
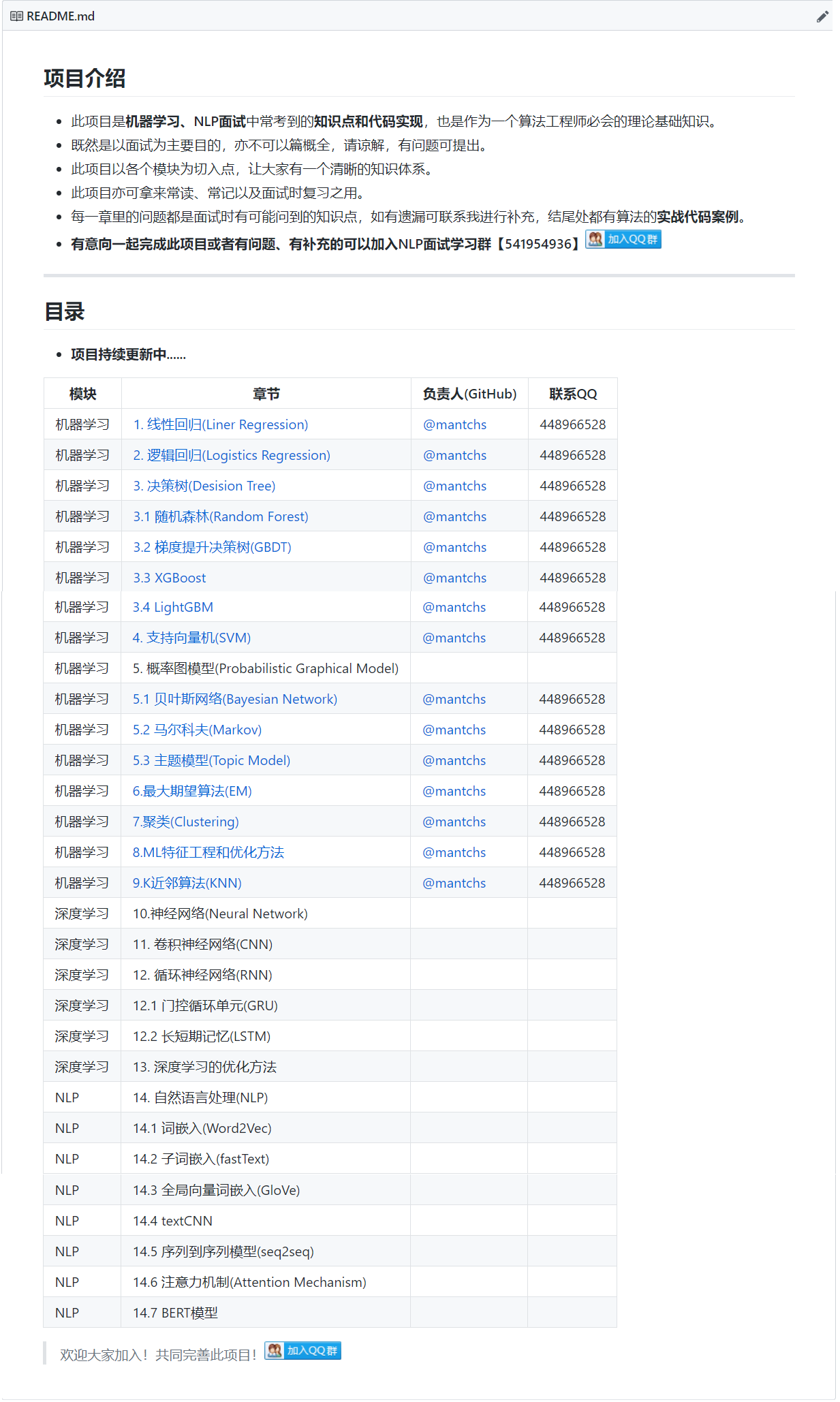
1. 什么是NLP
自然语言处理 (Natural Language Processing) 是人工智能(AI)的一个子领域。自然语言处理是研究在人与人交互中以及在人与计算机交互中的语言问题的一门学科。为了建设和完善语言模型,自然语言处理建立计算框架,提出相应的方法来不断的完善设计各种实用系统,并探讨这些实用系统的评测方法。
2. NLP主要研究方向
- 信息抽取:从给定文本中抽取重要的信息,比如时间、地点、人物、事件、原因、结果、数字、日期、货币、专有名词等等。通俗说来,就是要了解谁在什么时候、什么原因、对谁、做了什么事、有什么结果。
- 文本生成:机器像人一样使用自然语言进行表达和写作。依据输入的不同,文本生成技术主要包括数据到文本生成和文本到文本生成。数据到文本生成是指将包含键值对的数据转化为自然语言文本;文本到文本生成对输入文本进行转化和处理从而产生新的文本。
- 问答系统:对一个自然语言表达的问题,由问答系统给出一个精准的答案。需要对自然语言查询语句进行某种程度的语义分析,包括实体链接、关系识别,形成逻辑表达式,然后到知识库中查找可能的候选答案并通过一个排序机制找出最佳的答案。
- 对话系统:系统通过一系列的对话,跟用户进行聊天、回答、完成某一项任务。涉及到用户意图理解、通用聊天引擎、问答引擎、对话管理等技术。此外,为了体现上下文相关,要具备多轮对话能力。
- 文本挖掘:包括文本聚类、分类、情感分析以及对挖掘的信息和知识的可视化、交互式的表达界面。目前主流的技术都是基于统计机器学习的。
- 语音识别和生成:语音识别是将输入计算机的语音符号识别转换成书面语表示。语音生成又称文语转换、语音合成,它是指将书面文本自动转换成对应的语音表征。
- 信息过滤:通过计算机系统自动识别和过滤符合特定条件的文档信息。通常指网络有害信息的自动识别和过滤,主要用于信息安全和防护,网络内容管理等。
- 舆情分析:是指收集和处理海量信息,自动化地对网络舆情进行分析,以实现及时应对网络舆情的目的。
- 信息检索:对大规模的文档进行索引。可简单对文档中的词汇,赋之以不同的权重来建立索引,也可建立更加深层的索引。在查询的时候,对输入的查询表达式比如一个检索词或者一个句子进行分析,然后在索引里面查找匹配的候选文档,再根据一个排序机制把候选文档排序,最后输出排序得分最高的文档。
- 机器翻译:把输入的源语言文本通过自动翻译获得另外一种语言的文本。机器翻译从最早的基于规则的方法到二十年前的基于统计的方法,再到今天的基于神经网络(编码-解码)的方法,逐渐形成了一套比较严谨的方法体系。
3. NLP的发展
-
1950年前:图灵测试
1950年前阿兰·图灵图灵测试:人和机器进行交流,如果人无法判断自己交流的对象是人还是机器,就说明这个机器具有智能。 -
1950-1970:主流:基于规则形式语言理论
乔姆斯基,根据数学中的公理化方法研究自然语言,采用代数和集合论把形式语言定义为符号的序列。他试图使用有限的规则描述无限的语言现象,发现人类普遍的语言机制,建立所谓的普遍语法。
-
1970-至今:主流:基于统计
谷歌、微软、IBM,20世纪70年代,弗里德里克·贾里尼克及其领导的IBM华生实验室将语音识别率从70%提升到90%。
1988年,IBM的彼得·布朗提出了基于统计的机器翻译方法。
2005年,Google机器翻译打败基于规则的Sys Tran。 -
2010年以后:逆袭:机器学习
AlphaGo先后战胜李世石、柯洁等,掀起人工智能热潮。深度学习、人工神经网络成为热词。领域:语音识别、图像识别、机器翻译、自动驾驶、智能家居。
4. NLP任务的一般步骤
下面图片看不清楚的,可以百度脑图查看,点击链接

5. 我的NLP启蒙读本
6. NLP、CV,选哪个?
NLP:自然语言处理,数据是文本。
CV:计算机视觉,数据是图像。
两者属于不同的领域,在遇到这个问题的时候,我也是犹豫了很久,想了很多,于是乎得出一个结论:都是利用深度学习去解决现实世界存在的问题,离开了CV,NLP存活不了;离开了NLP,CV存活不了。两者就像兄弟姐妹一样,整个“家庭”不能分割但个体又存在差异!
NLP/CV属于两个不同的研究领域,都是很好的领域,可以根据自己的爱好作出适合自己的选择,人工智能是一个多学科交叉的领域,需要的不仅仅是单方面的能力,而是多方面的能力。对于每个人来说都有自己的侧重点,毕竟人的精力是有限的。只要在自己擅长的领域里持续深耕,我相信都会有所成就!
这里提供一些参考资料给大家阅读阅读,做出适合自己的选择:
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
欢迎大家加入讨论!共同完善此项目!群号:【541954936】



 浙公网安备 33010602011771号
浙公网安备 33010602011771号