文献阅读——MixSKD
C. Yang et al. , ‘MixSKD: Self-Knowledge Distillation from Mixup for Image Recognition’. arXiv, Aug. 11, 2022. [Online]. Available: http://arxiv.org/abs/2208.05768
ECCV 2022,中科院一个很有意义的工作,将mixDA和自蒸馏结合起来,用论文的话来说,MixSKD mutually distills feature maps and probability distributions between the random pair of original images and their mixup images in a meaningful way.
作者提到了一个和理论文章“On Mixup Regularization”类似的观点,mixDA能成功的一个重要原因是label smoothing,就如知识蒸馏一样(两者的soft label当然有区别,知识蒸馏的soft label还有类内多视图信息和类间信息所以效果更明显,我之前也看到过以Label Smoothing Regularization角度来分析KD原理的文章),这是之前对mixup的理论分析文章所没能注意到的。
Introduction
现有的自蒸馏思路主要有两种,分别是利用辅助架构(这个常见,看过的工作主要也都是这种的),以及数据增强(这个了解较少,下面介绍pipeline时会顺便介绍一篇较早的工作)
作者的想法就是通过自蒸馏来match两张图片分别的特征和它们mixup后的特征,这个特征可以是各阶段的feature map,处理后的概率(或者说soft label)和作为ground truth的one-hot label,很巧妙,但说起来其实并不难理解,如下图:
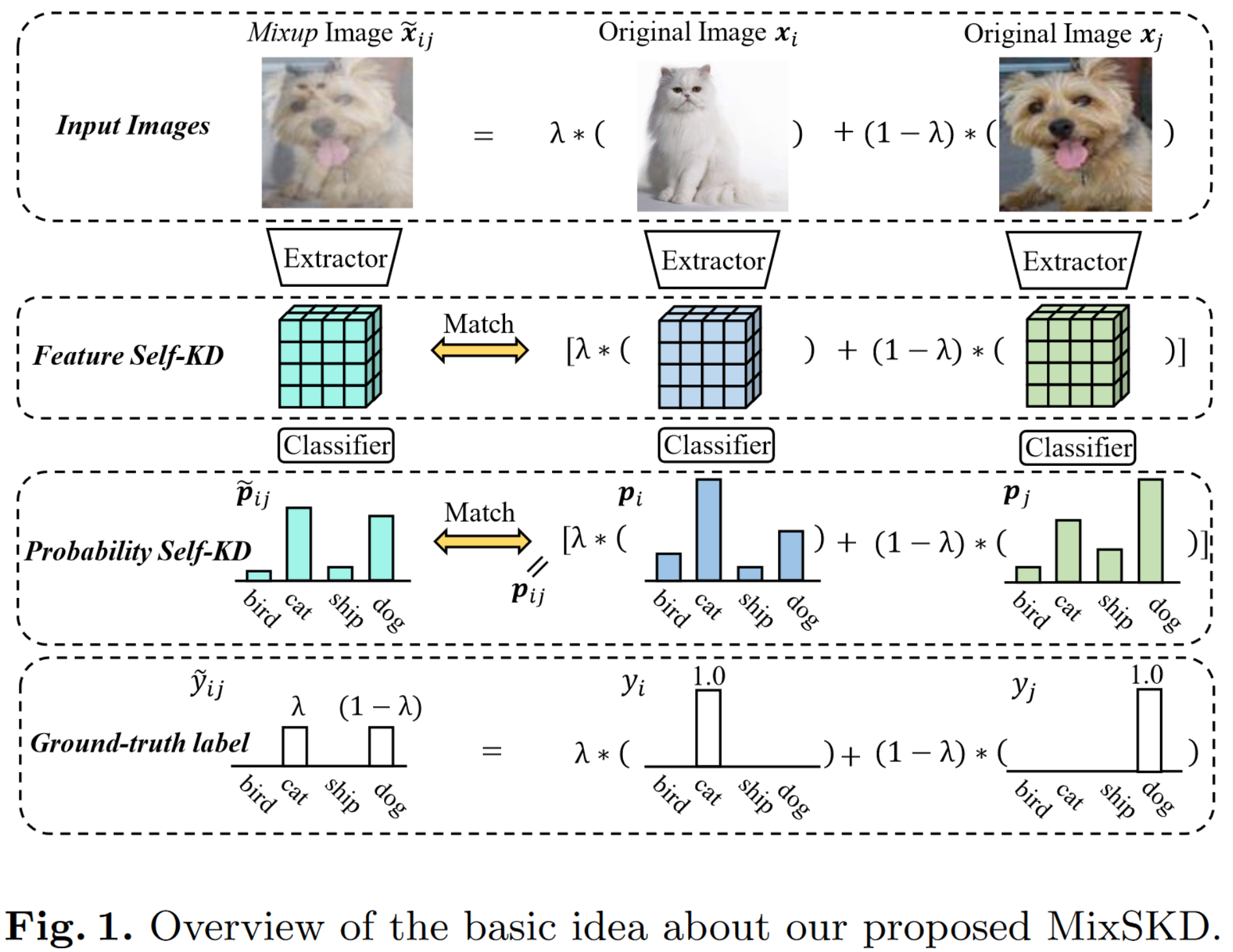
作者说这样的好处是“The soft label is informative since it assembles all feature information across the network.”
Method
Pipeline
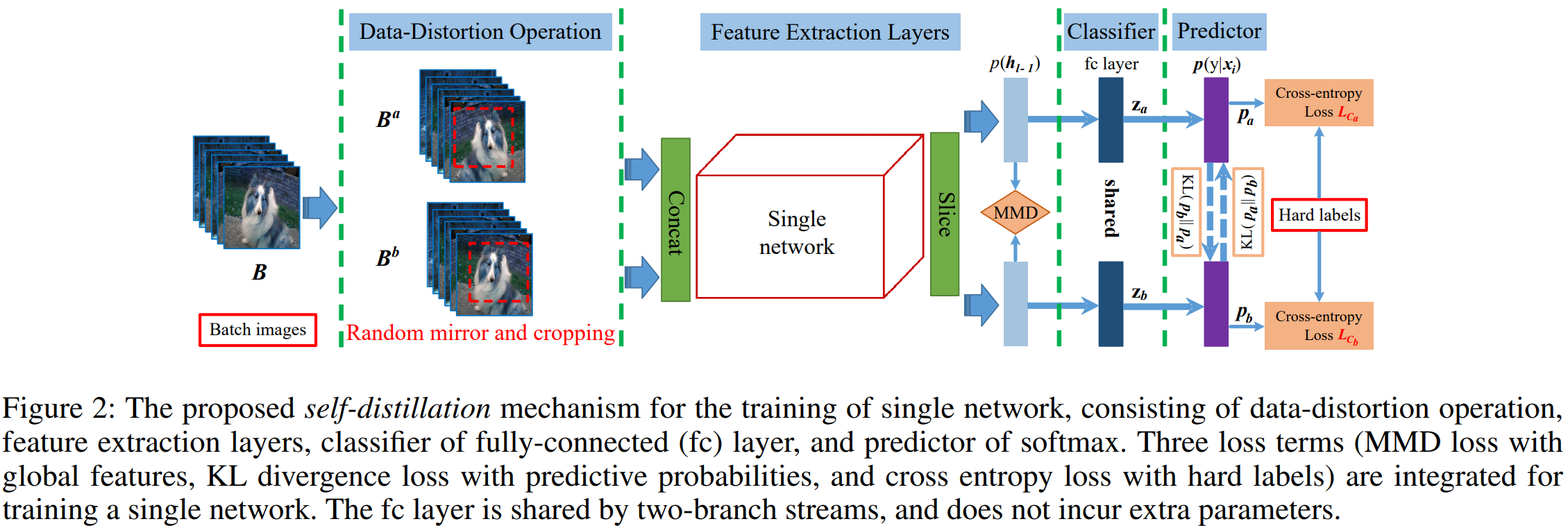
我感觉作者应该是受到之前的一篇工作,DDGSD的启发,具体结构如下:
T.-B. Xu and C.-L. Liu, ‘Data-Distortion Guided Self-Distillation for Deep Neural Networks’, AAAI, vol. 33, no. 01, pp. 5565–5572, Jul. 2019, doi: 10.1609/aaai.v33i01.33015565.
这篇工作提出一种基于数据增强的自蒸馏框架,正则化了一张image两种不同augmented versions之间预测分布的一致性,从而从数据增强中蒸馏出知识
因为模块是共享参数的,所以可以看作对simCLR类型对比学习的借鉴
总体的思路是,通过对经过简单distortion后的同一图像的各阶段feature(可以是feature map,可以是soft label,也可以是one-hot label)的蒸馏,进行蒸馏。我觉得这是一种一致性正则,约束不同数据增广版本的图片输出一致
下面是作者的pipeline,添加了逐stage的蒸馏(feature map和logit都有),并且结合了mixup的做法,对两张图像的feature map和logit进行element-wise的线性相加后,与直接mixup的图像的对应feature进行互相比对和蒸馏。
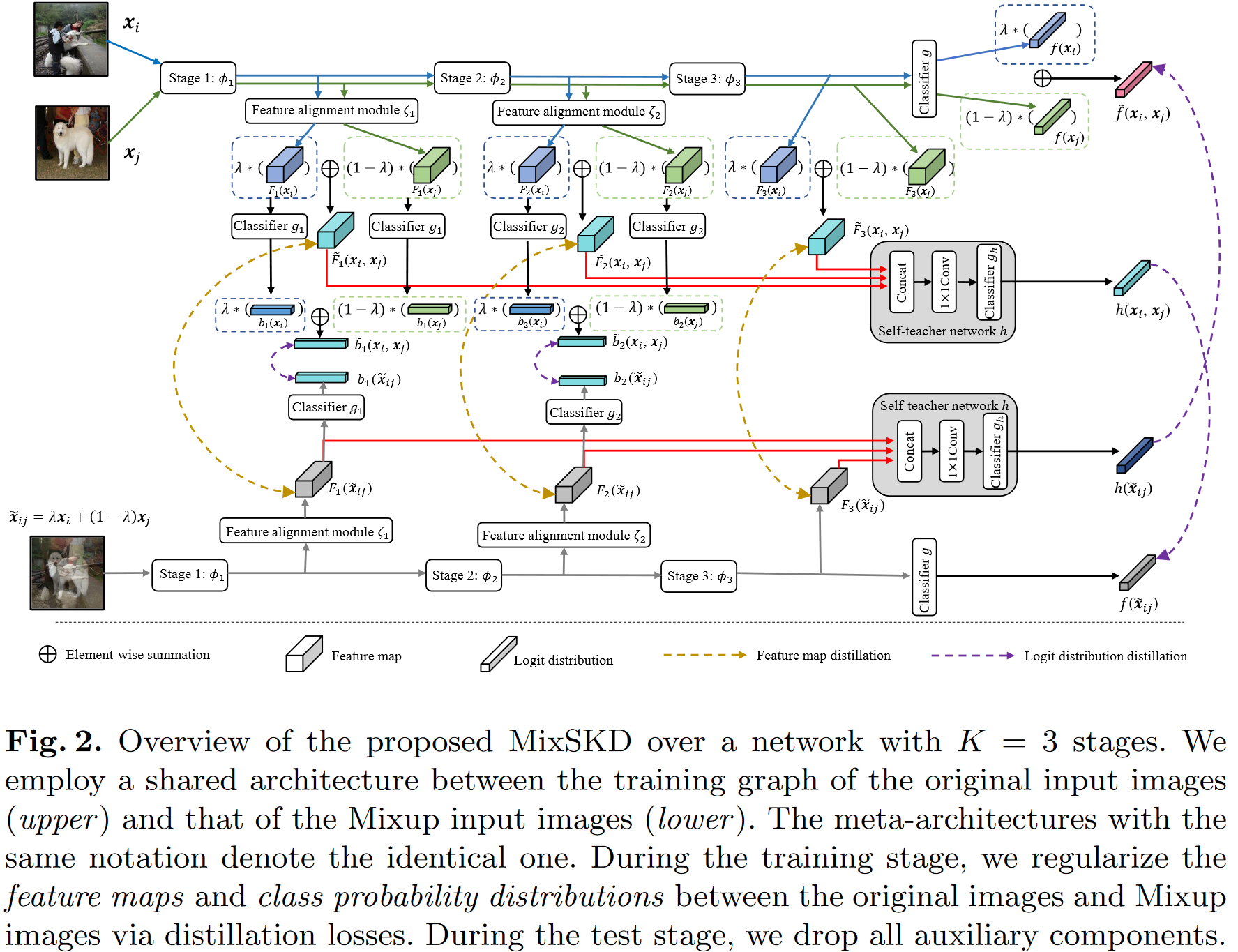
具体实现
一个分类CNN主要由特征提取器 \(\phi\) 和线性分类器 \(g\) 组成,可以写为 \(f=g \circ \phi\) ,这里我们忽略掉pooling
那么一个多层(K个stage,这里的stage可以是卷积层,残差块,什么都行)卷积层的结构就是:
这个写法很像矩阵运算。在1到K-1的stage上,我们各加一个监督模块\(b_k\),每个 \(b_k\) 包括一个特征对齐模块 \(ζ_k\) 和一个线性分类器 \(g_k\) 。对于输入\(x\), 每一层的输出和backbone的输出分别为:
特征对齐模块 \(ζ_k\) 目的是将浅层阶段的特征图输出转换为与末端的特征维度相匹配,实现方法就是让这玩意有相同的下采样。附录中对模块 \(ζ_k\) 进行了具体的介绍,特征对齐模块就是ResNets的residual block,使用了和backbone相同的下采样数来实现的。
在输入线性分类器 \(g_k\) 之前的特征图,作者命名为 \(F_1\cdots F_K\) ,其中 \(F_K\) 是backbone最终的feature map。
logit vectors \(b_{1}(\boldsymbol{x}),\cdots,b_{K-1}(\boldsymbol{x}) \in \mathbb R^C\) ,backbone的logit同样 \(f(\boldsymbol{x}) \in \mathbb R^C\)
Loss
任务引导的分类误差
来自结构源的误差:就是最普通的分类用的交叉熵loss。使用原始的交叉熵任务误差来训练主网络f和K-1个辅助分支,使之获得分类能力和产生语义特征:
其中 \(\sigma\) 是softmax函数,用来将logits normalize, \(L_{ce}\) 表示交叉熵函数
来自数据源的误差:给定输入图像\(x_i\) , \(x_j\)和Mixup图像\(x_{ij}\),代入结构源的误差,可以得到任务误差:
特征图Self-KD
使用L2距离来逼近原始图像插值得到的特征图与Mixup图像生成的特征图:
受对抗学习思想的启发,本文引入了一个判别器来判别特征来源于插值还是Mixup图像,来提升特征逼近的难度,从而使得网络能够学习到有效的语义特征:
概率分布Self-KD
本方法使用KL散度去逼近原始图像插值得到的概率分布与Mixup图像产生的概率。在K-1辅助分支上使用如下的误差:
对于最终的主干网络,本方法进一步构造了一个self-teacher网络来提供高质量的软标签作为监督信号。self-teacher网络聚合网络中间层的特征,然后通过一个线性分类器输出类别概率分布,受到Mixup插值标签的监督:
主干网络最终输出的类别概率分布的监督信号来源于self-teacher网络:
整体误差
将上述误差联合起来作为一个整体误差进行端到端的优化:
MixSKD的整体示意图如文章中的图2所示。本方法引导网络在隐层特征和概率分布空间具有线性决策行为。从Occam剃刀原理上讲,线性是一个最直接的行为,因此是一个较好的归纳偏置。此外,线性行为可以在预测离群点时减少震荡。
实验结果
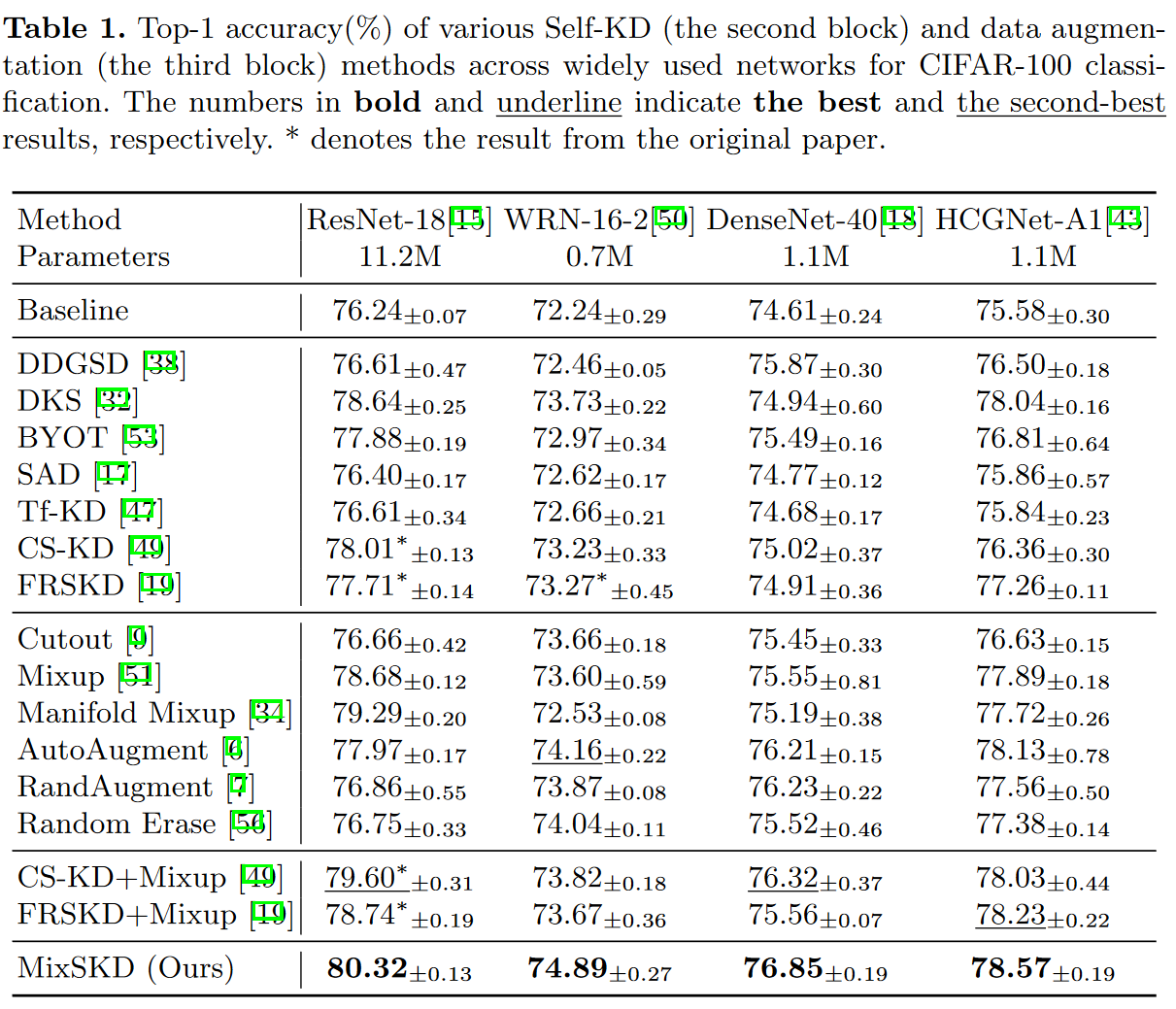
- MixSKD用于CIFAR-100图像识别,如下图所示。MixSKD在不同网络结构上超越了先前的Self-KD与数据增强方法
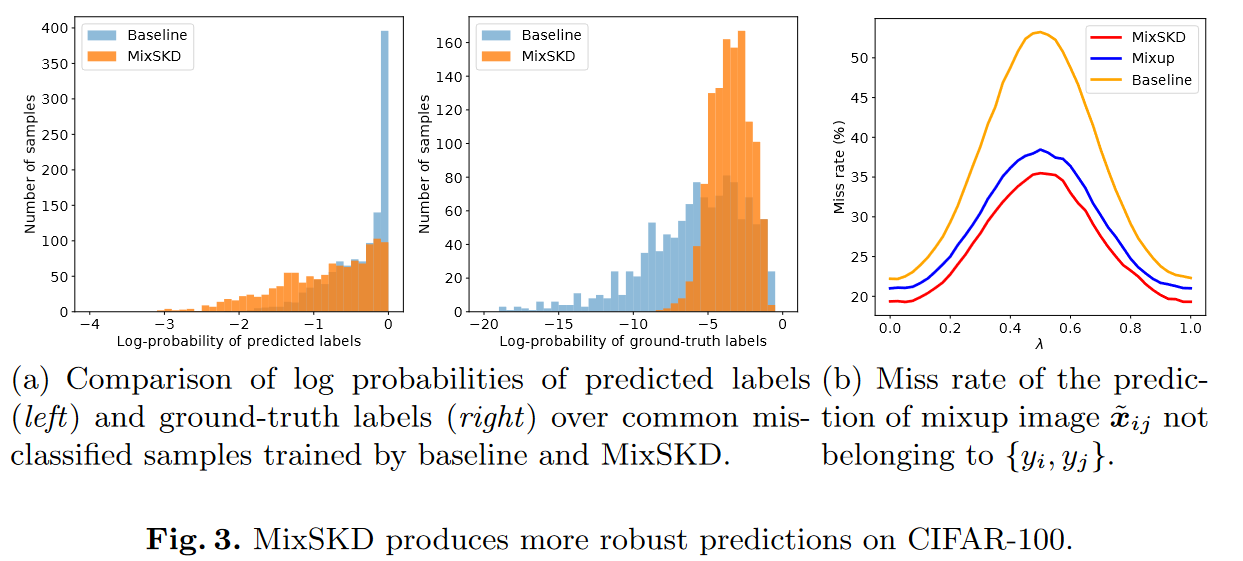
- 如下图所示,MixSKD用于大规模ImageNet图像识别并用于下游的目标检测和语义分割, 获得了最佳的表现。
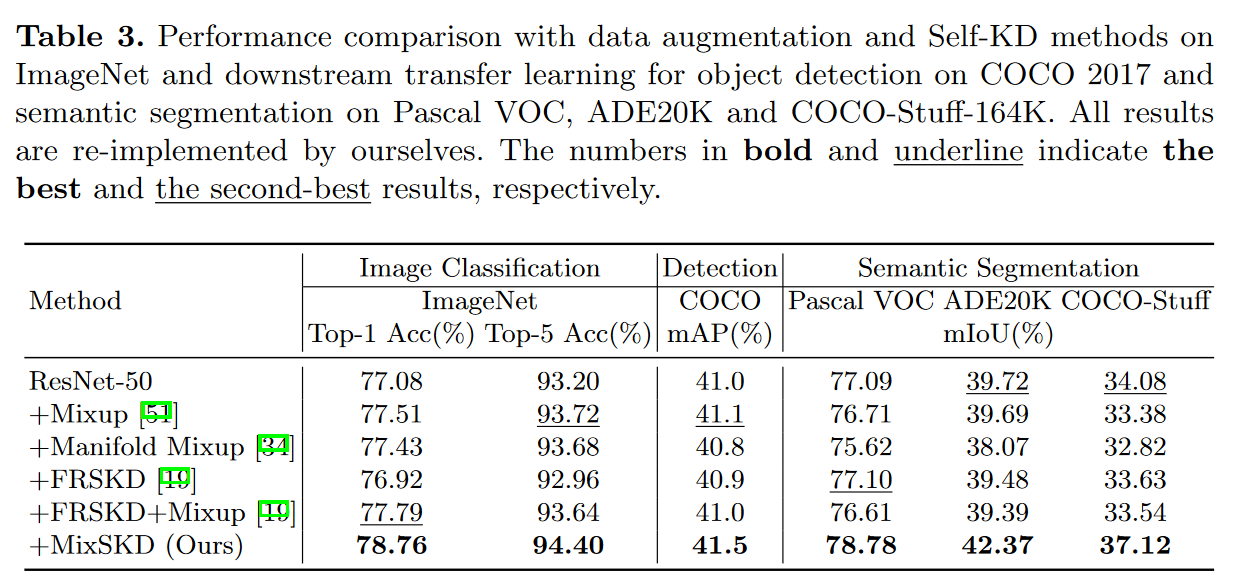
- 从左边两张图可以看出,MixSKD相比baseline具有更好的预测质量。对于公共分类错误的样本,MixSKD在错误类别概率上值更小,在正确类别概率上值更大。从第三张图上可以看出,在不同混合系数的混合图像下,MixSKD相比Mixup具有更低的错误率。
参考文献:
ECCV 2022 | MixSKD:用于图像识别的Mixup自蒸馏方法 - 知乎 (zhihu.com) 作者自己写的介绍文章,算是对原论文的翻译和概括

