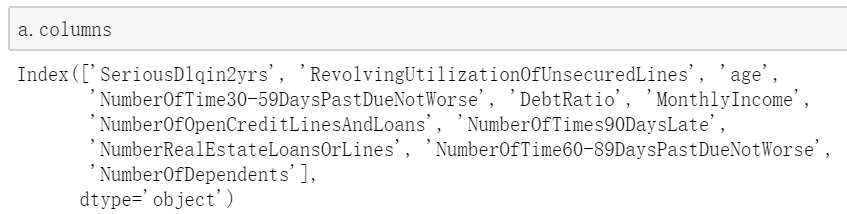
a.loc[a,b] 可取单个值、单行或者多行 a可以是行号,b可以是列名。注:a.ix[]、a.iloc[]已经过时了,不再使用
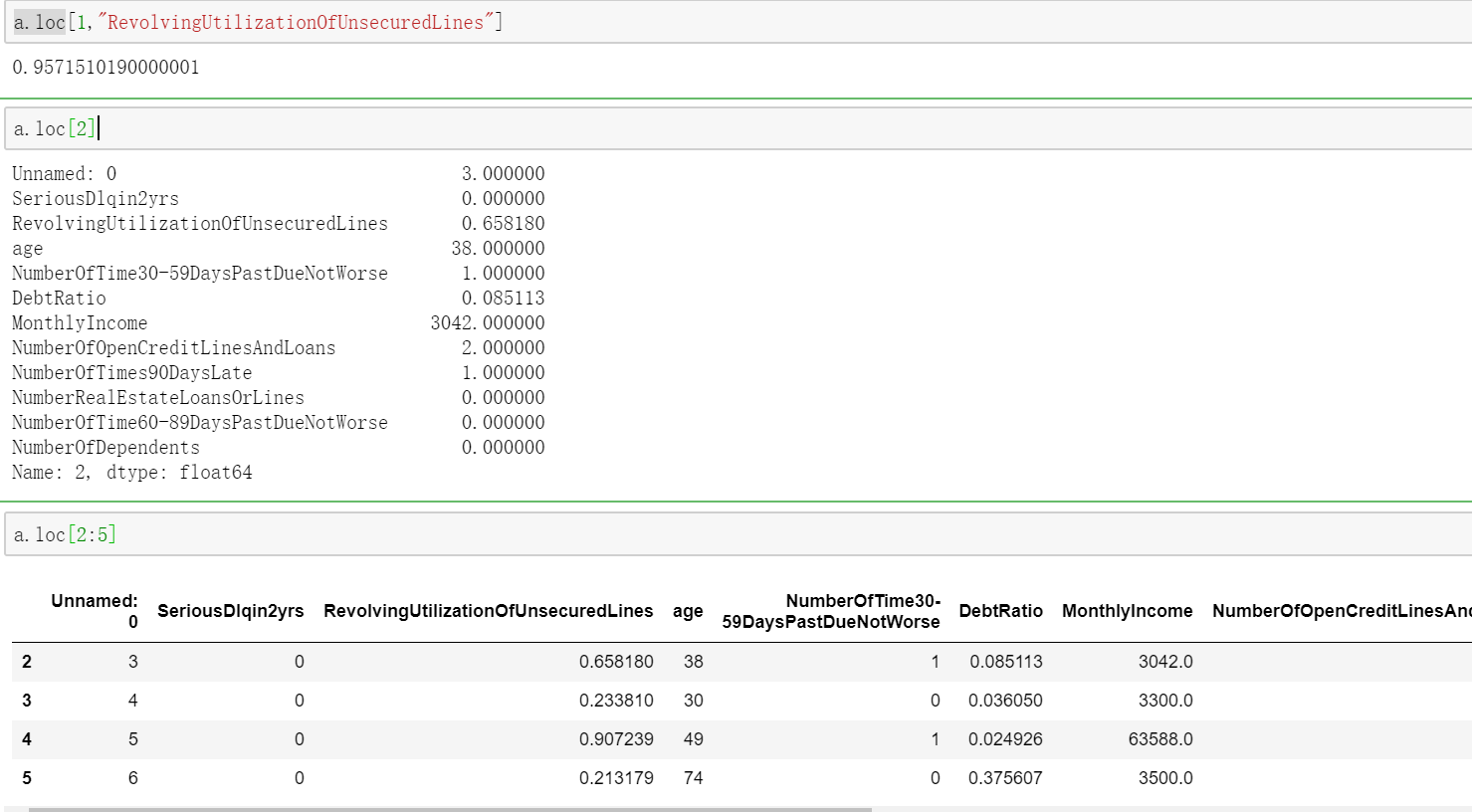
a['b'] 按列取数据,b为列名
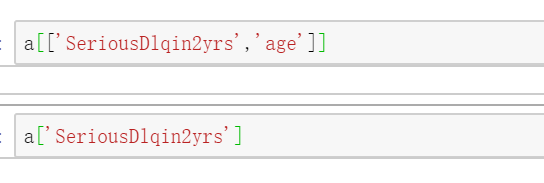
赋值操作 可通过"a[b]=y"的形式,对数据集a新增一个变量b,并且b变量的数据为y
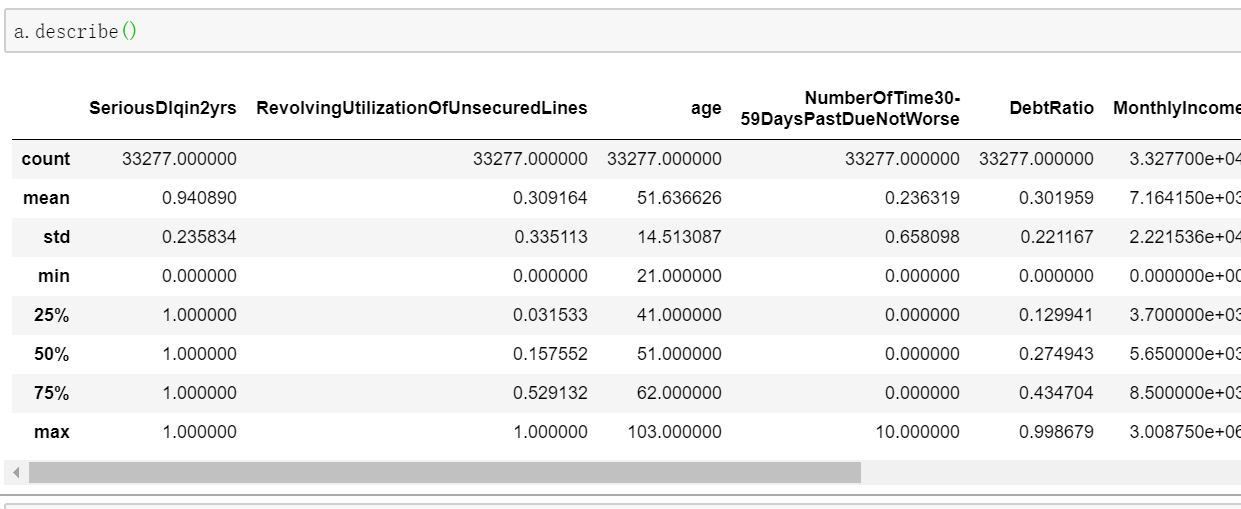
a.describe() 一些基本统计量(计数、均值、极值、中位数等)
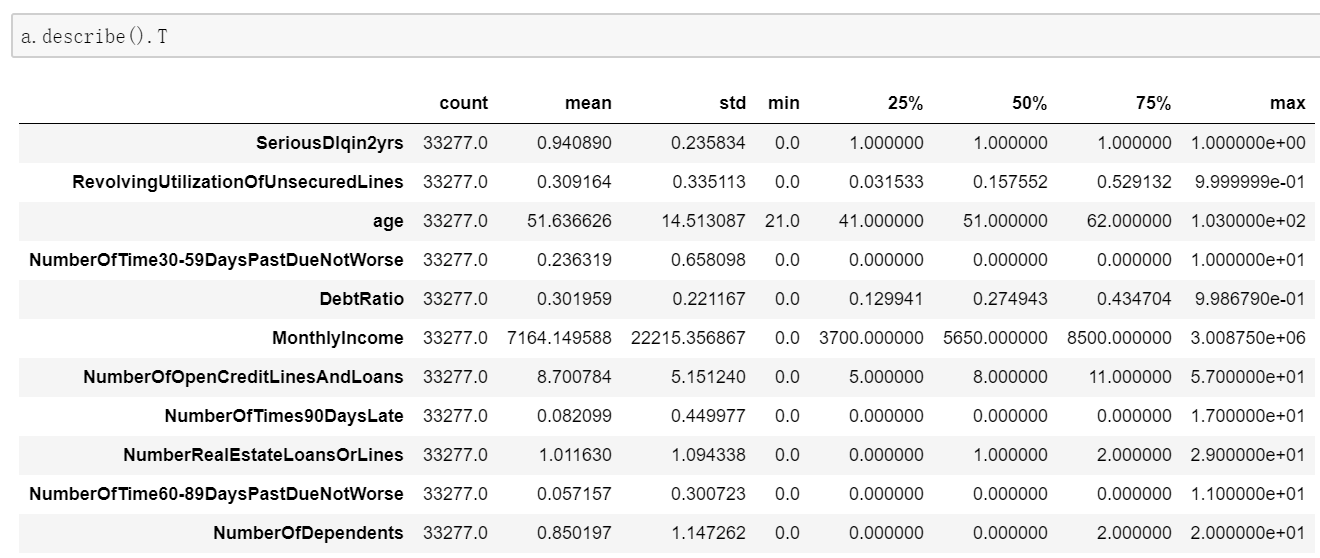
a.T 转置 有时候为了观察数据方便可以使用转置函数
a.isnull()、a.isna() 判断是否空值
a.isnull().any() 判断列中任何元素为TRUE
a.isnull().all() 判断列中任何元素都为TRUE
a.fillna()

a.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)丢弃缺失值,可以按行也可以按列

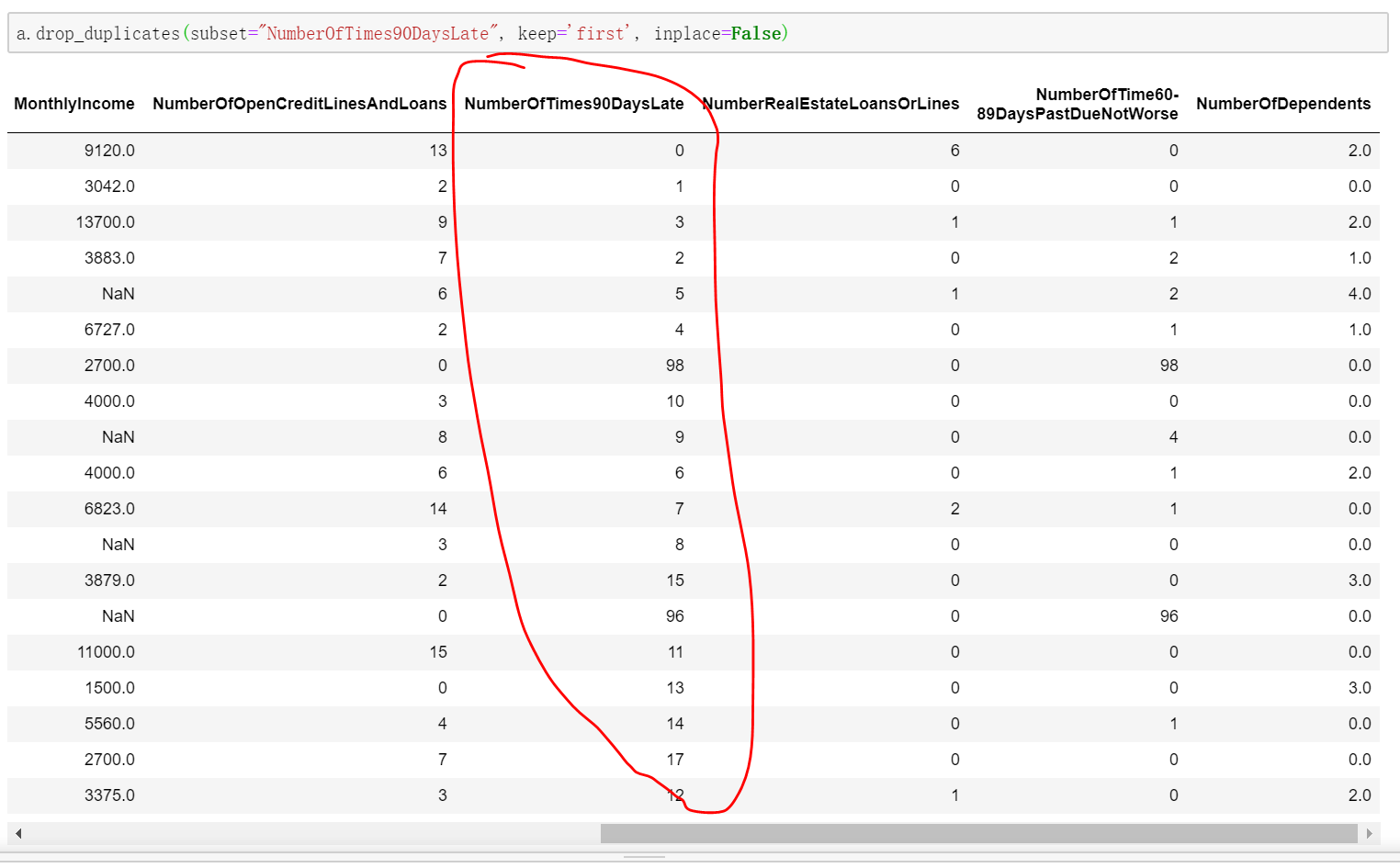
a.duplicates(subset=None, keep='first', inplace=False) 判断重复数据
a.drop_duplicates(subset=None, keep='first', inplace=False) 丢弃重复数据
1)subset对应的值是列名,默认值为subset=None表示考虑所有列。
2)keep='first’表示保留第一次出现的重复行,是默认值。keep另外两个取值为"last"和False,分别表示保留最后一次出现的重复行和去除所有重复行。
3)inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本
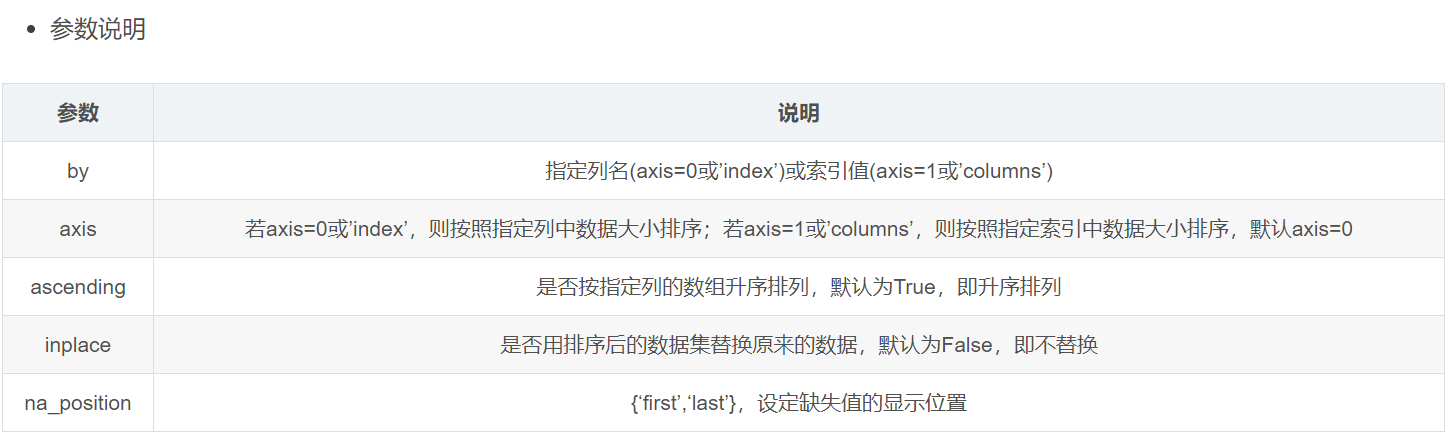
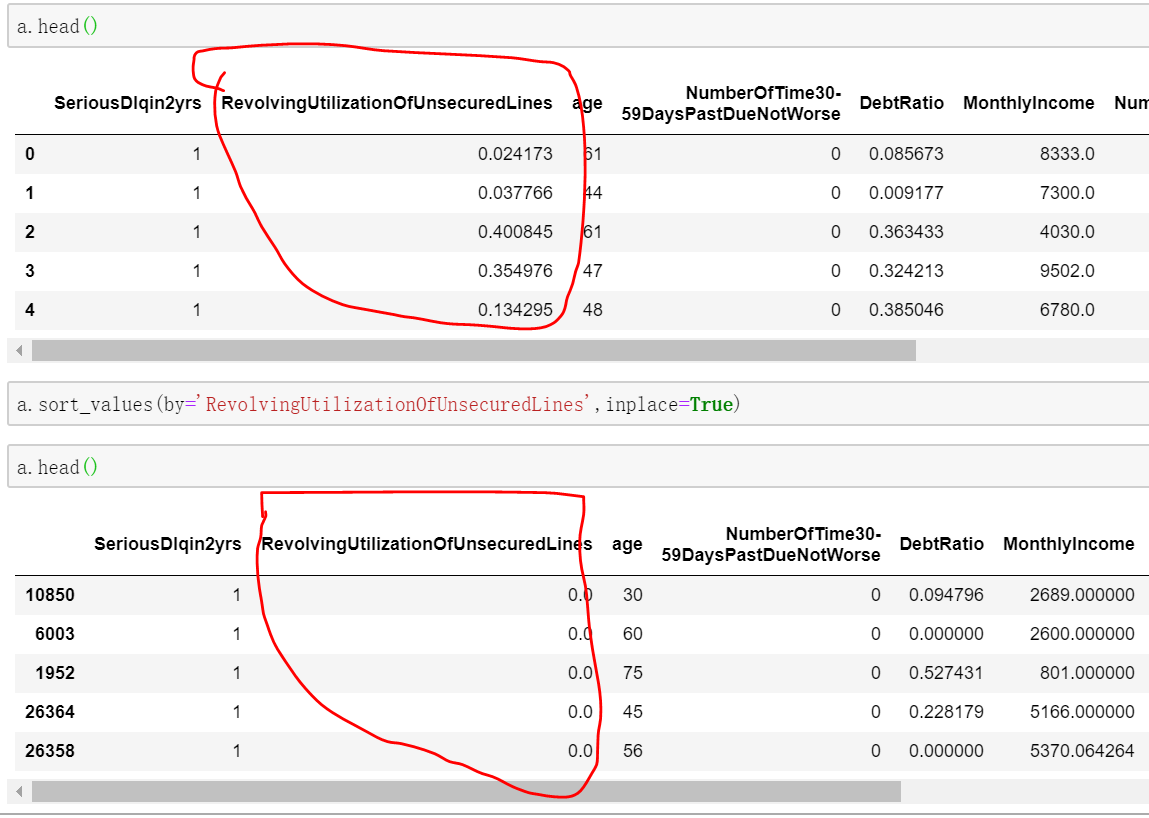
a.sort_values(by,axis=0,ascending=True,inplace=False,kind='quicksort',na_position='last',) 排序,默认是升序排列,无论降序和升序缺失值NAN都在最后
a.set_index(keys,drop=True,append=False,inplace=False,verify_integrity=False,) 重新定义index,index也可以是字符串类型
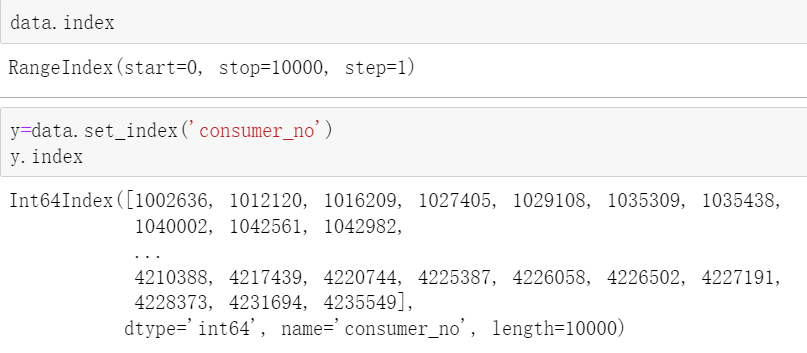
a.reset_index(level=None,drop=False,inplace=False,col_level=0,col_fill='',) 由于使用sort_values排序之后下标会发生变化,使用该函数下标也会重新排序

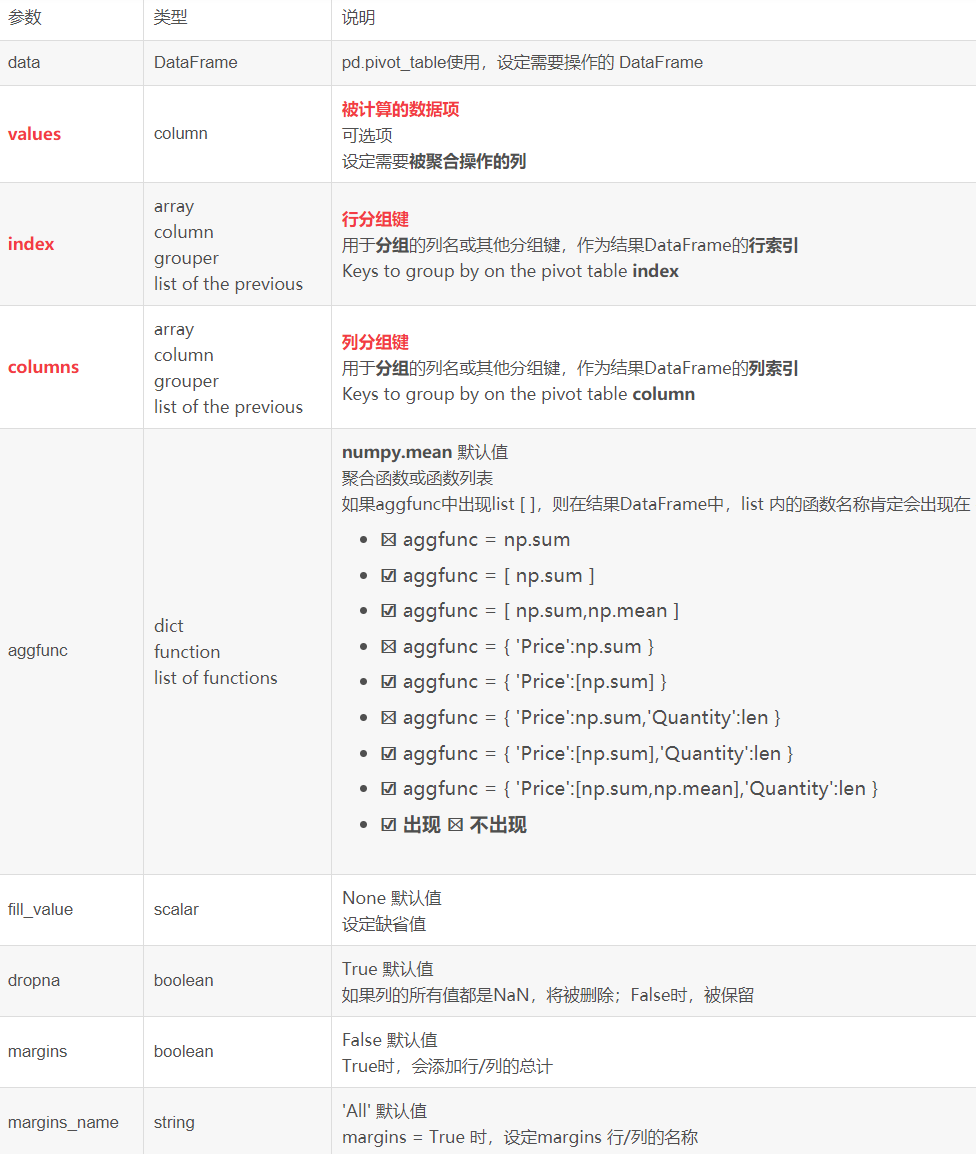
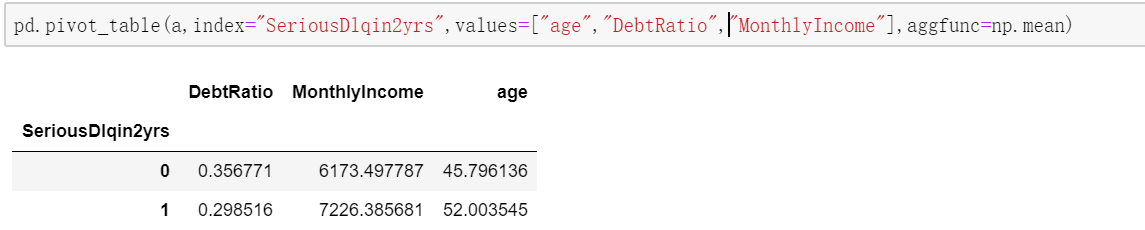
a.pivot_table(values=None,index=None,columns=None,aggfunc='mean',fill_value=None,margins=False,dropna=True,margins_name='All',) 分类统计,类似于数据透视表
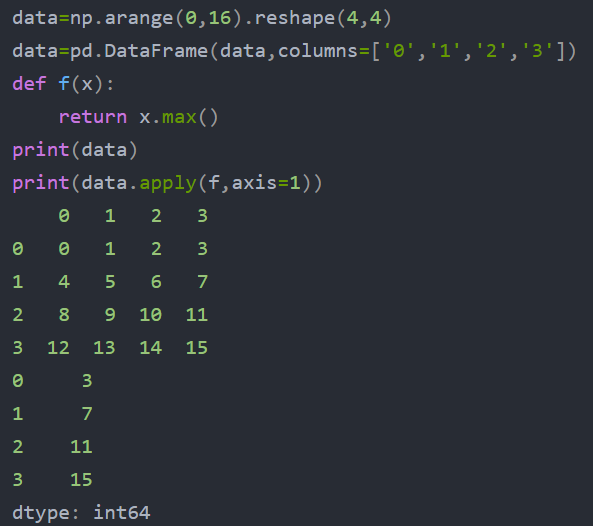
apply() DataFrame.apply(func, axis=0)
该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针。
这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据 结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数 会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
to_datetime() 修改时间字段的格式
get_dummies() 可以将变量转化为哑变量
series.map() https://blog.csdn.net/ialexanderi/article/details/78493448
merge() https://blog.csdn.net/qq_34071917/article/details/82192441
groupby() https://www.cnblogs.com/huiyang865/p/5577772.html
isin()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号