Hadoop综合大作业
1导入数据表并且去掉头部的第一条数据,然后查看签名5条数据

2 预处理,创建一个脚本文件pre_deal.sh,对数据表中的地址进行省份转换:

3转换后的txt表,可以看见有中文的地区名
4 开启Hadoop,hive

5 在hdfs上创建一个bigdatacase/dataset文件夹

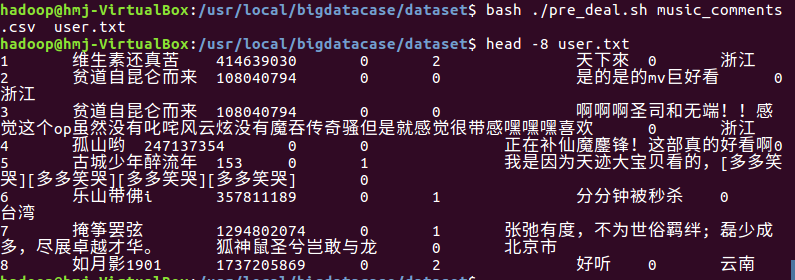
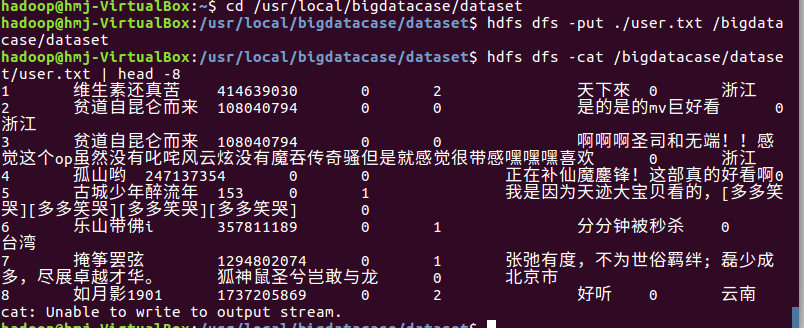
6将之前转换后的txt文件上传到hdfs上面,然后查看内容
7开启MySQL和hive
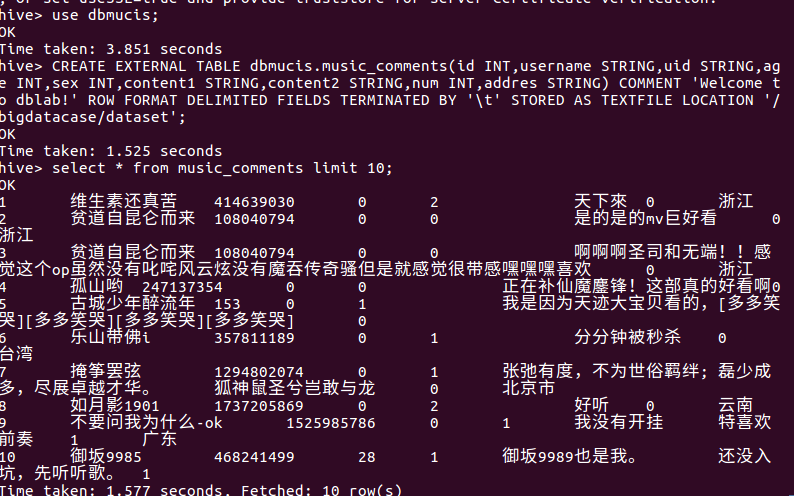
8创建数据库dblab,并通过命令“use dblab”打开和使用数据库:
9查找用户地区为北京市,
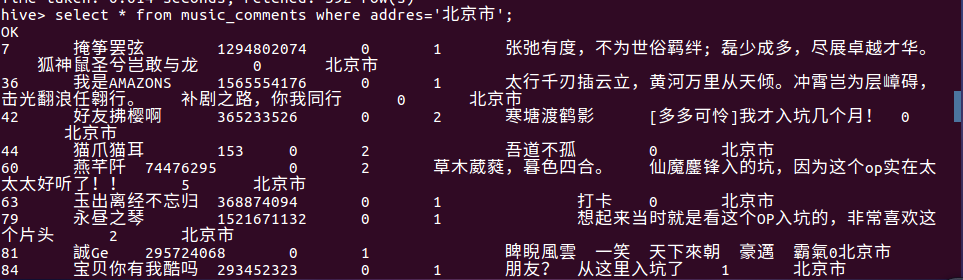
10 查询用户年龄大于18并且小于30的,
分析:总共有700多条,占了3分之一的人数,看出该音乐的听众年龄范围还是很广的
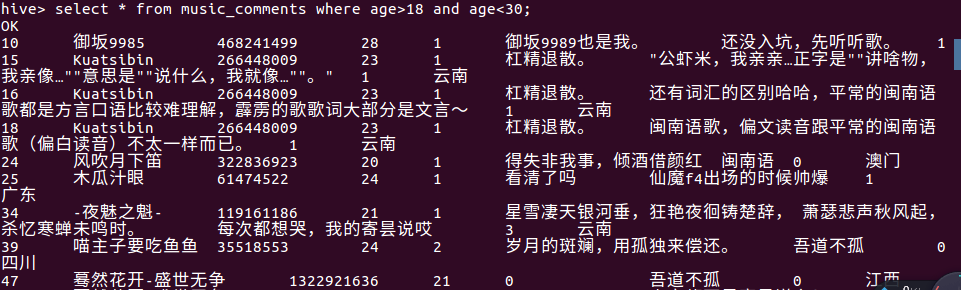
11查询该音乐有多少评论数,
分析:总数是2108条评论,虽然不是很多,但也是可以用来分析数据的了
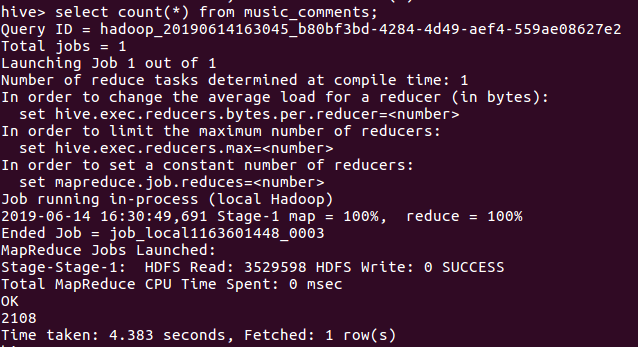
12查找没有设置性别的人数,
分析:598/2108 大约是4分之一的人都没有设置用户性别,绝大多数用户对于隐私还是比较看重的了
13查询点赞人数最多的前二十条数据,
分析:可以看出评论点赞最多的还是歌词本身的内容
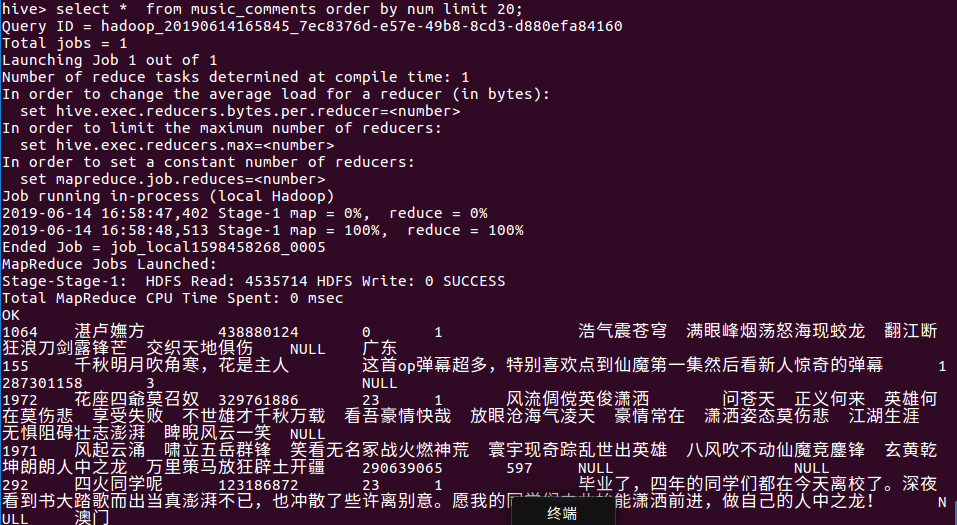
14查找歌曲名字出现在评论的次数是多少,
分析:人们还是挺在意歌曲名字的
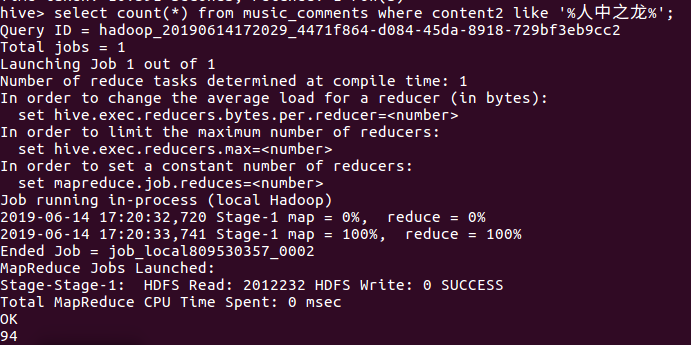
15查看剧中主角之一被提到的次数,
分析:被提到的次数只有个位数,可见该人们更倾向其他内容评论
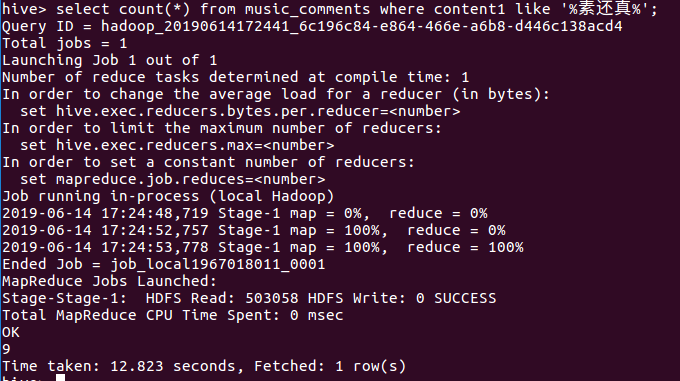
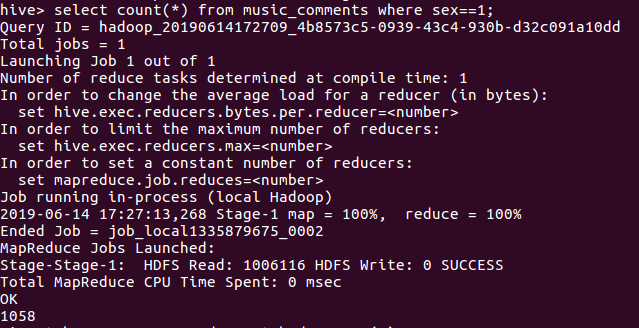
16查看评论中的男生人数有多少,
分析:发现占比1058/2018 接近一半都是男生在评论,也就是男女比例差不多
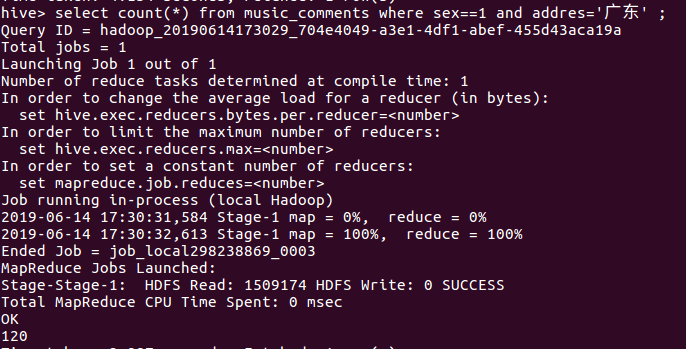
17查看广东的男生评论人数有多少,
分析:广东地区听这首音乐的人不是太多
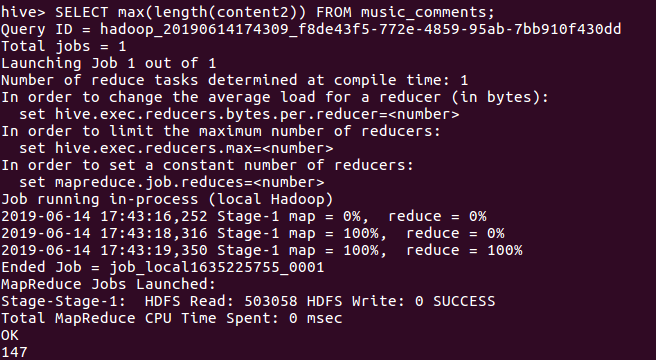
18 查看评论最常的字节长度(147个字节) ,
分析:评论的短小显示出该音乐的的热点并不是很高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号