Flume入门样例
Flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
http://flume.apache.org/index.html
Flume具有高可扩展性 可随意组合:


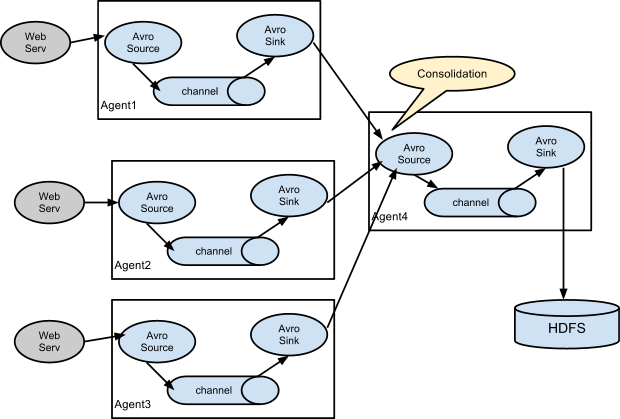
(上述图片来自官网文档)
Flume的一些核心概念:
Agent 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
Client 生产数据,运行在一个独立的线程。
Source 从Client收集数据,传递给Channel。
Sink 从Channel收集数据,运行在一个独立线程。
Channel 连接 sources 和 sinks ,这个有点像一个队列。
Events 可以是日志记录、 avro 对象等。
Flume数据源以及输出方式:
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力
Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等
下载-解压-修改/etc/profile
Example:文件追加内容作为消息输入
EXEC执行一个给定的命令获得输出的源,如果要使用tail命令,必选使得file足够大才能看到输出内容
1. 创建配置文件vi example.conf
a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.channels = c1 a1.sources.r1.command = tail -F ~/test/log_exec_tail # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2. 启动flume agent
flume-ng agent -c conf -f ~/test/example.conf --name a1 -Dflume.root.logger=INFO,console
3.对文件进行追加
for i in {1..100}; do echo "exec tail$i" >> ~/test/log_exec_tail; done
4.在启动flume agent的控制台就可以看到追加的信息陆续出现了
更多输入输出源参见:http://www.aboutyun.com/thread-8917-1-1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号