分布式并行计算MapReduce
1.阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS功能:是Hadoop项目的核心子项目。是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上 pc server。
具有以下的功能:
(1)高容错性 :自动保存多个副本来增加容错性 ,如果某一个副本丢失,HDFS机制会复制其他机器上的副本,透明实现。
(2)支持超大文件 :流式数据访问 批量处理不是用户交互式处理。
(3)HDFS使应用程序能够以流的形式访问数据 注重的是吞吐量而不是数据访问的速度。
(4)简化的一致性模型大部分为一次写入多次读取。
HDFS的工作机制和原理:
(1)HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
(2) NameNode负责管理整个文件系统的元数据
(3)DataNode 负责管理用户的文件数据块
(4)文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
(5)每一个文件块可以有多个副本,并存放在不同的datanode上
(6)Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
(7)HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
二、MapReduce的功能、工作原理和工作过程。
MapReduce的功能:
MapReduce程序运行过程:
1. 作业运行过程:首先向JobTracker请求一个新的作业ID;然后检查输出说明(如输出目录已存在)、输出划分(如输入路径不存在);JobTracker配置好所有需要的资源,然后把作业放入到一个内部的队列中,并对其进行初始化,初始化包括创建一个代表该正在运行的作业对象(封装任务和记录信息),以便跟踪任务的状态和进程;作业调度器获取分片信息,每个分片创建一个map任务。TaskTracker会执行一个简单的循环定期发送heartbeat给JobTracker,心跳间隔可自由设置,通过心跳JobTracker可以监控TaskTracker是否存活,同时也能获得TaskTracker处理的状态和问题,同时也能计算出整个Job的状态和进度。当JobTracker获得了最后一个完成指定任务的TaskTracker操作成功的通知时候,JobTracker会把整个Job状态置为成功,然后当客户端查询Job运行状态时候(注意:这个是异步操作),客户端会查到Job完成的通知的。
2. 逻辑角度分析作业运行顺序:输入分片(input split)、map阶段、combiner阶段、shuffle阶段、reduce阶段。
- map阶段:即执行map函数。
- combiner阶段:这是一个可选择的函数,实质上是一种reduce操作。combiner是map的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作。
- shuffle阶段:指从map输出开始,包括系统执行排序即传送map输出到reduce作为输入的过程。另外针对map输出的key进行排序又叫sort阶段。map端shuffle,简单来说就是利用combiner对数据进行预排序,利用内存缓冲区来完成。reduce端的shuffle包括复制数据和归并数据,最终产生一个reduce输入文件。shuffle过程有许多可调优的参数来提高MapReduce的性能,其总原则就是给shuffle过程尽量多的内存空间。
- reduce阶段:即执行reduce函数并存到hdfs文件系统中。
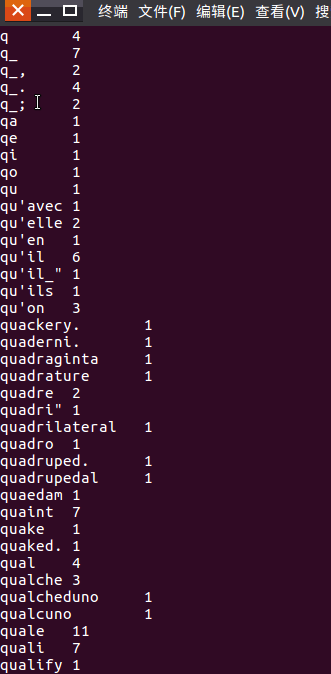
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
2)编写map函数和reduce函数,在本地运行测试通过
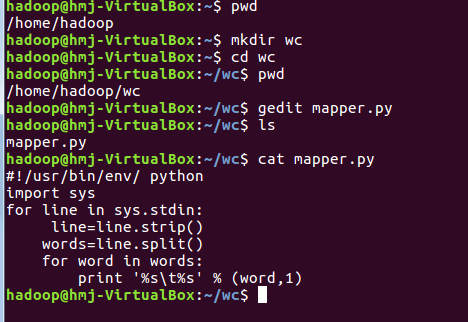
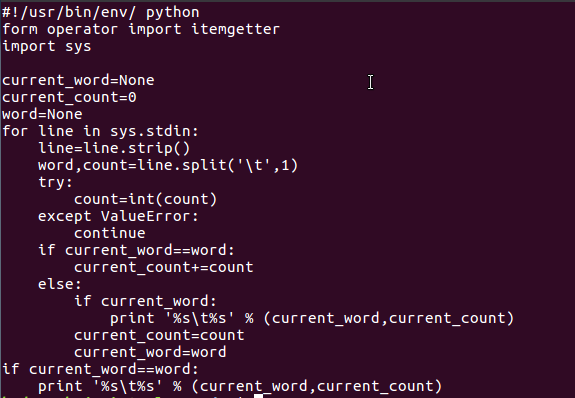
本地运行二个程序:
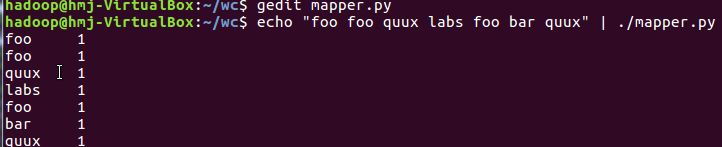

下载文本文件或爬取网页内容存成的文本文件:
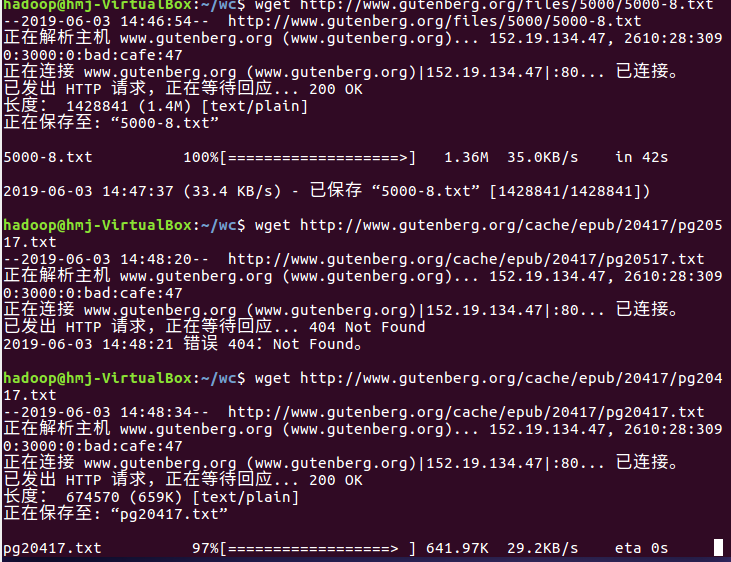
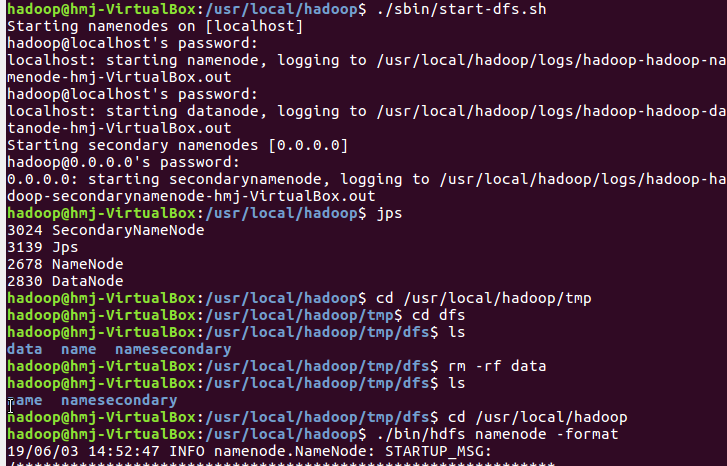
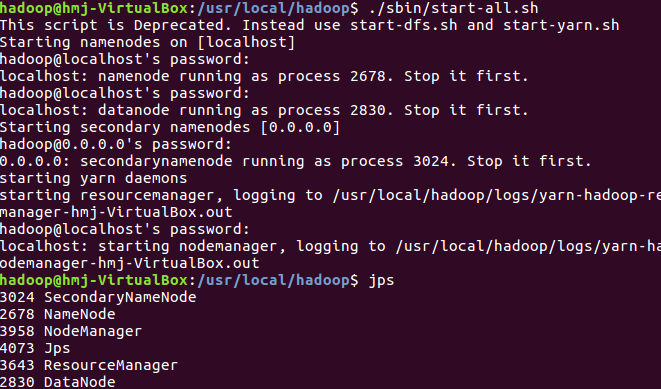
3)启动Hadoop:HDFS, JobTracker, TaskTracker
把文本文件上传到hdfs文件系统上 user/hadoop/input

建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
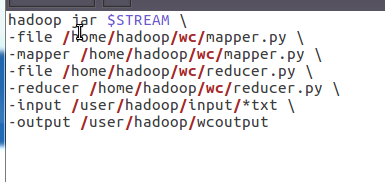
运行结果