
中文词频统计
#源代码
import jieba # 加载分析的文本三国演义 file=open('sanguo.txt','r',encoding='utf-8') test=file.read() # 加载要过滤的词语 fileStops=open('stops_chinese1.txt','r',encoding='utf-8') testStops=fileStops.read() wordStops=jieba.lcut(testStops) print("要过滤的词语:") print(wordStops) # 加载词库 jieba.load_userdict('san.txt') words=jieba.lcut(test) wcdict={} for word in words: if len(word)==1: continue else: wcdict[word]=wcdict.get(word,0)+1 wcls=list(wcdict.items()) wcls.sort(key=lambda x:x[1],reverse=True) i=0 while i< len(wcls): if wcls[i][0] in wordStops: #查找单词列表是否在要过滤的单词表中,有的,从单词列表中去掉该单词 wcls.remove(wcls[i]) if i!=0: #因为去掉单词后,列表内容会前移一位,所以索引要减一 i=i-1 else: i=i+1 print("三国演义关键词top25:") for i in range(25): print(wcls[i])
以下是三国演义的词库,将其引入:

要分析的文本,《三国演义》:
要过滤的词语:

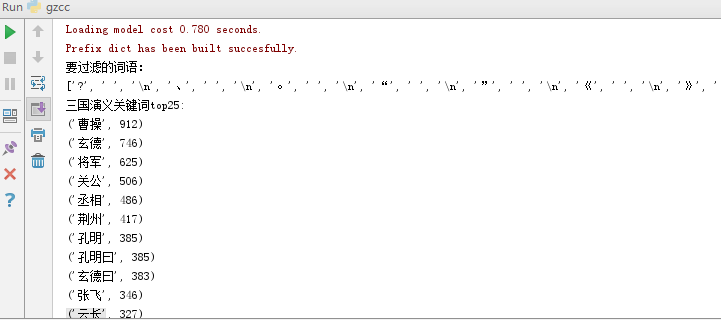
运行结果图:
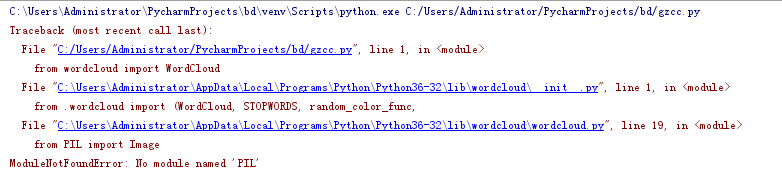
因为运行wordcloud老是出现下面错误,就用网上的在线词云。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号