综述文献阅读——A survey on Image Data Augmentation for Deep Learning
C. Shorten and T. M. Khoshgoftaar, ‘A survey on Image Data Augmentation for Deep Learning’, J Big Data, vol. 6, no. 1, p. 60, Dec. 2019, doi: 10.1186/s40537-019-0197-0.
较古早的综述论文,一共48页,reference只有4页,东西有点多(废话也不少),基础的内容占比不小。当时mixup问世1年多,没必要仔细扣细节,只作为后续工作思路的启发。
这个总结不只是这篇文章的阅读笔记,包括最近看到的一些其他工作和内容。
1. Introduction
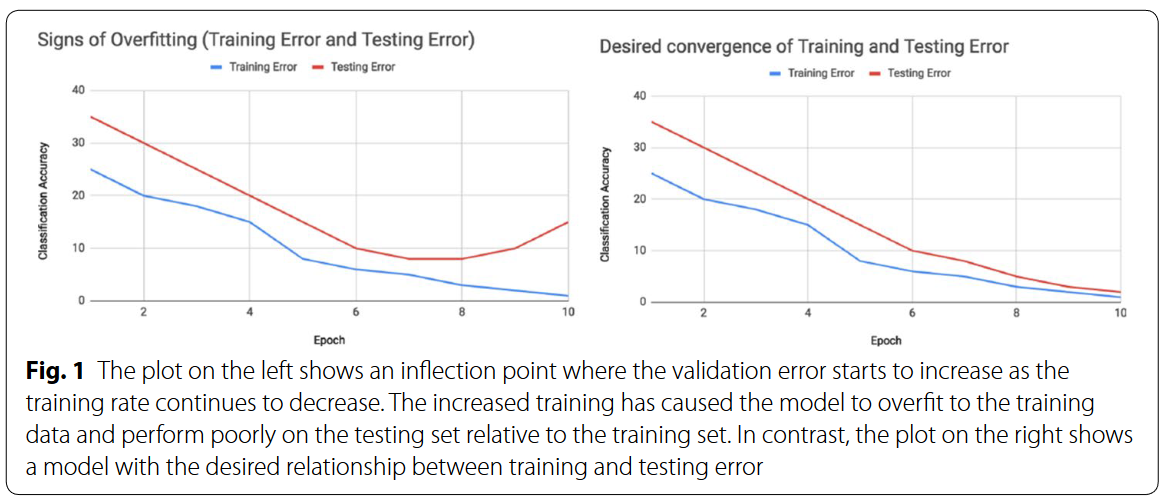
如上图,判断是否过拟合以及何时停止训练通过的是验证集loss,如果训练集loss持续减小但是验证集loss增大,就说明是过拟合了。
我觉得过拟合的根本在于学习了数据中涨落的噪声(或者说bias),在数据较少且模型性能较弱的时候,可能模型在学习较为常见的视图特征之后不会学习其他的有用视图信息,而是记住少数不能通过单视图来分类的数据本身,也就是记住了bias和噪声。比如人脸中的position,比如光线、时间、天气等等。(想法部分来自论文:Z. Allen-Zhu and Y. Li, ‘Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning’. arXiv, Jul. 03, 2021. Accessed: Nov. 30, 2022. [Online]. Available: http://arxiv.org/abs/2012.09816)
基于模型的过拟合解决方法,和数据增强
数据增强(Data Augmentation,DA)并不是唯一试图减弱过拟合的研究,许多提高泛化性的策略从网络本身结构出发,希望模型去学习general而不是special的特征,比如整个CNN的发展过程(AlexNet->VGG->ResNet->Inception-V3->DenseNet),还比如一些技术:
- Dropout: 我感觉这个就是一种bagging的正则化学习思路,强制网络不能只靠少数layer中的神经元和连接work,而是多个弱分类器ensemble后学习多视图信息(比如车轮,车窗车灯都能用来判断一辆车,这个想法也是来自 ”Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning“ ),而不是仅仅某个局部特征,避免学到少数视图之后就只学噪声不再泛化。
- Batch normalization:没什么好说的,我的理解是削减造成像素差异的噪声的正则化方法,得到稳定的分布,”a standard technique in the preprocessing of pixel values“。
- Transfer Learning:许多图像数据集共享低层次的空间特征,而大量数据可以更好地学习这些特征。所以复制原数据域训练好的模型的卷积层参数作为新数据域模型的初始参数很有效。
- Pretraining:可以使用大数据集初始化权重(就像迁移学习),同时不必完全继承整个模型结构(比迁移学习的好处)
- One-shot and Zero-shot learning:这个我不是很了解。One-shot learning常用于人脸识别(扫一次脸就要一直用),用的主要是siamese network和memory-augmented network。Zero-shot learning使用输入输出矢量embedding,比如Word2Vec 或者 GloVe
相比上面的结构和模型思路上的改进,DA希望从根源上解决问题。这是基于”可以通过增强从原始数据集中提取更多信息“的假设下进行的。这些增强通过数据扭曲(Data warping)或过采样(Oversampling)来扩大训练数据集的大小,这两者可以联合使用。
-
Data warping增强对现有图像进行转换,以保留其标签。这包括诸如几何和颜色转换、随机擦除、对抗性训练和神经风格转移等增强。
-
Oversampling增强创建合成实例并将其添加到训练集。这包括混合图像、特征空间增强和生成对抗网络(GANs)。
大概思维导图如下,在随后的篇幅中都有介绍:
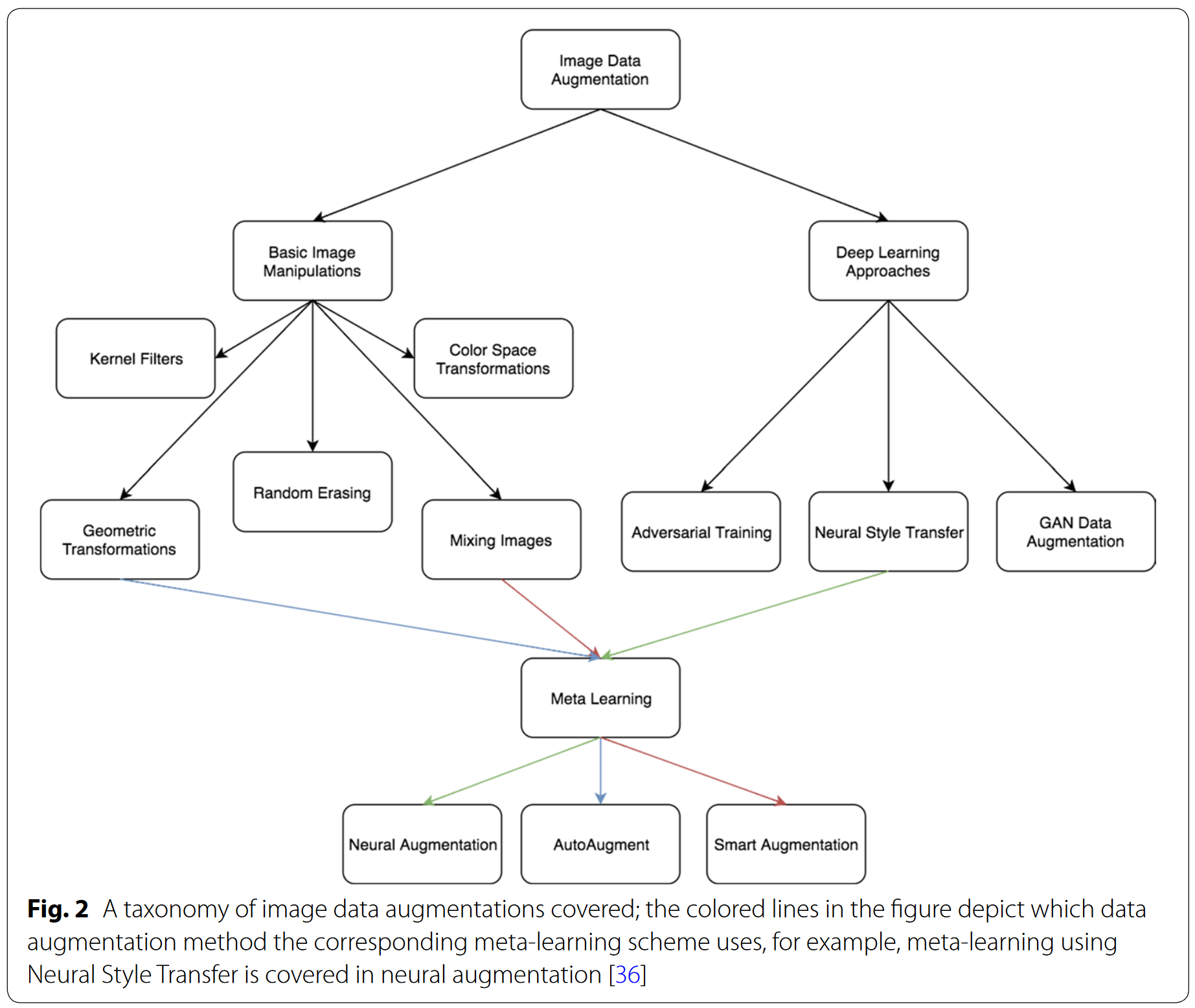
background:略,没什么重点
2. Image Data Augmentation techniques
2.1 Data Augmentations based on basic image manipulations
这样的操作要小心变换后的数据安全性问题,比如mnist里面9转一下变成6这种问题
-
Geometric transformations
如果数据集潜在的表征能够被观察和分离,那么简单的几何变换就能取得很好的效果。对于复杂的数据集如医学影像,数据小而且训练集和测试集的偏差大,几何变换等增强的合理运用就很关键。
-
Flipping
水平翻转比竖直翻转常见。作者提到了要衡量普遍性的观点,但是这种变换对于数字数据集不具有安全性。
-
Color space
主要提及的识别RGB通道上的变换
单独选一个channel,其他置0;增加减小亮度;修改颜色直方图中的intensity value等等来自参考博客的标注:颜色空间更多增强方式可以参考A Preliminary Study on Data Augmentation of Deep Learning for Image Classification
-
Cropping
通常在输入图片的尺寸不一时会进行按中心的裁剪操作。裁剪某种程度上和平移操作有相似性。根据裁剪幅度变化,该操作具有一定的不安全性。
-
Rotation
大幅度的旋转对数字集会有不安全性的考虑。
-
Translation
将图片上下左右移动,避免数据的positional bias。平移也需要合理设计。例如人脸识别数据集,目标在数据集都处于中间
移动留下的空间可以被固定数值0/255等填充;或是随机/高斯噪音 -
Noise injection
在像素上叠加高斯噪声。
-
Color space transformations
由于实际图像中一定存在光线偏差,所以光线的增强十分有必要
参考博客的批注:(但是IJCV的光流文章指出,3D建模的灯光增强实在是很难学习到,所以对于光线增强的效果不如几何也可能因为光线的复杂度更高,数据样本远远不够)。
色彩变换十分多样,如像素限制、像素矩阵变换、像素值颠倒等;灰度图和彩图相比,计算时间成本大大较少,但是据实验效果会下降一些,很明显因为特征的维度被降维了;还有尝试将RGB映射到其他的色彩空间进行学习,YUV,CMY.HSV等。
除了计算大内存消耗和时间长等缺点,色彩变换也面临不安全性,比如识别人脸的关键信息是黄白黑,但是大量增强出红绿蓝;或者黑夜导致看不清目标从而丢信息。颜色变换的增强方法是从色彩空间角度拟合偏置,效果有限的可能性是多样的:1. 真实几何多样性比颜色更简单 2. 色彩的变化多样性更多,导致增强不够反而学不好,颜色空间的欠拟合 3. 变换不安全 -
Experiment
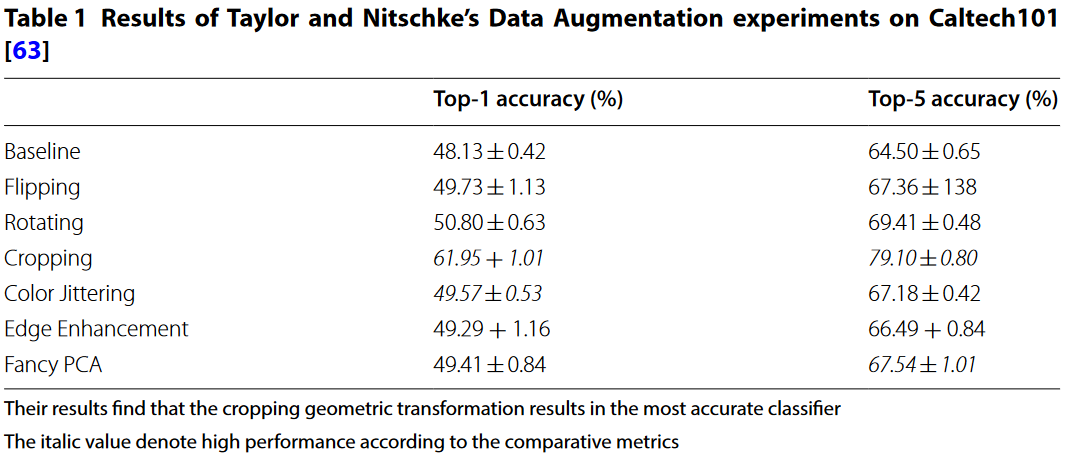
2.2 Geometric versus photometric transformations
-
Kernel filter
核滤波是图像处理中一种非常流行的图像锐化和模糊处理技术。
模糊化:使用高斯模糊filter在图像上滑动n×n矩阵
锐化:高对比度垂直/水平边filter。对模糊目标有更好鲁棒性
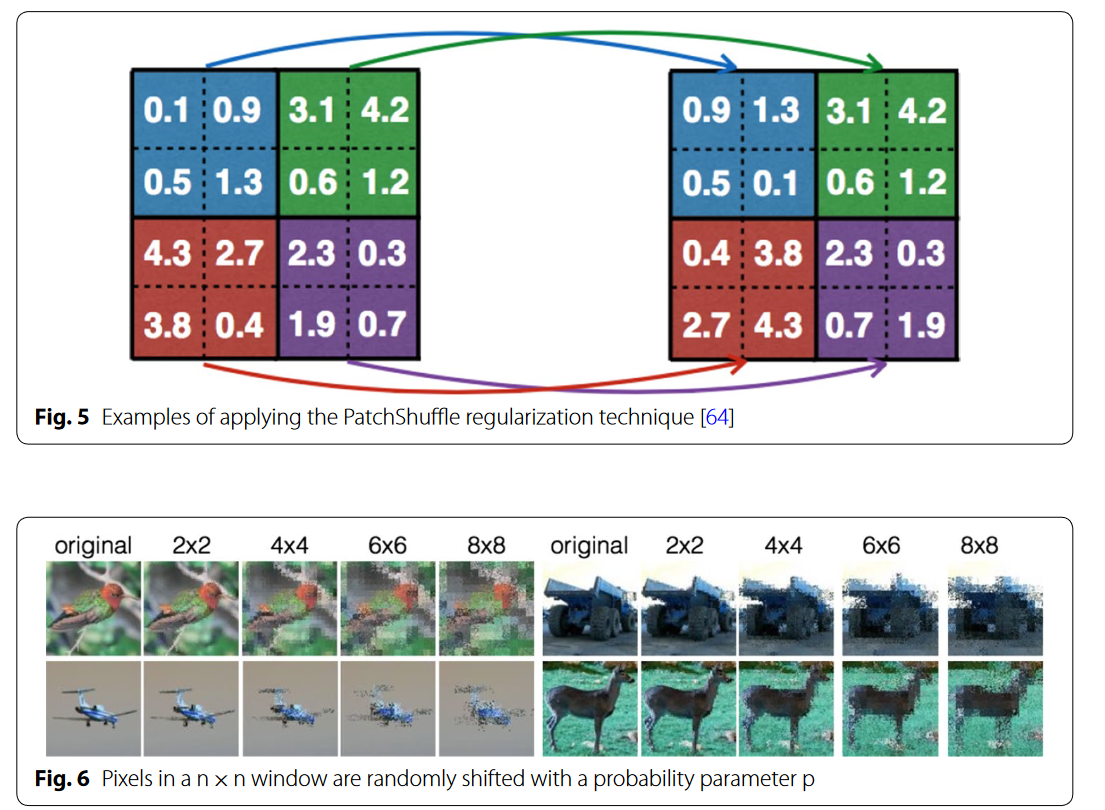
滤波器核在图像处理用的比较广,这里提到用这种方法来增强。还提到了一种正则化增强方法PatchShuffle,在一个patch内随机交换像素值,使得对噪声的抵抗更强以及避免过拟合。
文章指出关于应用滤波器增强的工作尚且不多,因为这种方法其实和CNN的机制是一样的,这么做也许还不如直接在原始CNN上加层加深网络。
-
Mixing images
-
pixel均值相加进行mix

-
mixup(ICLR2018)
随机融合两图片。假设有两样本\(x_1\)和\(x_2\),它们的标签为\(y_1\)和\(y_2\),我们可以使用下面的公式来生成一个新的样本\(x'\)和标签\(y'\):
\[x' = \lambda x_1 + (1 - \lambda) x_2 \]\[y' = \lambda y_1 + (1 - \lambda) y_2 \]\[Loss=\lambda L(f(x'),y_1)+(1-\lambda)L(f(x'),y_2)) \]很有效,但是有点反直觉,我现有的认识是给数据加了一个线性正则化
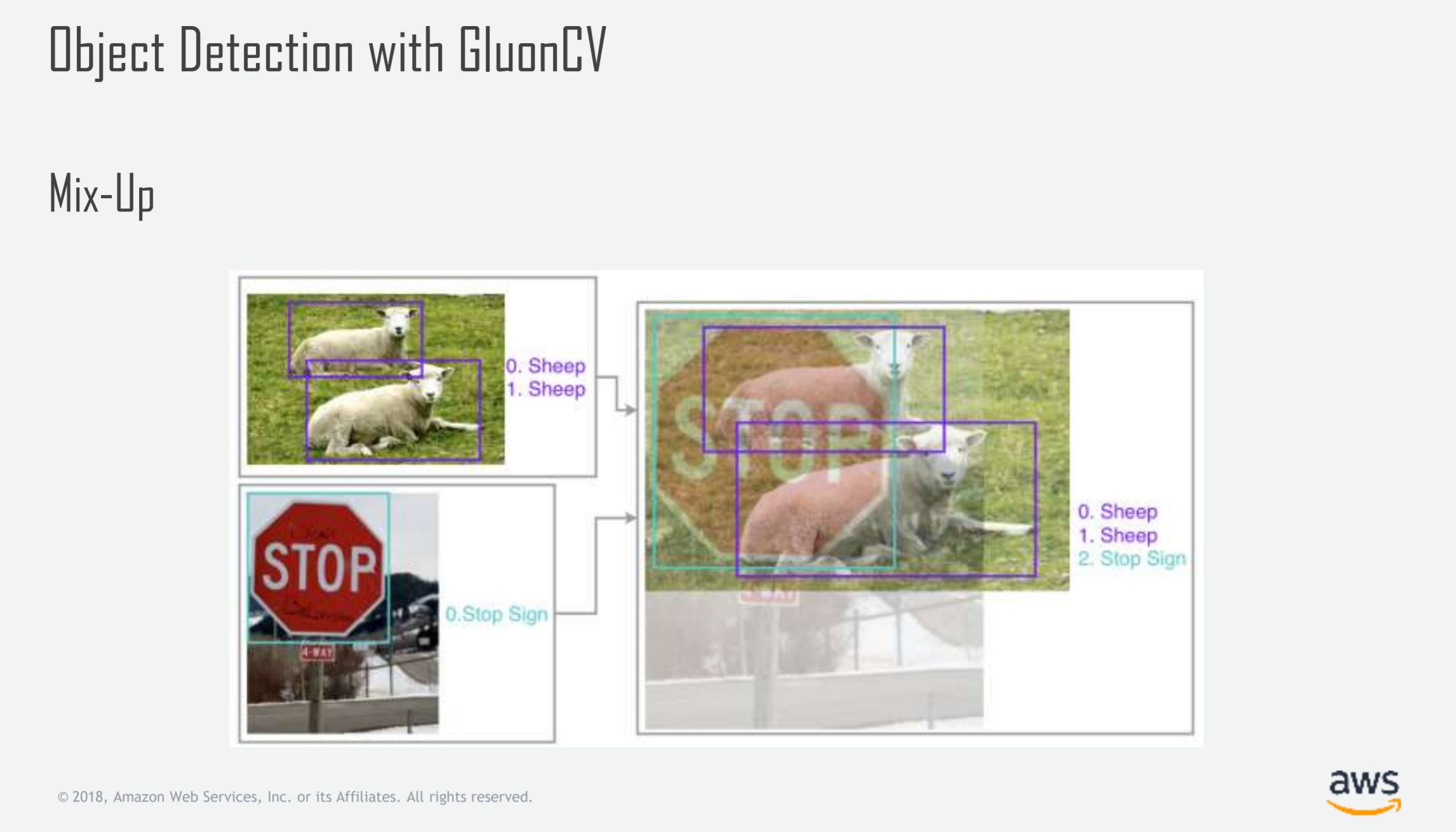
-
CutMix(ICCV2019)
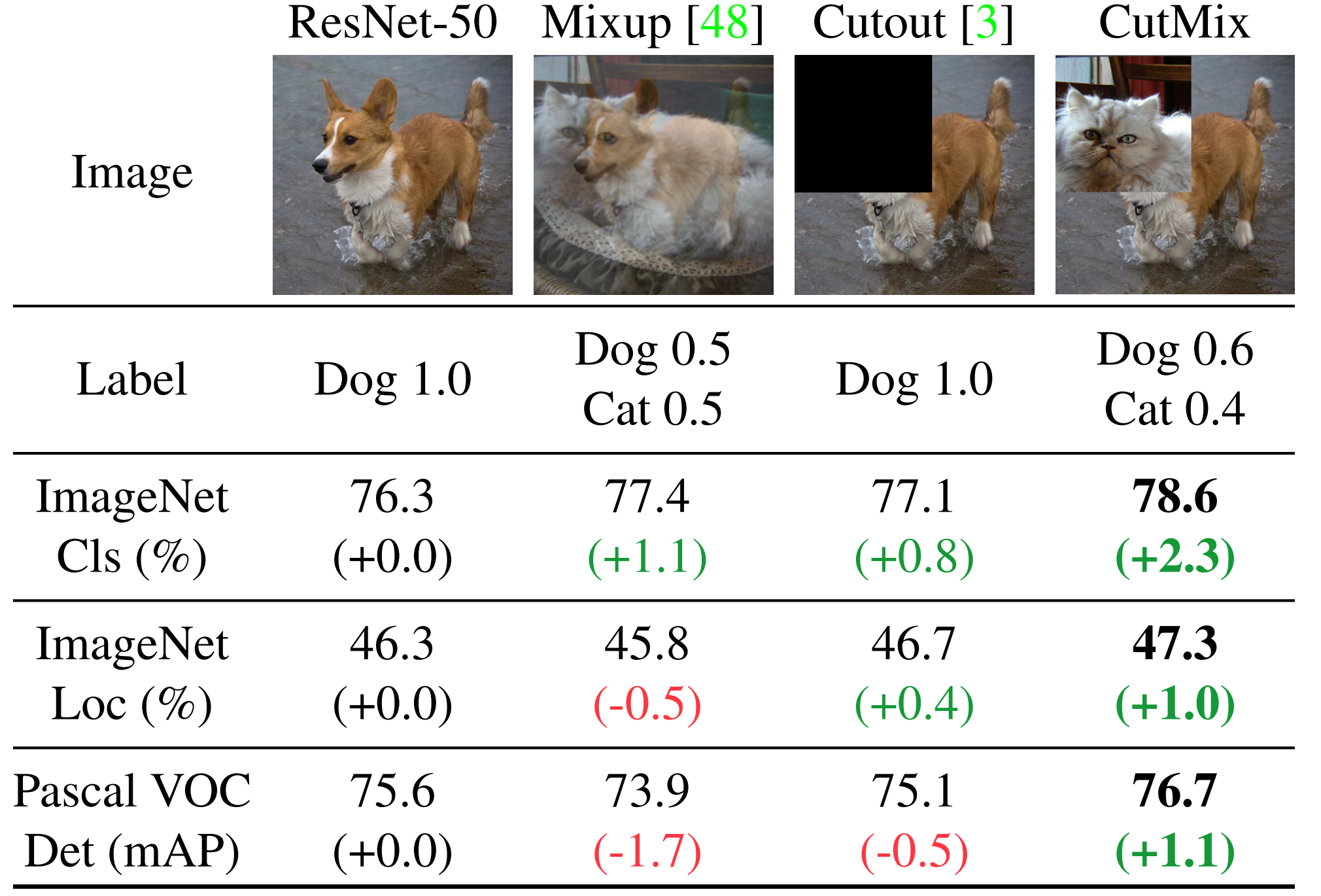
-
Mosaic data augentation(2020)
YOLO4用的方法,Random lmage Cropping and Patches

-
AugMix(ICLR2020)
DeepMind和谷歌提出,随机对图像进行不同的数据增强(Aug),然后混合(Mix)多个数据增强后的图像;同时在分类器上施加对同一图像的不同增强后的一致性约束
注意这里操作的是同一张图片

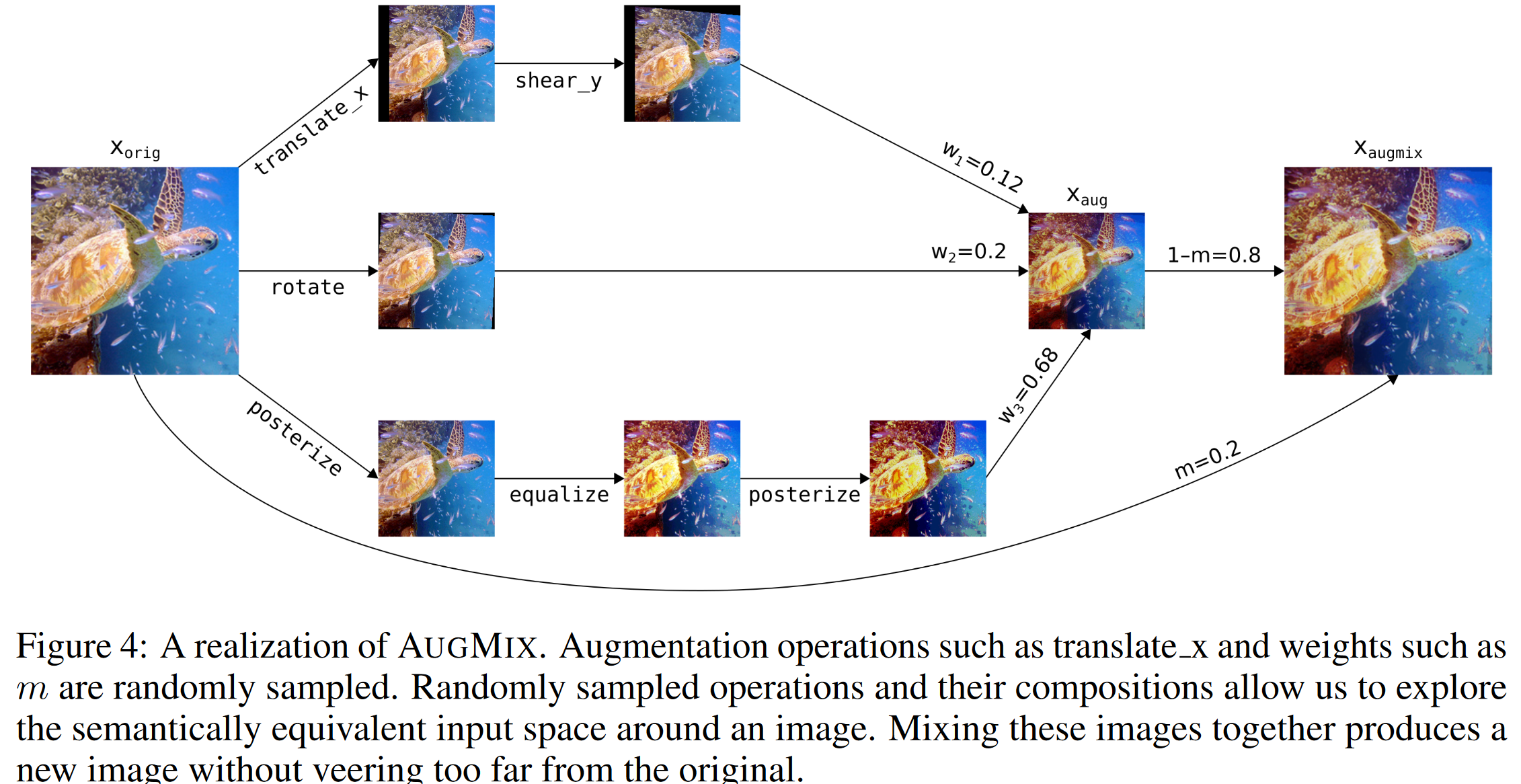
-
-
Random erasing
目的是使得网络关注整张图片,而不是部分内容
-
Cutout,2017
设计的时候本来的打算是:去除的区域不是随机的矩形区域,而是去掉输入图像中重要的特征。方法类似于maxdrop,目标删除重要区域,从而通过其他信息来获取分类结果,达到更好的模型泛化能力。
实现方法就是:每一轮都记录每张图片的maximally activated feature map,然后下一轮根据阈值删除指定区域。
但后来发现,随机删除区域的效果与这个复杂的方法差不多,也就是说删除区域面积的重要性远远大于mask的形状。
结果发现提点了,就这样,没了就这玩意能发论文,说明讲好一个故事,起个好名,有个好运气很重要 -
Random Erasing Data Augmentation,2017
厦大联合悉尼科大的一篇工作


Random Erasing(也可以被视为add noise的一种)。该方法被证明在多个CNN架构和不同领域中可以提升模型的性能和应对遮挡的鲁棒性,并且与随机裁剪、随机水平翻转(还有正则化方法)具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。
该方法可以很容易嵌入到现今大部分CNN模型中用于训练具有更好泛化性能的模型。一句话就是,随机删除矩形区域然后均值填充
,但是和上面的一样,故事讲得好作者写故事碰瓷dropout,通过矩形mask的随机遮挡使得网络能够提高遮挡情况的鲁棒性,与dropout不同的是 Random erasing 是在输入数据空间进行,而非是在网络结构中。这种方法也可以看着是在模拟遮挡的情况,以保证网络关注整个图像,而不是只关注其中的一个子集。
通常 erasing 的区域直接填充随机值效果更好。使用的时候需要注意是否标签安全,比如MNIST数据集”8“cutout后可能出问题,可能需要人为的加入一些限制,以保证标签的正确性。
也可以手工设计mask的大小以及生成方式-
GridMask Data Augmentation

GridMask是通过生成1个和原图相同分辨率的mask,然后将该mask和原图相乘得到一个GridMask增强后的图像。上图中灰色区域的值为1,黑色区域的值为0。通过将Mask和原图相乘,实现了特定区域的information dropping,本质可以理解成是一种实现正则化的方法。
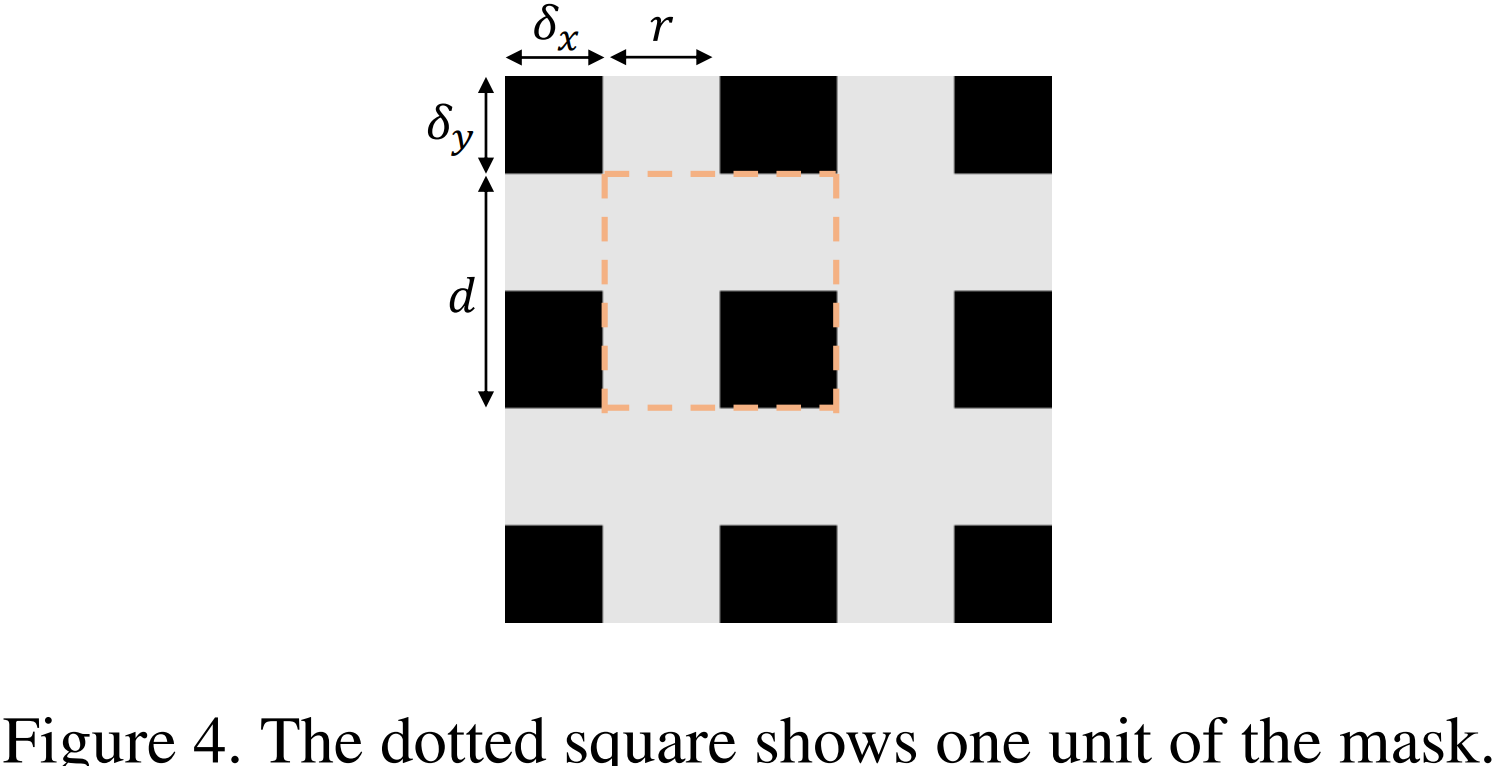
实际操作中还对mask进行了旋转
-
-
A note on combining augmentations
组合的增强方式往往是连续变化的,导致数据集的容量会迅速扩大,这对于小数据集领域来说容易发生过拟合 ,所以需要设计合理的搜索算法设计恰当的训练数据集。
2.3 Data Augmentations based on Deep Learning
不是我在意的内容,所以不做过多拓展
-
Feature space augmentation
-
Synthetic Minority Over-sampling Technique(SMOTE)
Auto-encoder,网络的一半将图片编码为低维特征,另一半将低维特征解码为图片。类别不平衡的过采样法来进行特征空间的插值操作:将样本A映射到低维空间,根据样本不平衡比例确定采样倍率N;对样本A,按欧式距离找出K个最近邻样本,从中随机选取一个样本B,在样本AB的连接段上随机选取一个作为新样本。
有点像mixup的做法,只不过是在feature(或者说latent space?)层面上的mix。就实验效果而言不算特别出众,data-space比feature-space效果好。
-
Adversarial training
我之前看到数据增强第一想到的就是这个。。。
对抗样本训练可以提高鲁棒性,但是实际应用中其实提高不一定明显,因为自然对抗样本的数目没有那么多。
-
Fast gradient sign method
通过在梯度方向上添加增量来诱导网络对生成的图片X”进行误分类,我们可以通过指定我们期待的分类使得网络针对任何输入图片均产生指定分类的对抗样本,同时也可以不指定期待的分类,只需要使得生成的图片被网络识别为与正确分类不同的分类即可。
-
Projected Gradient Descent (PGD)
在测试集上提高不强
-
GAN‑based Data Augmentation
感觉有点矛盾啊,因为数据不够而进行数据增强,然后GAN又要吃掉很多数据才能训练好descriminator。conditional GAN,DCGAN,CycleGAN甚至PDGAN或者DeFLOCNet(以生成diverse数据)啥的,理论上能做,但是总觉得不太好
-
Neural Style Transfer
貌似没有表现出特别好的效果,本身也不太感兴趣
-
Fast Style Transfer
-
Style Augmentation
-
Domain randomization for transferring deep neural networks from simulation to the real world
指出分割之间的差异比对显示的拟真更重要
-
Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming
-
-
Meta learning Data Augmentations
-
Neural augmentation
-
Smart augmentation
随机采样类内图片进行通道叠加然后输出融合图像,学通过梯度下降使得输出图像的类内差距减小(没考虑类间关系,可能也不便处理)。
-
AutoAugment
谷歌最早做的自学习增强方法,走的NAS的思路RL+RNN搜索增强空间,还有后来最近发的检测增强也是大同小异,基本就是换汤不换药,问题在于搜索空间太大,复现搜索过于依赖硬件条件(
普通实验室玩不起)
-
3. Design considerations for image Data Augmentation
-
Test-time augmentation
-
Curriculum learning
-
Resolution impact
-
Final dataset size
-
Alleviating class imbalance with Data Augmentation
参考链接

