
1. 什么是强化学习
其他许多机器学习算法中学习器都是学得怎样做,而强化学习(Reinforcement Learning, RL)是在尝试的过程中学习到在特定的情境下选择哪种行动可以得到最大的回报。在很多场景中,当前的行动不仅会影响当前的rewards,还会影响之后的状态和一系列的rewards。RL最重要的3个特定在于:
- 基本是以一种闭环的形式;
- 不会直接指示选择哪种行动(actions);
- 一系列的actions和奖励信号(reward signals)都会影响之后较长的时间。
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题 [1] 。

上图中agent代表自身,如果是自动驾驶,agent就是车;如果你玩游戏它就是你当前控制的游戏角色,如马里奥,马里奥往前走时环境就一直在发生变化,有小怪物或者障碍物出现,它需要通过跳跃来进行躲避,就是要做action(如向前走和跳起的动作);无人驾驶的action就是车左转、右转或刹车等等,它无时无刻都在与环境产生交互,action会反馈给环境,进而改变环境,如果自动驾驶的车行驶目标是100米,它向前开了10米,那环境就发生了变化,所以每次产生action都会导致环境改变,环境的改变会反馈给自身(agent),就是这样的一个循环;反馈又两种方式:
- 做的好(reward)即正反馈,
- 做得不好(punishment惩罚)即负反馈。
Agent可能做得好,也可能做的不好,环境始终都会给它反馈,agent会尽量去做对自身有利的决策,通过反反复复这样的一个循环,agent会越来越做的好,就像孩子在成长过程中会逐渐明辨是非,这就是强化学习。
2. 强化学习模型

如上图左边所示,一个agent(例如:玩家/智能体等)做出了一个action,对environment造成了影响,也就是改变了state,而environment为了反馈给agent,agent就得到了一个奖励(例如:积分/分数),不断的进行这样的循环,直到结束为止。
上述过程就相当于一个马尔可夫决策过程,为什么这样叫呢?因为符合马儿可夫假设:
- 当前状态 St 只由上一个状态 St-1 和行为所决定,而和前序的更多的状态是没有关系的。
上图右边所示,S0 状态经过了 a0 的行为后,获得了奖励 r1 ,变成了状态S1,后又经过了 a0 行为得到奖励 r2,变成了状态 S2 ,如此往复循环,直到结束为止。
2.1 打折的未来奖励
通过以上的描述,大家都已经确定了一个概念,也就是agent(智能体)在当下做出的决定肯定使得未来收益最大化,那么,一个马儿可夫决策过程对应的奖励总和为:
t 时刻(当下)的未来奖励,只考虑后面的奖励,前面的改变不了:
接下来,当前的情况下做出的动作是能够得到结果的,但对于未来的影响是一个不确定的,这也符合我们的真实世界,比如谁都不知道一只蝴蝶只是煽动了一次翅膀会造成飓风式的影响(蝴蝶效应)。所以,当前的行为对于未来是不确定性的,要打一个折扣,也就是加入一个系数gamma,是一个 0 到 1 的值:
离当前越远的时间,gamma的惩罚系数就会越大,也就是越不确定。为的就是在当前和未来的决策中取得一个平衡。gamma取 0 ,相当于不考虑未来,只考虑当下,是一种很短视的做法;而gamma取 1 ,则完全考虑了未来,又有点过虑了。所以一般gamma会取 0 到 1 之间的一个值。
Rt 可以用 Rt+1 来表示,写成递推式:
2.2 Q-Learning算法
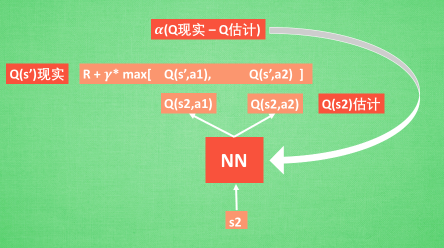
Q(s, a)函数(Quality),质量函数用来表示智能体在s状态下采用a动作并在之后采取最优动作条件下的打折的未来奖励(先不管未来的动作如何选择):
假设有了这个Q函数,那么我们就能够求得在当前 t 时刻当中,做出各个决策的最大收益值,通过对比这些收益值,就能够得到 t 时刻某个决策是这些决策当中收益最高。
于是乎,根据Q函数的递推公式可以得到:
这就是注明的贝尔曼公式。贝尔曼公式实际非常合理。对于某个状态来讲,最大化未来奖励相当于
最大化即刻奖励与下一状态最大未来奖励之和。
Q-learning的核心思想是:我们能够通过贝尔曼公式迭代地近似Q-函数。
2.3 Deep Q Learning(DQN)
Deep Q Learning(DQN)是一种融合了神经网络和的Q-Learning方法。
2.3.1 神经网络的作用
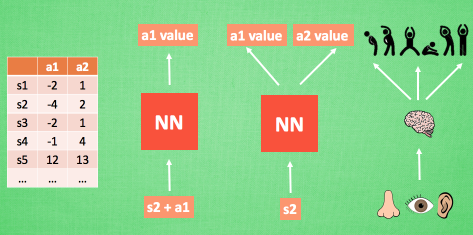
使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值. 而当今问题是在太复杂, 状态可以多到比天上的星星还多(比如下围棋). 如果全用表格来存储它们, 恐怕我们的计算机有再大的内存都不够, 而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事. 不过, 在机器学习中, 有一种方法对这种事情很在行, 那就是神经网络.
我们可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值.
还有一种形式的是这样, 我们也能只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作.
我们可以想象, 神经网络接受外部的信息, 相当于眼睛鼻子耳朵收集信息, 然后通过大脑加工输出每种动作的值, 最后通过强化学习的方式选择动作.
2.3.2 神经网络计算Q值
这一部分就跟监督学习的神经网络一样了我,输入状态值,输出为Q值,根据大量的数据去训练神经网络的参数,最终得到Q-Learning的计算模型,这时候我们就可以利用这个模型来进行强化学习了。
3. 强化学习和监督学习、无监督学习的区别
-
监督式学习就好比你在学习的时候,有一个导师在旁边指点,他知道怎么是对的怎么是错的。
强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
-
监督式学习出的是之间的关系,可以告诉算法什么样的输入对应着什么样的输出。监督学习做了比较坏的选择会立刻反馈给算法。
强化学习出的是给机器的反馈 reward function,即用来判断这个行为是好是坏。 另外强化学习的结果反馈有延时,有时候可能需要走了很多步以后才知道以前的某一步的选择是好还是坏。
-
监督学习的输入是独立同分布的。
强化学习面对的输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入。
-
监督学习算法不考虑这种平衡,就只是 exploitative。
强化学习,一个 agent 可以在探索和开发(exploration and exploitation)之间做权衡,并且选择一个最大的回报。
-
非监督式不是学习输入到输出的映射,而是模式(自动映射)。
对强化学习来说,它通过对没有概念标记、但与一个延迟奖赏或效用(可视为延迟的概念标记)相关联的训练例进行学习,以获得某种从状态到行动的映射。
强化学习和前二者的本质区别:没有前两者具有的明确数据概念,它不知道结果,只有目标。数据概念就是大量的数据,有监督学习、无监督学习需要大量数据去训练优化你建立的模型。
| 监督学习 | 非监督学习 | 强化学习 | |
|---|---|---|---|
| 标签 | 正确且严格的标签 | 没有标签 | 没有标签,通过结果反馈调整 |
| 输入 | 独立同分布 | 独立同分布 | 输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入。 |
| 输出 | 输入对应输出 | 自学习映射关系 | reward function,即结果用来判断这个行为是好是坏 |
4. 什么是多任务学习
在机器学习中,我们通常关心优化某一特定指标,不管这个指标是一个标准值,还是企业KPI。为了达到这个目标,我们训练单一模型或多个模型集合来完成指定得任务。然后,我们通过精细调参,来改进模型直至性能不再提升。尽管这样做可以针对一个任务得到一个可接受得性能,但是我们可能忽略了一些信息,这些信息有助于在我们关心的指标上做得更好。具体来说,这些信息就是相关任务的监督数据。通过在相关任务间共享表示信息,我们的模型在原始任务上泛化性能更好。这种方法称为多任务学习(Multi-Task Learning)
在不同的任务中都会有一些共性,而这些共性就构成了多任务学习的一个连接点,也就是任务都需要通过这个共性能得出结果来的。比如电商场景中的点击率和转化率,都要依赖于同一份数据的输入和神经网络层次。多语种语音识别等。

5. 参考文献
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
欢迎大家加入讨论!共同完善此项目!群号:【541954936】



 浙公网安备 33010602011771号
浙公网安备 33010602011771号