爬虫综合大作业
一.把爬取的内容保存取MySQL数据库:
from urllib.request import urlopen from urllib.request import urlretrieve from bs4 import BeautifulSoup import pymysql import csv import xlrd import pandas as pd import jieba ExcelFile=xlrd.open_workbook(r'C:\Users\Administrator\Desktop\postcode.xls') csv_file=csv.reader(open('music_comments.csv','r',encoding='UTF-8')) content=list() #用来存储整个文件的数据,存成一个列表,列表的每一个元素又是一个列表,表示的是文件的某一行 words=[] lists=[] for line in csv_file: if(len(line)>=7): lists.append(line[5]) # print(lists) conn = pymysql.connect(host='127.0.0.1',user='root',passwd='',db='test',charset='utf8') cur = conn.cursor() for i in lists: # i='\''+i+'\'' cur.execute("insert into content(content) VALUES ('"+i+"')") conn.commit() cur.close() conn.close() print("成功!")
二.爬虫综合大作业:
爬虫目标:关于《人中之龙》这首音乐在网页云音乐的评论人的情况。
import json import time import requests headers = { 'Host': 'music.163.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } def get_comments(page): """ 获取评论信息 """ url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_454232001?limit=20&offset=' + str(page) response = requests.get(url=url, headers=headers) # 将字符串转为json格式 result = json.loads(response.text) items = result['comments'] for item in items: # 用户名 user_name = item['user']['nickname'].replace(',', ',') # 用户ID user_id = str(item['user']['userId']) # 获取用户信息 user_message = get_user(user_id) # 用户年龄 user_age = str(user_message['age']) # 用户性别 user_gender = str(user_message['gender']) # 用户所在地区 user_city = str(user_message['city']) # 个人介绍 user_introduce = user_message['sign'].strip().replace('\n', '').replace(',', ',') # 评论内容 comment = item['content'].strip().replace('\n', '').replace(',', ',') # 评论ID comment_id = str(item['commentId']) # 评论点赞数 praise = str(item['likedCount']) # 评论时间 date = time.localtime(int(str(item['time'])[:10])) date = time.strftime("%Y-%m-%d %H:%M:%S", date) # print(user_name, user_id, user_age, user_gender, user_city, user_introduce, comment, comment_id, praise, date) with open('music_comments.csv', 'a', encoding='utf-8-sig') as f: f.write(user_name + ',' + user_id + ',' + user_age + ',' + user_gender + ',' + user_city + ',' + user_introduce + ',' + comment + ',' + comment_id + ',' + praise + ',' + date + '\n') f.close() def get_user(user_id): """ 获取用户注册时间 """ data = {} url = 'https://music.163.com/api/v1/user/detail/' + str(user_id) response = requests.get(url=url, headers=headers) # 将字符串转为json格式 js = json.loads(response.text) if js['code'] == 200: # 性别 data['gender'] = js['profile']['gender'] # 年龄 if int(js['profile']['birthday']) < 0: data['age'] = 0 else: data['age'] = (2018 - 1970) - (int(js['profile']['birthday']) // (1000 * 365 * 24 * 3600)) if int(data['age']) < 0: data['age'] = 0 # 城市 data['city'] = js['profile']['city'] # 个人介绍 data['sign'] = js['profile']['signature'] else: data['gender'] = '无' data['age'] = '无' data['city'] = '无' data['sign'] = '无' return data def main(): # 前500页 # for i in range(210000, 230000, 20): # 后500页 for i in range(0, 25000, 20): print('\n---------------第 ' + str(i // 20 + 1) + ' 页---------------') get_comments(i) if __name__ == '__main__': main()
以上是爬取网易云音乐的关于《人中之龙》这首音乐评论人员的评论时间,评论人的地区,评论内容等,保存到文件里,如下图:
总共2000来条评论数据。
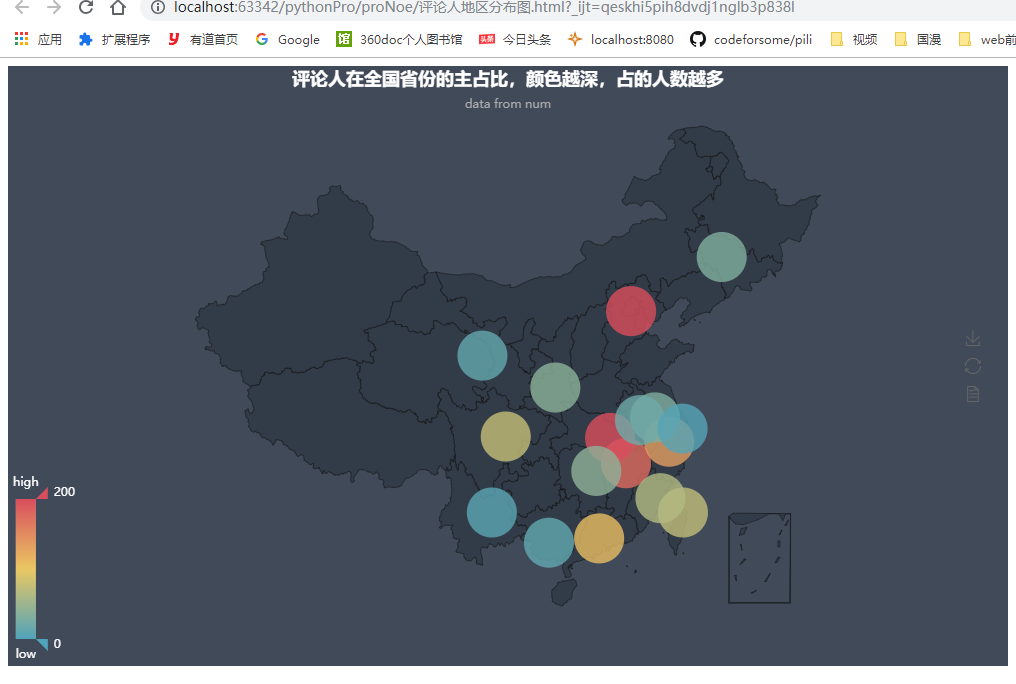
以下是对评论用户所在的省份进行统计,用pyecharts描绘出评论人在全国省份的的大致情况:
import csv import xlrd from pyecharts import Map, Geo def show_map(data): geo = Geo("评论人在全国省份的主占比,颜色越深,占的人数越多", "data from num", title_color="#fff", title_pos="center", width=1000, height=600, background_color='#404a59') attr, value = geo.cast(data) geo.add("", attr, value, visual_range=[0, 200], maptype='china',visual_text_color="#fff", symbol_size=50, is_visualmap=True) geo.show_config() geo.render(path="./评论人地区分布图.html") def read_excel(city_code,ExcelFile): rows=len(ExcelFile.sheet_names()) # #获取整行或者整列的值 for i in range(rows): sheet=ExcelFile.sheet_by_name(ExcelFile.sheet_names()[i]) if( city_code[0:2] == str(sheet.row_values(2)[1])[0:2] ): return city_code[0:2]; if __name__ == '__main__': ExcelFile=xlrd.open_workbook(r'C:\Users\Administrator\Desktop\postcode.xls') data={'84': '新疆', '85': '西藏', '81': '青海', '73': '甘肃', '61': '四川', '65': '云南', '75': '宁夏', '02': '内蒙古', '16': '黑龙江', '13': '吉林', '11': '台湾', '05': '河北', '10': '北京', '30': '天津', '71': '陕西', '03': '山西', '27': '山东', '47': '河南', '40': '重庆', '44': '湖北', '23': '安徽', '21': '江苏', '20': '上海', '55': '贵州', '53': '广西', '41': '湖南', '33': '江西', '32': '浙江', '35': '福建', '51': '广东', '57': '海南', '99': '香港'} csv_file=csv.reader(open('music_comments.csv','r',encoding='UTF-8')) content=list() #用来存储整个文件的数据,存成一个列表,列表的每一个元素又是一个列表,表示的是文件的某一行 cityList={} cityArry=[] for line in csv_file: if(len(line)>=5): temp=read_excel(line[4],ExcelFile) if(temp!=None): if(temp in cityList): cityList[temp]=cityList[temp]+1 else: cityList[temp]=0 for city in cityList: cityArry.append( (data[city],cityList[city]) ) show_map(cityArry) print (cityArry)
以下是效果图,可以看出主要的评论人在北京地区和广东福建地区比较多。
import csv import xlrd import pandas as pd import jieba ExcelFile=xlrd.open_workbook(r'C:\Users\Administrator\Desktop\postcode.xls') csv_file=csv.reader(open('music_comments.csv','r',encoding='UTF-8')) content=list() #用来存储整个文件的数据,存成一个列表,列表的每一个元素又是一个列表,表示的是文件的某一行 words=[] wcdict={} for line in csv_file: if(len(line)>=7): for word in jieba.lcut(line[5]): wcdict[word]=wcdict.get(word,0)+1 for word in jieba.lcut(line[6]): wcdict[word]=wcdict.get(word,0)+1 # 过滤的单词 removeWord=[ ',','。','是',',','(',')','ノ','*','•','´','啊','都','‘','你','有','','Д','σ','ପ','ଓ','⃛', '!','、','的','来','虽然','了','我','在','▽','ω','也','`','…','听','不','就','`', '/','[',']','?','?' ] words=list(wcdict.items()) i=0 while i < len(words): if words[i][0] in removeWord: #查找单词列表是否在要过滤的单词表中,有的,从单词列表中去掉该单词 words.remove(words[i]) if i!=0: #因为去掉单词后,列表内容会前移一位,所以索引要减一 i=i-1 else: i=i+1 # print (words) pd.DataFrame(data=words).to_csv('big.csv',encoding='utf_8_sig')
以下是根据评论的语句进行词云分析。

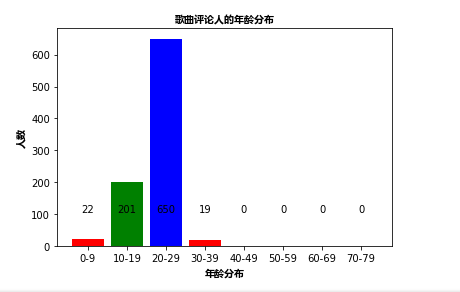
import csv import xlrd import math import pandas as pd import jieba import matplotlib.pyplot as plt import matplotlib import numpy as np ExcelFile=xlrd.open_workbook(r'C:\Users\Administrator\Desktop\postcode.xls') csv_file=csv.reader(open('music_comments.csv','r',encoding='UTF-8')) content=list() #用来存储整个文件的数据,存成一个列表,列表的每一个元素又是一个列表,表示的是文件的某一行 ages=[] wcdict={} for line in csv_file: if(len(line)>=3): if(line[2]!='0'): if(int(line[2]) <100): ages.append(int(line[2]) ) wcdict[line[2]]=wcdict.get(line[2],0)+1 wcls=list(wcdict.items()) data=[0,0,0,0,0,0,0]; for item in wcls: index= int(int(item[0])/10 ) data[index]+= int(item[1]) myfont = matplotlib.font_manager.FontProperties(fname=r'C:\Users\Administrator\Desktop\msyhbd.ttf') # 构建数据 x_data = ['10-19', '20-29', '30-39', '40-49', '50-59', '60-69','70-79'] plt.bar(range(len(x_data)),data ,color='rgb',tick_label=x_data) # plt.bar(x=x_data, height=500, label='age', color='steelblue', alpha=0.8) # 在柱状图上显示具体数值, ha参数控制水平对齐方式, va控制垂直对齐方式 for x, y in enumerate(data): plt.text(x, 100 , '%s' % y, ha='center', va='bottom') # # 设置标题 plt.title("歌曲评论人的年龄分布",fontproperties = myfont) # 为两条坐标轴设置名称 plt.xlabel("年龄分布",fontproperties = myfont) plt.ylabel("人数",fontproperties = myfont) # 显示图例 plt.legend() plt.show()
以下是对评论人年龄分布的分析,发现主要人都是青年人在听