
公司新来了个同事,代码写得是真优雅呀!代码如诗
来源:https://www.cnblogs.com/javastack/p/17786356.html
来源:https://www.cnblogs.com/liuboren/p/17017421.html
0.前言
本篇文章是<<代码整洁之道>>的学习总结, 通过这篇文章你将了解到整洁的代码对项目、公司和你的重要性,以及如何书写整洁的代码.
通过命名、类、函数、测试这四个章节,使我们的代码变得整洁.
1.为什么要保持代码整洁?
不整洁的代码随着时间的增加而增加时,生产力会随之降低.
导致的结果就是:
- 代码不易扩展或扩展容易引发其他问题
- 程序崩溃
- 加班
- 增加公司成本(加人)
- 甚至可能造成公司倒闭
一图胜千言
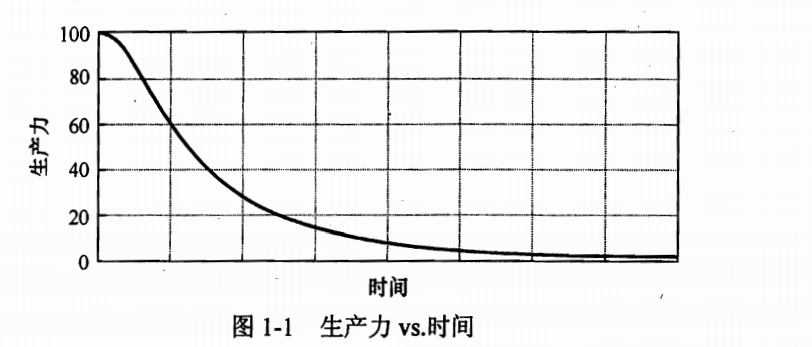
1.1 所以从一开始就要保持整洁
所以在一开始就要写整洁的代码,如果有不整洁的代码就要及时的整改. 绝对不要有以后再改,以后再说的想法, 因为!
later equal never
想想是不是这个道理,你有多少以后再说、以后再改的东西都抛诸脑后了.
如果是一定要做的事情,那就趁早做!
推荐一个开源免费的 Spring Boot 实战项目:
1.2 如何写出整洁的代码?
那么现在的问题就是,怎样的代码才算是整洁的代码呢:
- 可读性要高: 代码要像散文一样优雅易读,见码知意
- 拒绝重复代码
- 满足设计模式原则
- 单一职责
- 开闭原则
- 里氏替换原则
- 依赖倒转原则
- 接口隔离原则
- 迪米特法则
- 合成复用法则
2.命名
好的命名可提高代码的可读性,让人见码知意, 降低理解成本,提高效率, 减少加班.
2.1 不好的命名方式
- 没有任何意义的命名方式
public interface Animal {
void abc();
}
现在我们有一个动物的接口, 里面有一个方法abc(),看了让人一头雾水, 调用这个方法的人也完全不知道这个方法是干什么的,因为他的命名毫无意义
有意义的命名方式:
public interface Animal {
void cry();
}
我们将方法名命名为cry(喊叫,呼喊),调用的人就知道这个方法的作用是什么了.
所以命名一定要有意义且让人见码知意.
- 命名前后不一致
这种情况体现在明明是同一行为,但是却有不同的命名,前后不一致,让人造成混淆.
public interface StudentRepository extends JpaRepository<AlertAll, String> {
Student findOneById(
@Param("id") String id
);
List<Student> queryAllStudent(
);
}
上面两个方法都是查询xxx, 但是命名一会叫query一会叫find,这种情况应该加以规范,保持一致, 修改后:
public interface StudentRepository extends JpaRepository<AlertAll, String> {
Student findOneById(
@Param("id") String id
);
List<Student> findAll(
);
}
- 命名冗余
体现在命名有很多没必要的成分在里面, 并且这些"废话"并不能帮助区分它们的区别, 例如在变量命名中添加了Variable这个词, 在表名中添加了Table这个词.
所以命名中不要出现冗余的单词, 并且提前约定好命名的规范.
// 获取单个对象的方法用get做前缀
getXxx();
//获取多个对象用list做前缀
listXxxx();
3.类
整洁的类应满足一下内容:
- 单一职责
- 开闭原则
- 高内聚性
3.1单一职责
类应该短小,类或模块应有且只有一条加以修改的理由, 如果一个类过于庞大的话,那么说明它承担的职责过多了.
优点:
- 降低类的复杂度
- 提高类的可读性
- 提高系统的可维护性
- 降低变更引起的风险
如何判定类是否足够短小?
通过计算类的职责来判断是否够短小,类的名称描述其全责, 如果无法为某个类命以准确的名称, 这个类大概就太长了, 类名越含糊,可能拥有越多的职责.
职责过多的例子,可以看到以下类有两个职责:
public abstract class Sql {
// 操作SQL的职责
public abstract void insert();
// 统计SQL操作的职责
public abstract void countInsert();
}
将统计的职责抽取到另一个类
public abstract class CountSql {
public abstract void countInsert();
}
3.2 开闭原则
开闭原则: 面向修改关闭, 面向扩展开放.
面向修改关闭意味着增加新的逻辑不会修改原有的代码,降低了出错的可能性.
面向扩展开放则是提高了代码的可扩展性,可很容易的增加新的代码逻辑.
不满足开闭原则的例子:
public abstract class Sql {
public abstract void insert();
public abstract void update();
public abstract void delete();
}
如果我们现在要新增查询的操作,就需要修改Sql这个类,没有做到面向修改关闭
重构后:
public abstract class Sql {
public abstract void generate();
}
public class CreateSql extends Sql {
@java.lang.Override
public void generate() {
// 省略实现
}
}
public class UpdateSql extends Sql {
@Override
public void generate() {
// 省略实现
}
}
当我们要增加删除方法时可以很容易的扩展.
使用大量的短小的类看似比使用少量庞大的类增加了工作量(增加了更多的类),但是真的是这样吗? 这里有一个很好的类比:
你是想把工具归置到有许多抽屉、每个抽屉中装有定义和标记良好的组件的工具箱呢, 还是想要少数几个能随便吧所有东西扔进去的抽屉?
最终的结论:
系统应该由许多短小的类而不是少量巨大的类组成,每个小类封装一个权责,只有一个修改的原因,并与少数其他类一起协同达成期望的系统行为.
3.3 内聚
方法操作的变量越多,就约粘聚到类上. 如果一个类中的每个变量都被每个方法所使用, 则该类具有最大的内聚性.
我们应该将类的内聚性保持在较高的位置. 内聚性高意味着方法和变量互相依赖, 互相结合成一个逻辑整体.
为什么要保持高内聚?
保持内聚性就会得到许多短小的类,就越满足单一职责.
内聚性低怎么办?
如果类的内聚性就不够高,就将原有的类拆分为新的类和方法.
4.函数
要想让函数变得整洁,应保证:
- 只做一件事
- 好的命名
- 整洁的参数
- 注意返回内容
4.1 只做一件事
what?
函数的第一规则是短小 第二规则是更短小 短小到只做一件事情. (没错和类的原则很像)
why?
函数越短小,越能满足单一职责.
how?
以下是重构前的代码, 这个方法有三个职责,并且该方法很长达到了80+50+5 = 135行
public class PicService {
public String upload(){
// 校验图片的方法 伪代码80行
// 压缩图片的方法 伪代码50行
// 返回成功或失败标识 0,1 伪代码5行
return "0";
}
}
原有的upload方法做了很多的事情, 重构后只做了一件事情: 把大一些的概念(换言之,函数的名称)拆分为另一抽象层上的一系列步骤:
public String upload(){
// 校验图片的方法
check();
// 压缩图片的方法
compress();
// 返回成功或失败标识 0,1
return "0";
}
而里面的每个方法,也都有着自己各自的职责(校验图片 、压缩图片 、返回结果).
4.2 函数命名
- 函数名应见名知意
函数拥有描述性的名称,不要害怕长名称.
不好的命名方式:
public String addCharacter(String originString, char ch);
这个函数,一咋看,还不错,从函数字面意思看是给某个字符串添加一个字符。但是到底是在原有字符串首部添加,还是在原有字符串末尾追加呢?亦或是在某个固定位置插入呢?从函数名字完全看不出来这个函数的真正意图,只能继续往下读这个函数的具体实现才知道。
而下面这几个名字就比上面要好得多:
// 追加到末尾
public String appendCharacter(String originString, char ch);
// 插入指定位置
public String insertCharacter(String originString, char ch, int insertPosition);
- 函数应该无副作用
函数应该无副作用, 意思就是函数应该只做一件事,但是做这件事的时候做了另一件有副作用的事情.
例如: 校验密码时会初始化session,导致会话丢失。 如果无法移除这种副作用,应该在方法名中展示出来,避免用户误用 checkPasswordasswordAndInitializeSession, 从命名上就要体现副作用.
4.3 参数
- 参数越少越好
参数越少,越容易理解,参数超过三个可以将参数进行封装,要按参数的语义进行封装,不一定封装成一个大而全的参数,可以封装为多个,原则是按语义补充;
示例:
public List<Student> findStudent(int age, String name, String country, int gender);
//封装参数
public List<Student> findStudent(Student student);
- 不要使用标识参数
标识参数是参数为Boolean 类型, 用户传递true or false . 不要使用标识参数因为这意味着你的函数违背了单一职责(true false 两套逻辑).
正确的做法是拆分为两个方法:
//标识参数方法
render(Boolean isSuite);
//重构为两个方法
reanderForSuite();
renderForSingleTest();
- 不要使用输出参数
什么是输出参数?
将变量作为参数传入方法,并且将变量输出, 这就是输出参数
public void findStudent(){
Student student = new Student();
doSomething(student);
return student;
}
int doSomething(Student student){
// 省略一些student逻辑
return student;
}
为什么不应该有输出参数?
因为增加了理解成本在里面,我们需要查看doSomething到底对student 做了什么. student是输入还是输出参数? 都不明确.
重构:
// 将doSomething()方法内聚到student对象本身
student.doSomething();
4.4 返回值
- 分离指令与讯问
示例代码:
Pulic Boolean addElement(Element element)
指令为增加某个元素,询问是否成功,
这样做的坏处是职责不单一,所以应该拆分为两个方法
public void addElement(Element element);
public Boolean isAdd(Element element);
- 使用异常替代返回错误码
直接抛出异常,而不是返回错误码进行判断, 可以使代码更简洁. 因为使用错误码有可能会进行多层嵌套片段
代码示例:
// 使用错误码导致多层嵌套...
public class DeviceController{
public void sendShutDown(){
DeviceHandle handle=getHandle(DEV1);
//Check the state of the device
if (handle != DeviceHandle.INVALID){
// Save the device status to the record field
retrieveDeviceRecord(handle);
// If nat suspended,shut down
if (record.getStatus()!=DEVICE_SUSPENDED){
pauseDevice(handle);
clearDeviceWorkQueue(handle);
closeDevice(handle);
}else{
logger.log("Device suspended. Unable to shut down");
}
}else{
logger.log("Invalid handle for: " +DEV1.tostring());
}
}
重构后:
// 将代码拆分为一小段一小段, 降低复杂度,更加清晰
public class DeviceController{
public void sendShutDowm(){
try{
tryToShutDown();
} catch (DeviceShutDownError e){
logger.log(e);
}
private void tryToShutDown() throws DeviceShutDownError{
DeviceHandle handle =getHandle(DEV1);
retrieveDeviceRecord(handle);
pauseDevice(handle);
clearDeviceWorkQueue(handle);
closeDevice(handle);
}
private DeviceHandle getHandle(DeviceID id){
// 省略业务逻辑
throw new DeviceShutDownError("Invalid handle for:"+id.tostring());
}
}
4.5 怎样写出这样的函数?
没人能一开始就写出完美的代码, 先写出满足功能的代码,之后紧接着进行重构
为什么是紧接着?
因为later equal never!
4.6 代码质量扫描工具
使用SonarLint可以帮助我们发现代码的问题,并且还提供了相应的解决方案.
对于每一个问题,SonarLint都给出了示例,还有相应的解决方案,教我们怎么修改,极大的方便了我们的开发
比如,对于日期类型尽量用LocalDate、LocalTime、LocalDateTime,还有重复代码、潜在的空指针异常、循环嵌套等等问题
有了代码规范与质量检测工具以后,很多东西就可以量化了,比如bug率、代码重复率等.
5.测试
测试很重要,可以帮助我们验证写的代码是否没问题,同样的测试代码也应该保持整洁.
5.1 TDD
TDD是测试驱动开发(Test-Driven Development),是敏捷开发中的一项核心实践和技术,也是一种设计方法论
优点:在任意一个开发节点都可以拿出一个可以使用,含少量bug并具一定功能和能够发布的产品。
缺点:增加代码量。测试代码是系统代码的两倍或更多,但是同时节省了调试程序及挑错时间。
how?
1.在开发代码前先写测试
2.只可编写刚好无法通过的单元测试,不能编译也算不通过
3.开发代码不可超过测试
关于2的解释: 单测与生产代码同步进行,写到一个不可编译的单测就开始写生产代码,如此反复循环,单测就能包含到所有生产代码。
5.2 FIRST原则
FIRST 原则就是一个指导编写单元测试的原则
fast 快速 单测执行应该快速的完成
independent 独立 单测之间相互独立
repeatable 可重复 单测不依赖于环境,随处可运行
self validating 程序可通过输出的Boolean自我验证,而不需要通过人工的方式验证(看日志输出、对比两个文件不同等)
timely 及时 单测在生产代码之前编写
单元测试是代码测试中的基础测试,FIRST是写好单元测试的重要原则,它要求我们的单元测试快速,独立,可重复,自我校验,及时/完整。
5.3 测试代码模式
开发测试代码可以使用given-when-then模式
given 制造模拟数据
when 执行测试代码
then 验证测试结果
代码示例
/**
* If an item is loaded from the repository, the name of that item should
* be transformed into uppercase.
*/
@Test
public void shouldReturnItemNameInUpperCase() {
// Given
Item mockedItem = new Item("it1", "Item 1", "This is item 1", 2000, true);
when(itemRepository.findById("it1")).thenReturn(mockedItem);
// When
String result = itemService.getItemNameUpperCase("it1");
// Then
verify(itemRepository, times(1)).findById("it1");
assertThat(result, is("ITEM 1"));
}
使用give-when-then 模式可提高测试代码的可读性.
5.4 自动生成单测
介绍两款IDEA自动生成单测的插件
- Squaretest插件(收费)
- TestMe插件(免费)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号