
Python3 读取csv文件
使用pandas 读取csv文件前几行数据
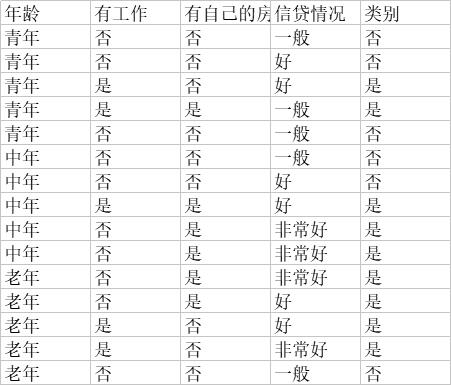
文件内容如下:
先读取标题:
import pandas as pd path = r'C:\Users\dhw\Desktop\work\term paper\Home work_10\TREE.csv' def opendata(path): df = pd.read_csv(path) list_label = df.columns.values #cloumns 为csv文件的标题 print(df) print(list_label) opendata(path)
读取前几行数据:
import pandasas pd data = pd.read_csv(path,nrows =5) print(data)
将csv文件转化为list
import pandas as pd path = r'C:\Users\dhw\Desktop\work\term paper\Home work_10\TREE.csv' def opendata(path): df = pd.read_csv(path) list_label = df.columns.values list_data =df.values.tolist() print(list_data) opendata(path) #[['青年', '否', '否', '一般', '否'],
['青年', '否', '否', '好', '否'],
['青年', '是', '否', '好', '是'],
['青年', '是', '是', '一般', '是'],
['青年', '否', '否', '一般', '否'],
['中年', '否', '否', '一般', '否'],
['中年', '否', '否', '好', '否'],
['中年', '是', '是', '好', '是'],
['中年', '否', '是', '非常好', '是'],
['中年', '否', '是', '非常好', '是'],
['老年', '否', '是', '非常好', '是'],
['老年', '否', '是', '好', '是'],
['老年', '是', '否', '好', '是'],
['老年', '是', '否', '非常好', '是'],
['老年', '否', '否', '一般', '否']]
删除csv文件的某一列
方法一:直接del DF['column-name']
方法二:采用drop方法,有下面三种等价的表达式:
1. DF= DF.drop('column_name', 1);
2. DF.drop('column_name',axis=1, inplace=True)
3. DF.drop([DF.columns[[0,1, 3]]], axis=1,inplace=True) # Note: zero indexed
import pandas as pd path = r'C:\Users\dhw\Desktop\work\term paper\Home work_10\TREE.csv' def opendata(path): df = pd.read_csv(path) df_delete = df.drop('类别',1)#删除类别这一列 list_label = df.columns.values list_data =df_delete.values.tolist() print(list_data) return list_label,list_data opendata(path)
ps:凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换。也就是说,采用inplace=True之后,原数组名(如2和3情况所示)对应的内存值直接改变;而采用inplace=False之后,原数组名对应的内存值并不改变,需要将新的结果赋给一个新的数组或者覆盖原数组的内存位置(如1情况所示)。
posted on 2018-08-13 09:45 MannerMaktheMan 阅读(9479) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号