

Spark基础
1 Spark简介
1.1 Spark介绍
- 什么是Spark
- Apache Spark is an open source cluster computing system that aims to make data analytics fast.(Apache Spark是一个开源集群计算系统,旨在快速进行数据分析)
- Both fast to run and fast to write.(读得快写得也快)
- Spark是专为大规模数据处理而合计得快速通用得计算引擎。
- Spark可以完成各种运算,包括SQL查询、文本处理、机器学习等。
- Spark由Scala语言开发,能够和Scala紧密结合。
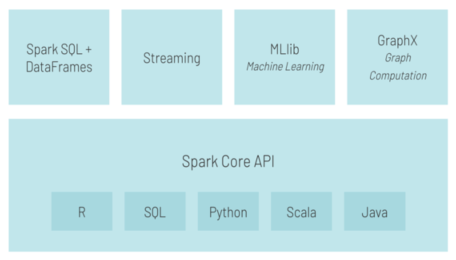
1.2 Spark组件
- Spark包括一下几个部分:
-
- Spark Core核心底层部分
- 基于RDD
- 支持多种语言
-
- Spark SQL
- 基于DataFrame
- 结构化数据查询
-
- Spark Streming流处理
-
- Spark MLLib机器学习
-
- Spark GraphX图计算
-
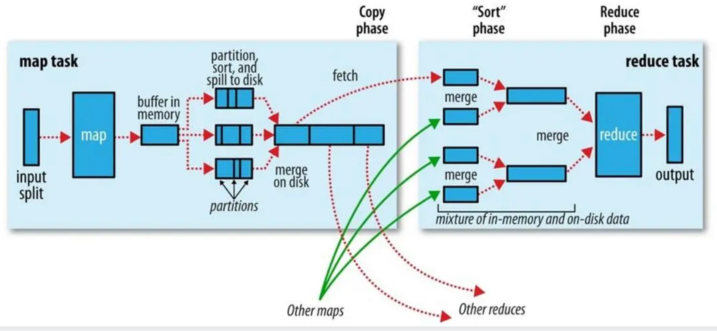
1.3 MapReduce回顾
在产生map之前,会将一个block进行逻辑上的划分,产生split切片,一个切片对应一个map,切片数量决定map任务数量。而切片的大小默认是128M,但是又10%的溢出率,故最后一个切片的大小默认情况下的范围是0~140.8M。
数据进入Map任务之前需要被格式化成KV格式。将每一条数据的偏移量作为key,一行数据作为value。
当切片和格式化完成后,就可以执行Map任务了。数据会依次逐条传入Map任务中。
当数据被Map任务处理完之后会先写到环形缓冲区中,根据最终reduce的个数,会对每一个数据键值对的Key进行哈希取余,这只一个编号,叫做分区编号,同时会对这个80%的数据内部先进行一个排序(快速排序,环形缓冲区是基于内存设计的)。环形缓冲区默认大小为100M,当达到80%的时候,开始形成一个小文件向磁盘溢写,边向磁盘溢写,边接收新的数据。一个map任务可能会产生多个小文件。当所有的数据写完之后,会将环形缓冲区产生的结果小文件进行合并操作。这个合并操作底层数据结构算法是归并排序。
reduce会根据分区编号对每一组数据进行计算,有多少个reduce就会产生多少个最终结果文件。
其中从Map之后到Reduce计算之前的过程可以理解为shuffle,shuffle就是让相同的Key进入同一个reduce中。
1.4 Spark VS MapReduce
- 任务粒度上看
Spark:
- Spark的任务是多线程模式。
- 优点是:任务启动速度和切换速度快,适合低延迟任务;任务在同一进程空间,共享该空间的内存,适合内存密集型任务;同结点所在的任务在JVM(executor)中,被进程占用的数据可以反复调用。
- 缺点:同节点所在的任务在JVM(executor)进程中运行可能会出现严重的资源竞争,稳定性不强。
MapReduce:
- MR的任务是多进程模式,启动时间长,不合适。
- 优点是:MR各个进程(Map或Reduce)是隔离的,保证了任务的稳定性。
- 缺点是:启动时间长,不适合做低延迟任务
- 从开发成本上看
Spark:
Spark开发成本低,开发效率更高
MapReduce:
MR开发成本高,开发效率低
- 从资源占用和释放情况上看
Spark:
Spark任务由于运行在同一进程空间,占用同一块的资源,假设有两个任务在一个进程空间运行,第一个任务运行完成之后,其所占用的资源得到释放,第二个任务独享整个进程空间资源直到其执行完成才释放资源。
MapReduce:
MR由于其任务是进程级别的,假设有Map和Reduce两个任务正在运行。Map任务运行完成后,释放其占用的进程资源,而Reduce任务占用的资源没有变化,依然是其任务所在的进程空间的资源。
1.5 Spark部署方式
- Spark支持多种部署模式
- Local 本地模式
多用于本地开发、本地测试- Standalone
(1) Spark自带的资源管理框架
(2) 可独立于其他大数据组件运行- Mesos
(1) 开源的资源管理系统
(2) 支持各种应用- Kubernetes
(1) Google开源的一个容器编排引擎
(2) 可移植性、可扩展性、自动化- Yarn
(1) Hadoop自带资源管理框架
(2) 贴合大数据生态
(3) 更具前景
2 Spark环境搭建
https://www.cnblogs.com/manmc/p/17456551.html
3 Spark核心
3.1 Spark框架
从下图可见主要有Driver、Spark Context/Session、Cluster Manager、Executor几个组建
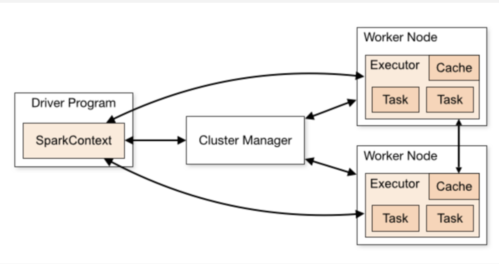
- Driver是一个JVM进程
- 负责执行Spark任务的main方法
- 执行用户提交的代码,创建SparkContext或者SparkSession
- 将用户代码转化为Spark任务(Jobs)创建血缘(Lineage),逻辑计划(Logical Plan)和物理计划(Physical Plan)
- 在Cluster Manager的辅助下,把task任务分发调度出去
- 跟踪任务的执行情况,收集日志
- Spark Context/Session
- 它是由Spark Driver 创建,每个Spark应用对应一个
- 程序和集群交互的入口
- 可以连接到Cluster Manager
- Cluster Manager
- 负责部署整个Spark集群
- 包括上面提到的driver和executors
- 具有一下几种常见的部署模式:Standalone、Yarn、Mesos、Kubernetes
- Executor
- 一个创建在worker节点的进程
- 一个Executor有多个slots(线程)
- 一个slot就是一个线程对应一个task
- 可以并发执行多个tasks
- 负责执行Spark任务,把结果返回给Driver
- 可以将数据缓存到worker节点的内存
3.2 RDD的五大特征
RDD(弹性分布式数据集),为Spark提供的一种编程模式,使用起来类似Scala中的List集合,但是RDD中不保存数据
- RDD具有一下五个特性:
- RDD是由一系列分区组成的
- Task是作用在每个分区上的,每个分区至少需要一个Task
- RDD之间是有一系列依赖关系的,可以按有无Shuffle分为:宽依赖、窄依赖
- 分区器是作用在KV格式的RDD上的
- Spark为每个Task尽可能地提供最佳计算位置,移动计算,不移动数据
-
如何判断宽窄依赖
- 站在父RDD的角度去看
- 如果父RDD的每个分区和子RDD的每个分区是一一对应的,则父RDD和子RDD之间是窄依赖
- 如果父RDD的每个分区和子RDD的每个分区是一对多的关系,则父RDD和子RDD之间是宽依赖
- 站在父RDD的角度去看
-
请区分图中各种操作对应的依赖关系
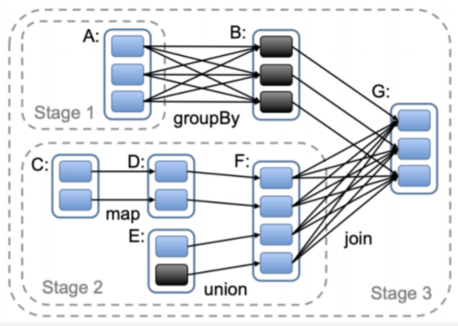
- 窄依赖:map、union
- 宽依赖:groupBy、join
- 基于有无Shuffle可区分为款窄依赖
- 基于款窄依赖可划分不同的Stage
- Stage(阶段):一组九二一并行计算的Task
4 Spark常用算子
4.1 代码结构
- Spark代码可以分为三个部分
- 读取数据,得到第一个RDD
- 处理数据,RDD之间的相互转换
- 保存数据,将RDD保存到存储系统
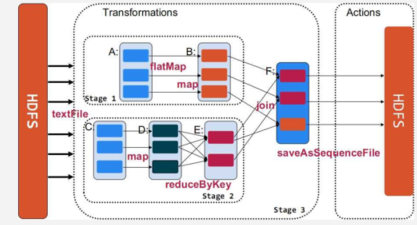
4.2 算子分类
- Spark算子大智可以分为一下两类:
- Transformation 变换/转换算子,该类型还可以继续细分
- 基于Value数据类型的Transformation算子
- 例如:map、flatMap、filter等
- 基于Key-Value数据类型的Transformation算子
- 例如:groupByKey、reduceByKey、join等
- 转换算子并不会出发提交作业,需要由Action算子出发执行(懒依赖)
- 基于Value数据类型的Transformation算子
- Action行动算子
- 该类算子会出发SparkContext提交Job作业
- 一个Action算子对应一个Job
- 例如:foreach、count、take、collect、reduce等
- Transformation 变换/转换算子,该类型还可以继续细分
4.3 算子讲解
4.3.1 基于value类型的Transformation转换算子
map
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo03Map {
/**
* Spark中的基于RDD的方法可以称之为算子
* 算子可以分为两类:
* 1、转换算子:RDD与RDD直接的转换
* 2、行为算子:每一个行为算子就会触发一个Job
* 转换算子是懒执行的,如果没有行为算子触发,那么转换算子是不会被执行的
* 如何区分转换算子和行为算子?
* 观察调用算子之后返回的类型,如果是RDD则该算子是转换算子,如果是其他数据类型则该算子是行为算子
*/
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4, 5)
list.map(i => {
println("map方法被执行了")
i
}).foreach(println)
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo03Map")
val sc: SparkContext = new SparkContext(conf)
// 通过Scala中的集合构建RDD
val listRDD: RDD[Int] = sc.parallelize(list)
listRDD
/*
* map 方法需要接收一个函数f
* 函数f:Int => 自定义类型
* Int类型同RDD中的每一条数据的类型有关
* 函数f的返回值类型由自己决定
* 传入一条数据返回一条数据
*/
.map(i => {
println("RDD的map方法被执行了")
i
}).foreach(println)
}
}
flatMap
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo04FlatMap {
def main(args: Array[String]): Unit = {
/**
* flatMap:转换算子,需要接收一个函数f
* 返回值类型有特殊要求,必须是数组或者是集合类
* 会对返回的数组或者是集合进行扁平化处理,即展开
* 传入一条数据返回多条数据
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo04FlatMap")
val sc: SparkContext = new SparkContext(conf)
val wordList: List[String] = List[String]("java,java,java", "scala,scala", "python")
val lineRDD: RDD[String] = sc.parallelize(wordList)
lineRDD.flatMap(line=>line.split(",")).foreach(println)
}
}
filter
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo05Filter {
def main(args: Array[String]): Unit = {
/**
* filter:转换算子,可以实现对RDD的数据进行过滤
* 需要接受一个函数f,返回值类型必须是布尔类型
* 如果返回的是true,则保留数据
* 如果返回的是false,则过滤数据
*/
// 基于students.txt数据,过滤出理科五班的所有学生
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo05Filter")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("spark/data/stu/students.txt")
stuRDD.filter(stu => stu.split(",")(4) == "理科五班").foreach(println)
}
}
sample
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo06Sample {
def main(args: Array[String]): Unit = {
/**
* sample:转换算子,用于对数据进行抽样
* 可以接收三个参数:
* withReplacement:有无放回
* fraction:抽样比例,小数,最终返回的数据条数并不固定,但是差别不大,在一个数量级
* seed:随机数种子,如果该值固定,则每次抽样的结果不变,默认等于随机的一个Long类型值
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo06Sample")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("spark/data/stu/students.txt")
// 对学生数据进行抽样,无放回,抽样10条数据
stuRDD.sample(withReplacement = false, fraction = 0.01, seed = 1).foreach(println)
}
}
Unoin
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo07Union {
def main(args: Array[String]): Unit = {
/**
* union:转换算子,类似SQL中的union all
* 可以将两个同类型的RDD进行合并
* Spark中的union操作并不会对数据进行去重
* 如果需要去重可以使用distinct算子
*
* distinct:转换算子,可以对RDD的数据进行去重
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo07Union")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("spark/data/stu/students.txt")
val stuRDD01: RDD[String] = stuRDD.sample(withReplacement = false, fraction = 0.01, seed = 1)
println(stuRDD01.getNumPartitions)
val stuRDD02: RDD[String] = stuRDD.sample(withReplacement = false, fraction = 0.01, seed = 1)
println(stuRDD02.getNumPartitions)
// union之后得到的RDD分区数等于两个RDD分区数之和
val unionRDD: RDD[String] = stuRDD01.union(stuRDD02)
println(unionRDD.getNumPartitions)
unionRDD.foreach(println)
val distinctUnionRDD: RDD[String] = unionRDD.distinct()
distinctUnionRDD.foreach(println)
}
}
cartesain(笛卡尔积)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo08Cartesian {
def main(args: Array[String]): Unit = {
/**
* cartesian:转换算子
* 可以对两份数据做笛卡尔积
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo08Cartesian")
val sc: SparkContext = new SparkContext(conf)
val intList: List[Int] = List[Int](1, 2, 3, 4, 5)
val strList: List[String] = List[String]("a","b","c")
val intRDD: RDD[Int] = sc.parallelize(intList)
val strRDD: RDD[String] = sc.parallelize(strList)
val cartesianRDD: RDD[(Int, String)] = intRDD.cartesian(strRDD)
cartesianRDD.foreach(println)
}
}
groupBy
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo09GroupBy {
def main(args: Array[String]): Unit = {
/**
* groupBy:转换算子
* 需要通过函数指定一个字段进行分组
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo09GroupBy")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[Stu] = sc
.textFile("spark/data/stu/students.txt")
.map(line => {
val splits: Array[String] = line.split(",")
Stu(splits(0), splits(1), splits(2).toInt, splits(3), splits(4))
})
// 按照班级分组
val stuGrpRDD: RDD[(String, Iterable[Stu])] = stuRDD.groupBy(_.clazz)
stuGrpRDD.foreach(println)
// 统计班级人数
stuGrpRDD
.map(kv => s"${kv._1},${kv._2.size}")
.foreach(println)
}
case class Stu(id: String, name: String, age: Int, gender: String, clazz: String)
}
4.3.2 基于key-value类型的Transformation转换算子
groupByKey
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo10GroupByKey {
def main(args: Array[String]): Unit = {
/**
* groupByKey:转换算子
* 首先只有KV格式的RDD才能调用groupByKey算子
* 可以将KV格式的RDD按照Key进行分组
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo10GroupByKey")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[Stu] = sc
.textFile("spark/data/stu/students.txt")
.map(line => {
val splits: Array[String] = line.split(",")
Stu(splits(0), splits(1), splits(2).toInt, splits(3), splits(4))
})
// 将数据变成KV格式
// 按照班级分组
val stuKVRDD: RDD[(String, Stu)] = stuRDD.map(stu => (stu.clazz, stu))
val stuGrpRDD: RDD[(String, Iterable[Stu])] = stuKVRDD.groupByKey()
stuGrpRDD.foreach(println)
// 统计班级人数
stuGrpRDD
.map(kv => s"${kv._1},${kv._2.size}")
.foreach(println)
}
case class Stu(id: String, name: String, age: Int, gender: String, clazz: String)
}
reduceByKey
import com.shujia.core.Demo09GroupBy.Stu
import com.shujia.core.Demo10GroupByKey.Stu
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo11ReduceByKey {
def main(args: Array[String]): Unit = {
/**
* reduceByKey:转换算子 需要接收一个聚合函数
* 首先只有KV格式的RDD才能调用reduceByKey算子
* 可以将KV格式的RDD按照Key进行分组并且同时进行聚合操作
* 聚合操作需要通过函数进行传入
* 同时也会将聚合函数用于预聚合
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo11ReduceByKey")
val sc: SparkContext = new SparkContext(conf)
// 按照班级分组并且统计班级人数
val stuKVRDD: RDD[(String, Int)] = sc
.textFile("spark/data/stu/students.txt")
// 将数据变成KV格式,以班级作为Key,1作为Value
.map(line => {
val splits: Array[String] = line.split(",")
(splits(4), 1)
})
stuKVRDD
.groupByKey()
.map(kv => {
val clazz: String = kv._1
// val cnt: Int = kv._2.size
val cnt: Int = kv._2.sum
s"$clazz,$cnt"
}).foreach(println)
// 使用reduceByKey进行简化
stuKVRDD
// reduceByKey无法直接完成avg聚合操作
// reduceByKey 可以实现预聚合操作
// .reduceByKey((i1: Int, i2: Int) => i1 + i2)
.reduceByKey(_ + _) // 基于匿名函数的省略规则进行简化
.map(kv => s"${kv._1},${kv._2}")
.foreach(println)
// 使用aggregateByKey统计班级的平均年龄
// stuKVRDD.aggregateByKey()
}
}
sortBy
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo12SortBy {
def main(args: Array[String]): Unit = {
/**
* sortBy:转换算子,可以对RDD的数据进行排序
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo12SortBy")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[Stu] = sc
.textFile("spark/data/stu/students.txt")
.map(line => {
val splits: Array[String] = line.split(",")
Stu(splits(0), splits(1), splits(2).toInt, splits(3), splits(4))
})
// 按照班级降序排列
stuRDD.sortBy(_.clazz, ascending = false).foreach(println)
// 按照班级降序排列 再按照年龄升序排列
stuRDD.sortBy(stu=>stu.clazz + (1000-stu.age), ascending = false).foreach(println)
}
case class Stu(id: String, name: String, age: Int, gender: String, clazz: String)
}
aggregateByKey
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo13AggregateByKey {
def main(args: Array[String]): Unit = {
// aggregateByKey:转换算子,按照指定的计算逻辑,对Key分组后进行预聚合以及聚合操作
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo13AggregateByKey")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc
.textFile("spark/data/stu/students.txt")
// 统计班级人数
val stuKVRDD: RDD[(String, Int)] = stuRDD
// 将数据变成KV格式,以班级作为Key,1作为Value
.map(line => {
val splits: Array[String] = line.split(",")
(splits(4), 1)
})
// 将数据变成KV格式,以班级作为Key,age作为Value
val stuAgeRDD: RDD[(String, Int)] = stuRDD.map(line => {
val splits: Array[String] = line.split(",")
(splits(4), splits(2).toInt)
})
stuKVRDD.foreach(println)
stuKVRDD.reduceByKey(_ + _).foreach(println)
/**
* aggregateByKey接收两组参数:
* 第一组参数zeroValue:初始化的值,类型基于值可以推断的,可以指定任意的值
* 第二组参数需要接收两个函数:seqOp、combOp
* seqOp:预聚合函数,作用在每个MapTask内部
* combOp:聚合函数,作用在每个ReduceTask内部
*/
stuKVRDD.aggregateByKey(0)((i1, i2) => {
i1 + i2
}, (u1, u2) => {
u1 + u2
}).foreach(println)
// 统计班级平均年龄
// 先统计班级人数
val clazzCntRDD: RDD[(String, Int)] = stuKVRDD.reduceByKey(_ + _)
// 统计班级年龄之和
val classAgeRDD: RDD[(String, Int)] = stuAgeRDD.reduceByKey(_ + _)
// 通过班级进行关联
clazzCntRDD.join(classAgeRDD).map {
case (clazz: String, (cnt: Int, sumAge: Int)) =>
s"$clazz,${sumAge / cnt.toDouble}"
}.foreach(println)
// 通过aggregateByKey实现
stuAgeRDD.aggregateByKey(0)((sumAge, age) => {
sumAge + age
}, (sumAge1, sumAge2) => {
sumAge1 + sumAge2
}).foreach(println)
stuKVRDD.aggregateByKey(0)((i1, i2) => {
i1 + 1
}, (u1, u2) => {
u1 + u2
}).foreach(println)
stuAgeRDD.aggregateByKey((0, 0))((t2, age) => {
// 对age进行预聚合
val sumAge: Int = t2._1 + age
// 对班级人数+1
val clazzCnt: Int = t2._2 + 1
(sumAge, clazzCnt)
}, (sumAgeAndClazzCnt01, sumAgeAndClazzCnt02) => {
val totalSumAge: Int = sumAgeAndClazzCnt01._1 + sumAgeAndClazzCnt02._1
val totalClazzCnt: Int = sumAgeAndClazzCnt01._2 + sumAgeAndClazzCnt02._2
(totalSumAge, totalClazzCnt)
}).map {
case (clazz: String, (sumAge: Int, cnt: Int)) =>
s"$clazz,${sumAge / cnt.toDouble}"
}.foreach(println)
// 使用reduceByKey简化aggregateByKey
// 需要先将学生数据转换成KV格式
// 用clazz作为key,用(age,1)构建二元组作为Value
stuRDD.map(line => {
val splits: Array[String] = line.split(",")
(splits(4), (splits(2).toInt, 1))
}).reduceByKey((t1, t2) => {
val sumAge: Int = t1._1 + t2._1
val cnt: Int = t1._2 + t2._2
(sumAge, cnt)
}).map {
case (clazz: String, (sumAge: Int, cnt: Int)) =>
s"$clazz,${sumAge / cnt.toDouble}"
}.foreach(println)
}
}
4.3.3 Action行为算子
join
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo14Join {
def main(args: Array[String]): Unit = {
/**
* join:转换算子,可以实现两个RDD之间的关联操作
* 两个RDD必须是KV格式的,而且Key的类型必须一致
*/
val conf: SparkConf = new SparkConf()
conf.setMaster("local")
conf.setAppName("Demo14Join")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc
.textFile("spark/data/stu/students.txt")
val scoreRDD: RDD[String] = sc
.textFile("spark/data/stu/score.txt")
// 计算每个学生的总分
val sumScoreRDD: RDD[(String, Int)] = scoreRDD
.map(line => {
val splits: Array[String] = line.split(",")
(splits(0), splits(2).toInt)
}).reduceByKey(_ + _)
// 将学生数据变成KV形式
// 以id作为Key,构建(name,age)二元组作为Value
stuRDD.map(line => {
val splits: Array[String] = line.split(",")
(splits(0), (splits(1), splits(2).toInt))
}).join(sumScoreRDD).map {
case (id: String, ((name: String, age: Int), sumScore: Int)) =>
s"$id,$name,$age,$sumScore"
}.foreach(println)
stuRDD.map(line => {
val splits: Array[String] = line.split(",")
(splits(0), (splits(1), splits(2).toInt))
}).leftOuterJoin(sumScoreRDD).map {
case (id: String, ((name: String, age: Int), mayBeSumScore: Option[Int])) =>
mayBeSumScore match {
case Some(sumScore) =>
s"$id,$name,$age,$sumScore"
case None =>
s"$id,$name,$age,0"
}
}.foreach(println)
}
}
RDD分区数讨论
- 决定分区数优先级

 浙公网安备 33010602011771号
浙公网安备 33010602011771号