Neural Tangent Kernel (NTK)基础推导
A. Jacot, F. Gabriel, and C. Hongler, ‘Neural Tangent Kernel: Convergence and Generalization in Neural Networks’. arXiv, Feb. 10, 2020. Accessed: Mar. 18, 2023. [Online]. Available: http://arxiv.org/abs/1806.07572
当然,这篇随笔并不只是上面这篇开山之作(NIPS 2018)的阅读笔记,而是融合了我所需要的NTK相关的基本知识。
某种意义上写这篇博客有点“不务正业”了,因为和目前想做的内容没有直接相关。之所以决定好好记录一下NTK是因为最近看到的几篇理论文章在推导时都应用了NTK的假设和一部分内容,并且认真了解网络动力学和优化相关的理论更利于随后工作的开展。反正学到就是赚到(打好数理基础肯定不吃亏?)
Introduction
神经网络的疑云
神经网络在提出初期存在许多质疑,包括但不限于如下内容
-
Non-convexity
神经网络不是凸函数,会存在许多局部极小值,梯度下降最终得到的结果与真正的极小值点是否有较大差别?
-
Initialization
从不同初始化下进行梯度下降,最终结果是否会有较大偏差呢?
-
Interpretability
神经网络如何被描述?众多神经元和参数有哪些内在联系?
-
Generalization
神经网络参数很多,理论上很容易过拟合,但是在测试集上的表现还不错,表现出较好的泛化性能,如何解释呢?
譬如,对第四点,机器学习的传统观点认为,在训练误差和泛化差距之间要进行谨慎的权衡。模型的复杂性存在一个“最佳点”。因此如果模型足够大,就可以实现合理良好的训练误差;而模型足够小,才可以降低泛化差距(测试误差和训练误差之间的差)。较小的模型会产生较大的训练误差,而使模型变大则会导致较大的泛化差距,两者都会导致较大的测试误差。测试误差随模型复杂度的变化可以经典U形曲线来描述(如下图a,图片来自文献Reconciling modern machine learning practice and the bias-variance trade-off)

但是,如今很常见的是使用高度复杂的过参数化模型,例如深度神经网络。通常对这些模型进行训练,以在训练数据上实现接近零的误差,但是它们仍然在测试数据上具有出色的性能。上图的作者Belkin等人通过“双重下降”曲线对这一现象进行了描述,该曲线扩展了经典的U形曲线(如上图b),并对此进行了理论解释。可以观察到,随着模型复杂度增加到可以完全拟合训练数据的程度(即达到插值制度),测试误差继续下降!有趣的是,最好的测试效果通常是通过最大的模型实现的,这与关于“最佳点”的经典直觉背道而驰。
因此,有人怀疑深度学习中使用的训练算法((随机)梯度下降及其变体)以某种方式隐含地限制了训练网络的复杂性(即参数的“真实数量”),从而导致了较小的概括差距。
更直接点,举个例子,比如单目标分类,有时候数据还没有网络参数多,相当于一个有很多未知量的式子,但是限制它的方程数量却很少,那么这样一个自由度很高但约束很少的式子,怎么能符合我们对其专一且严格的要求呢?
NTK的提出
NTK是一种较成功的解释以上质疑的技术性理论,它有两个假设:
- 需要一种特殊的初始化技巧(Kaiming Initialization)
- 网络足够宽(或者说,无限宽)
第二条假设某种意义上对应人们之前对深度神经网络泛化性能和参数量的怀疑,而第一条假设是一个先决条件,即,在我们训练过程中,网络中不应该出现梯度的爆炸或者消失,而是保持均匀
并且,顾名思义,神经正切核Neural Tangent Kernel是一种核方法,1994年Priors for Infinite Networks就已经提出了无限宽的神经网络和核方法之间的联系。近几年内,NTK相关的基础理论文章得到了几个惊人的结论,比如
- 整个训练过程中网络存在一个不变量,不依赖于网络参数,这个不变量就是NTK,神经正切核(NTK开山之作,
Neural Tangent Kernel: Convergence and Generalization in Neural Networks) - 在无穷宽度条件下,宽神经网络由在初始参数处的一阶泰勒展开式线性模型主导。并且尽管上述结论是在无限宽模型下得到的,论文作者发现实验证明对于可操作的有限尺寸的神经网络,由神经网络得到的估计与线性模型得到的估计也是基本一致的。且这个一致性对于不同结构、不同优化方法、不同损失函数,都是成立的。特别地,在平方损失MSE下,该动态是一个关于时间的封闭解函数(
Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradien Descent) - 梯度下降可以绕过局部最小值,从初始化快速找到全局最小值(
Gradient Descent Finds Global Minima of Deep Neural Networks)
这些结论很好地解释了很多对于神经网络优化的质疑。接下来我们会依次介绍对应的条件(或者假设)下的推导和近似
初始化:Kaiming Initialization / He Initialization
正如其名字,这个初始化方法是大佬何恺明ICCV 2015的工作, Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification 提出的
初始化的意义在于调整各层神经元的方差,确保不会出现梯度爆炸和梯度消失的情况。从自然科学的角度来看,可以说这样初始化调整后的网络具有某种意义上的空间平移不变性,我们希望这种“空间对称性”可以为神经网络带来一个类似“动量守恒”一样的守恒量
在何恺明之前的Xavier初始化对激活函数对称性要求较高,没有很好地考虑到激活函数为非奇函数时
Notations
许多文献的符号约定都不尽相同,这里我自己定一套吧
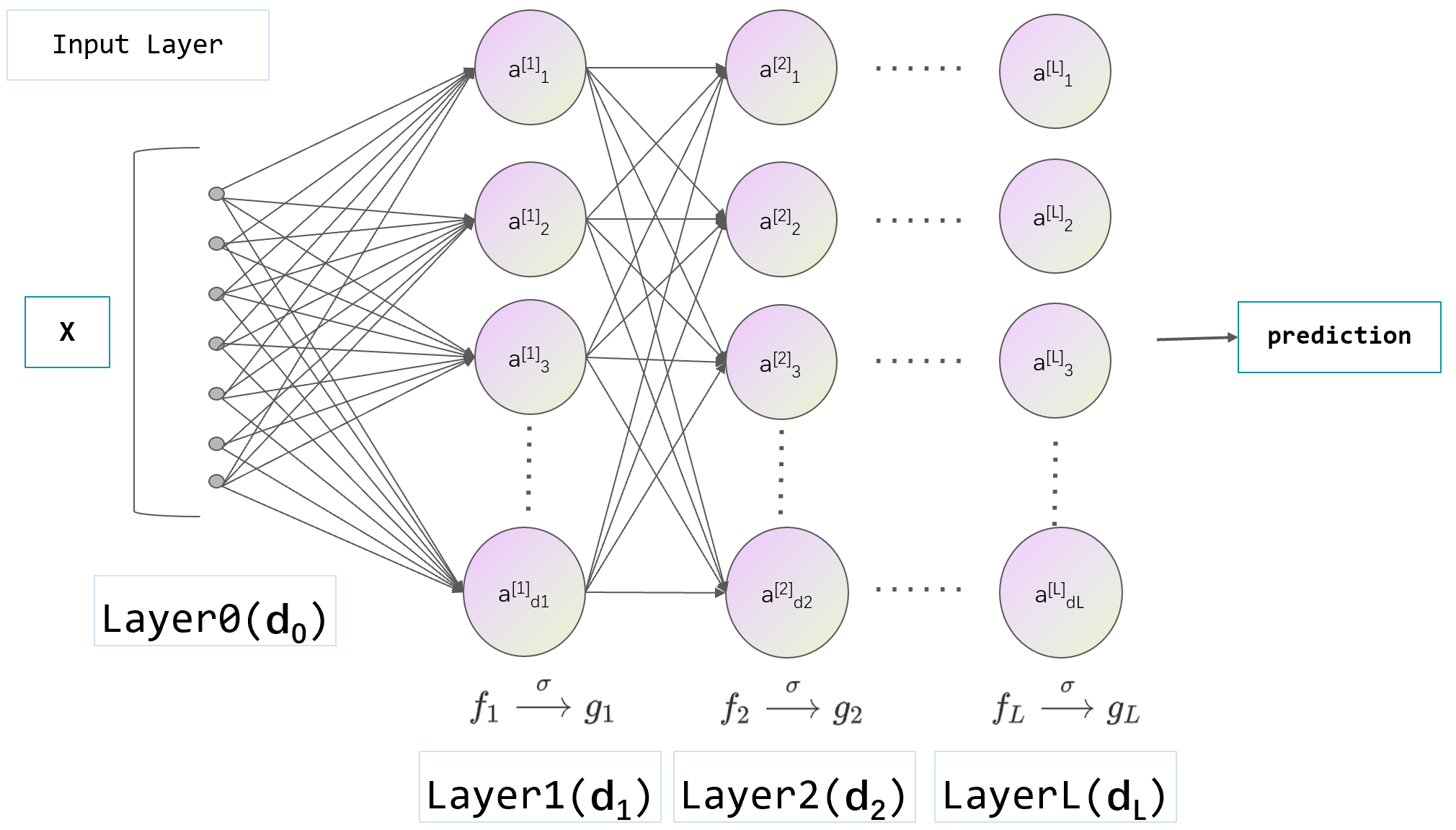
如上图(好难画),定义一个有 L 层的ANN:
即,将维度为P的参数
其中
第
我们定义第h层神经元的值为向量
因为将
Assumptions
很好理解的一点是,既然我们的网络参数都已经奔着标准正态分布初始化了,那么聪明的读者当然会想到,输入的
初始化形式
为了得到守恒量,我们需要改写神经网络,给参数
我们称其为网络的标准形式。
其中
为方便理解
与我们“标准形式”网络假设对应的,我们需要初始化参数
我们将参数
这样我们的参数初始化可以写为
这就是大佬论文原文使用的初始化方法
理论证明
推导不算难,就是手敲公式略麻烦
第
我们的参数初始化应该使得
这里我们认为更具有普适性的
这里我们不妨用一点数学归纳法的思想,已知
根据我们之前的假设,
所以我们只需要在式子中乘一个
这里其实有个逻辑漏洞没有补上,就是我们证明了这种参数修正下满足传入
可以得到均值为 ,方差为1的 ,但是并不能说明 时正态分布,因为无限宽网络神经元的参数传递满足独立同分布在当时还没有证明(并不是如我们所想地那样显而易见)。后续谷歌的人2018年用 Deep Neural Networks as Gaussian Processes补上了这个漏洞,不过因为篇幅和时间有限,这里当作一个小引理使用了。
举个具体的例子,对于RELU,则有:
这就不难解释对于对于
如果只是对梯度量级的估计,那么在全部标准正态分布初始化的基础上只要修正的参数能
就可以,甚至无所谓在激活函数内还是外
NTK区域下的梯度流和动力学方程
这里我们研究学习率
梯度流
考虑神经网络
定义数据集
其中
使用梯度下降进行训练
就不具体阐述梯度下降的物理意义了,注意这里的t代表的是一个时间尺度的概念,但并不具有时间量纲,所以可以人为设定
可以看出
可以发现
动力学方程
我们定义神经网络的输出
我们可以得到描述误差随训练步数变化的方程,也就是网络训练的动力学方程:
这里我们令
从上式不难看出误差随时间的演变过程可以被线性描述为与时间无关的核。定义核函数
为了更直观理解这个核函数,可以将其写为:
可以将其理解为网络在训练过程中,输入一个位于
的数据点对监督样例 优化的灵敏度,表现为网络最终输出的变化
那么可以将动力学方程表示为:
我们希望用离散的方式来描述上面的动力学方程,因为
特别地,当loss函数取MSE时,
千万注意,
和 都不是常数, ,与网络参数有关,所以也与时间相关
将这个网络的动力学方程向量化表示为
这是一个非线性一阶常微分方程。由上式可以看出,
更进一步,考虑任取样例
其中
小推论:Gram Matrix
的正定性证明: 令
,则 对
, 因此
Neural Tangent Kernel
无限宽假设下的模型近似
为了得到一个不与时间有关的守恒量,我们引入一个重要假设——神经网络隐藏层无限宽 ,也就是
据此,我们就得到了更为方便的无限宽近似下的网络动力学方程
或者其连续形式
下面说明,在隐藏层无限宽下,NTK就是一个不随时间变化的常数矩阵:在Kaiming Initialization(或者相同量级的初始化)条件下,参数
后文中简记,用
我们得到了,在网络趋近于无穷宽的一阶近似下,右边一个时间相关的项和左边的常数项相等
所以在无限宽的神经网络中,G 是会无限逼近零时刻的 G 矩阵的,也就是说
不难看出,当网络趋于无穷宽时,神经正切核
这意味着一个时变核变成了一个固定核。于是在这种情况下,神经网络的训练过程就变成了一个核回归的过程。
特殊地,当损失函数为MSE时,
动力学方程的收敛性分析
实际经验不难发现
我们希望证明,因为核
和 都是正定的,只要LOSS函数是有界凸函数,那么当 时,网络参数就可以收敛到最优(也就是说误差可以衰减到0)
对
其中
带入离散形式的动力学方程
由特征向量的正交性,对应项前系数相等
因此只要所有特征值都非负,那么这个线性常微分方程组指数收敛
有限宽网络如何近似为无限宽
我们如何直接使用我们基于无限宽假设的理论来分析实际有限宽的网络呢?换言之,对于较宽的真实网络
严格的数学层面分析可以参照下述定理
Theorem 1 Suppose
with . Then for any , with probability at least over the random initialization, we have
这说明,只有实际网络足够宽,实际网络与理论网络的差距很大概率可以无限小
Conclusion
我省略掉一些与基础理论无关的我暂时不感兴趣的内容,因为目前总结的内容基本足够我将NTK作为工具阅读分析一些理论文章
理解超参数化深度神经网络的性能绝对是一个具有挑战性的理论问题。现在,至少我们对一类超宽神经网络有了更好的理解。
我们发现,无限宽的ANN初始化等价于高斯过程,所以可以和Kernel method联系起来。然后我们证明了,训练过程也可以用一个kernel method来描述,并且能够通过kernel gradient descent来训练,这个kernel就是NTK,证明NTK在无穷宽条件下变成了一个固定核,最后证明了绝大多数情况下训练过程的收敛性,以及讨论了有限宽网络如何逼近无限宽网络的。
顺带一提,挖个大坑,无限宽隐藏层(因此符合我们希望的统计学规律),独立同分布的参数假设同样符合平均场理论,但篇幅有限,不在此探究其原理,以及两者关联。等有机会的话看看有没有时间了解一下吧(不过短时间内应该没时间填坑了)
参考文献
J. Lee et al., ‘Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent’, J. Stat. Mech., vol. 2020, no. 12, p. 124002, Dec. 2020, doi: 10.1088/1742-5468/abc62b.
M. Belkin, D. Hsu, S. Ma, and S. Mandal, ‘Reconciling modern machine learning practice and the bias-variance trade-off’, Proc. Natl. Acad. Sci. U.S.A., vol. 116, no. 32, pp. 15849–15854, Aug. 2019, doi: 10.1073/pnas.1903070116.
S. S. Du, J. D. Lee, H. Li, L. Wang, and X. Zhai, ‘Gradient Descent Finds Global Minima of Deep Neural Networks’. arXiv, May 28, 2019. Available: http://arxiv.org/abs/1811.03804
S. Arora, S. S. Du, W. Hu, Z. Li, R. Salakhutdinov, and R. Wang, ‘On Exact Computation with an Infinitely Wide Neural Net’. arXiv, Nov. 04, 2019. [Online]. Available: http://arxiv.org/abs/1904.11955
K. He, X. Zhang, S. Ren, and J. Sun, ‘Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification’. arXiv, Feb. 06, 2015. [Online]. Available: http://arxiv.org/abs/1502.01852
K. He, X. Zhang, S. Ren, and J. Sun, ‘Deep Residual Learning for Image Recognition’, arXiv:1512.03385 [cs], Dec. 2015, [Online]. Available: http://arxiv.org/abs/1512.03385
J. Lee, Y. Bahri, R. Novak, S. S. Schoenholz, J. Pennington, and J. Sohl-Dickstein, ‘Deep Neural Networks as Gaussian Processes’. arXiv, Mar. 02, 2018. [Online]. Available: http://arxiv.org/abs/1711.00165
G. Yang, ‘Scaling Limits of Wide Neural Networks with Weight Sharing: Gaussian Process Behavior, Gradient Independence, and Neural Tangent Kernel Derivation’. arXiv, Apr. 04, 2020. [Online]. Available: http://arxiv.org/abs/1902.04760
Some Intuition on the Neural Tangent Kernel (inference.vc)
机器学习12: 无穷宽神经网络之DNN in NTK regime 哔哩哔哩
深度学习理论之Neural Tangent Kernel第四讲:当NTK遇上平均场理论 - 知乎
【深度学习4】神经网络的正切核理论:引言和定义(下)哔哩哔哩
欢迎转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统