5000字详说Elasticsearch入门(一)
本文主要介绍快速入门Elasticsearch,从安装、基本概念、分词器、文档基本操作这4个方面快速入门。本篇是ES入门系列的第一篇,后续还有springboot项目集成ES、ES高级查询用法、数据库同步到ES的方案等。
Elasticsearch是一款近实时的搜索引擎,底层是基于Lucene做搜索,再此基础上加入了分布式的特性,以便支持海量数据的存储和搜索。
1、安装
1.1、安装ES
安装ES,就3步:下载解压、修改配置文件、启动,本文选择的ES版本是7.10.2。
1.1.1、在Linux机器下载对应版本,然后解压
# 下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.2-linux-x86_64.tar.gz
# 解压
tar -zxvf elasticsearch-7.10.2-linux-x86_64.tar.gz
mv elasticsearch-7.10.2 elasticsearch
1.1.2、修改配置文件
进入elasticsearch目录下的 elasticsearch.yml修改如下属性:
cluster.name:集群名称,根据自己业务启个合适的名字
node.name:给节点起个名字,一般使用node-1 、node-2 、......
path.data:数据存放的位置,比如:/data/elasticsearch/data
path.logs:日志存放的位置,比如:/data/elasticsearch/logs
network.host:配置成本机IP地址,用于集群机器之间相互通信。
http.port:ES服务访问的端口号,比如:9200
discovery.seed_hosts:配置为 master 候选者节点。如果要与其他节点组成集群,这里必须配置。比如:["10.20.1.29", "10.20.0.91", "10.20.0.93"]
cluster.initial_master_nodes:首次启动集群时,配置主节点的候选节点,该配置里的节点都是候选节点。比如:["node-1", "node-2", "node-3"]
1.1.3、启动
进入到elasticsearch目录下执行如下命令启动ES。
./bin/elasticsearch -d
不过一般会出现如下3个错误,一个个搜索解决就行:
- 不能以root用户启动ES,所以在启动之前要先创建一个系统用户,然后
su xxxxxx切换到该用户去启动。 - 虚拟内存不够,报错如下:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]。此时需要修改
sysctl.conf文件,vim /etc/sysctl.conf进入文件,调大vm.max_map_count=262144。 - 可操作性的文件句柄数不够,报错如下:max file descriptors [65535] for elasticsearch process is too low。进入文件
vim /etc/security/limits.conf,调大句柄数。
*** hard nofile 65536
*** soft nofile 65536
1.1.4、访问ES
访问ES地址http://10.20.1.29:9200/,出现如下界面说明成功。
1.2、安装ES集群
比如安装一个3台节点的集群,每台节点安装步骤与单机类似,都是下载解压、修改配置文件、启动。配置需要注意的地方是discovery.seed_hosts和cluster.initial_master_nodes,集群场景下要配置多台。如果安装分词器,每台节点都需要安装,下面会介绍到。
1.3、安装集群可视化工具
一般会使用Chrome插件Multi Elasticsearch Head或者Cerebro这两款工具观察ES集群的整体情况。
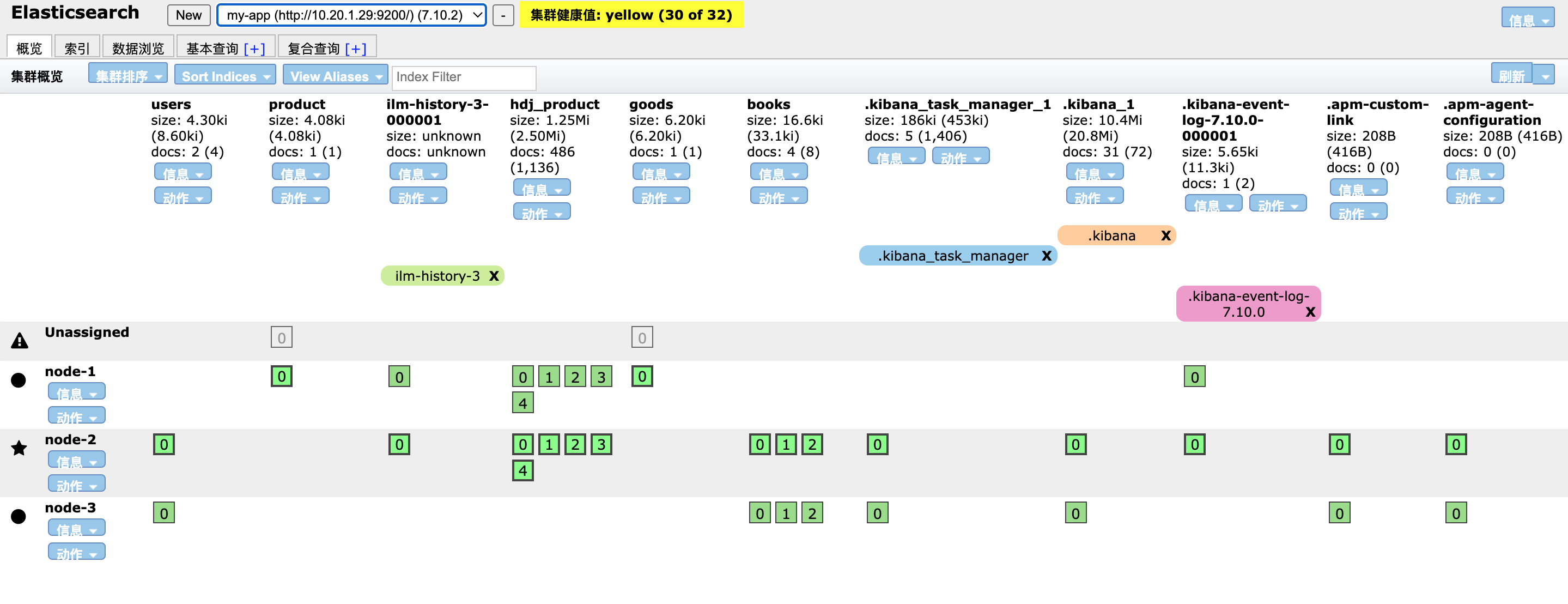
1.3.1、安装Chrome插件-Multi Elasticsearch Head
直接在Chrome浏览器应用市场搜索安装Multi Elasticsearch Head。安装完之后输入ES集群地址,就可以看到集群概况了。这个工具里也有其他功能,很少会使用到,一般只用来观察集群和查看索引数据。
1.3.2、安装Cerebro
Cerebro这款工具与Multi Elasticsearch Head类似,也是用来管理ES集群。Cerebro项目地址:https://github.com/lmenezes/cerebro,这个项目也是好久没更新了。
安装过程,如下:
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.tgz
tar -zxvf cerebro-0.9.4.tgz
cd cerebro-0.9.4
./bin/cerebro >> cerebro.log 2>&1 &
安装之后,界面如下:
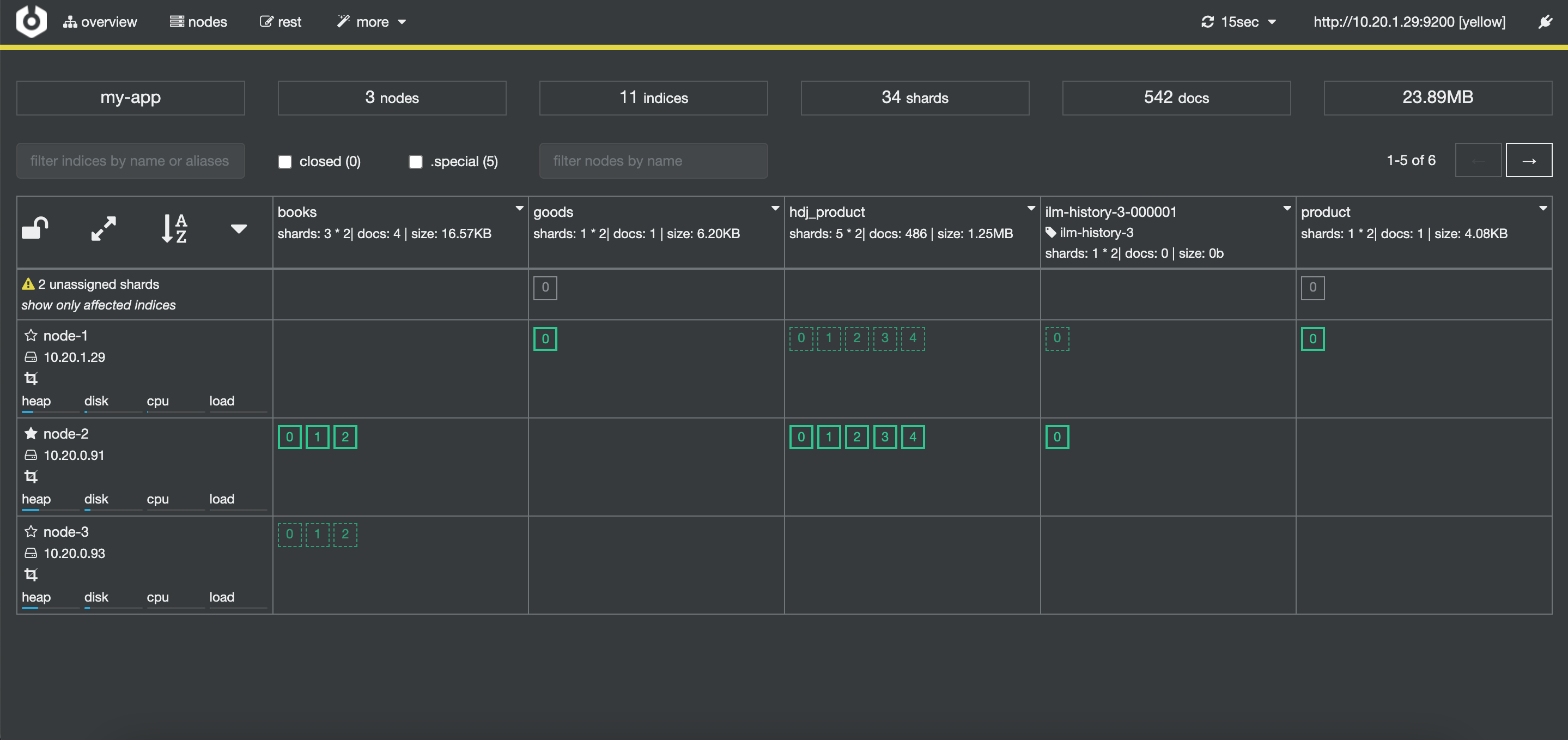
1.4、安装Kibana
Kibana 是数据分析和数据可视化平台,一般配合ELK作为日志整理解决方案,用它来查看日志。虽然有许多应用场景,不过笔者一般用它来查询 ES数据,或者调试ES的接口。
其实Multi Elasticsearch Head和Cerebro也有查询数据的功能,但是整体使用起来没有Kibana方便,也没有智能提示。所以如果想查询ES数据,或者调试ES接口,还是非常建议使用Kibana。
安装过程,如下:
- 下载解压
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.10.0-linux-x86_64.tar.gz
tar -zxvf kibana-7.10.0-linux-x86_64.tar.gz
mv kibana-7.10.0-linux-x86_64 kibana
cd kibana
-
修改配置
server.host:方便外部访问,此处改成"0.0.0.0"elasticsearch.hosts:把ES集群地址全部写上 -
启动,注意备注里写的停止的步骤
# 启动使用如下命令
# 但是停止kibana进程时,需要使用 netstat -tunlp|grep 5601 命令找到进程号,然后kill。
# 直接使用ps -ef|grep kibana是找不到进程的,因为kibana运行在nodejs进程里,或者使用 ps -ef|grep node 查找Nodejs进程,然后kill
./bin/kibana >> kibana.log 2>&1 &
- 访问,http://10.20.1.29:5601/app/dev_tools#/console,进入到开发工具界面:
1.5、简单运行
一般读写ES分为3步:创建Mapping、写入数据、查询数据。
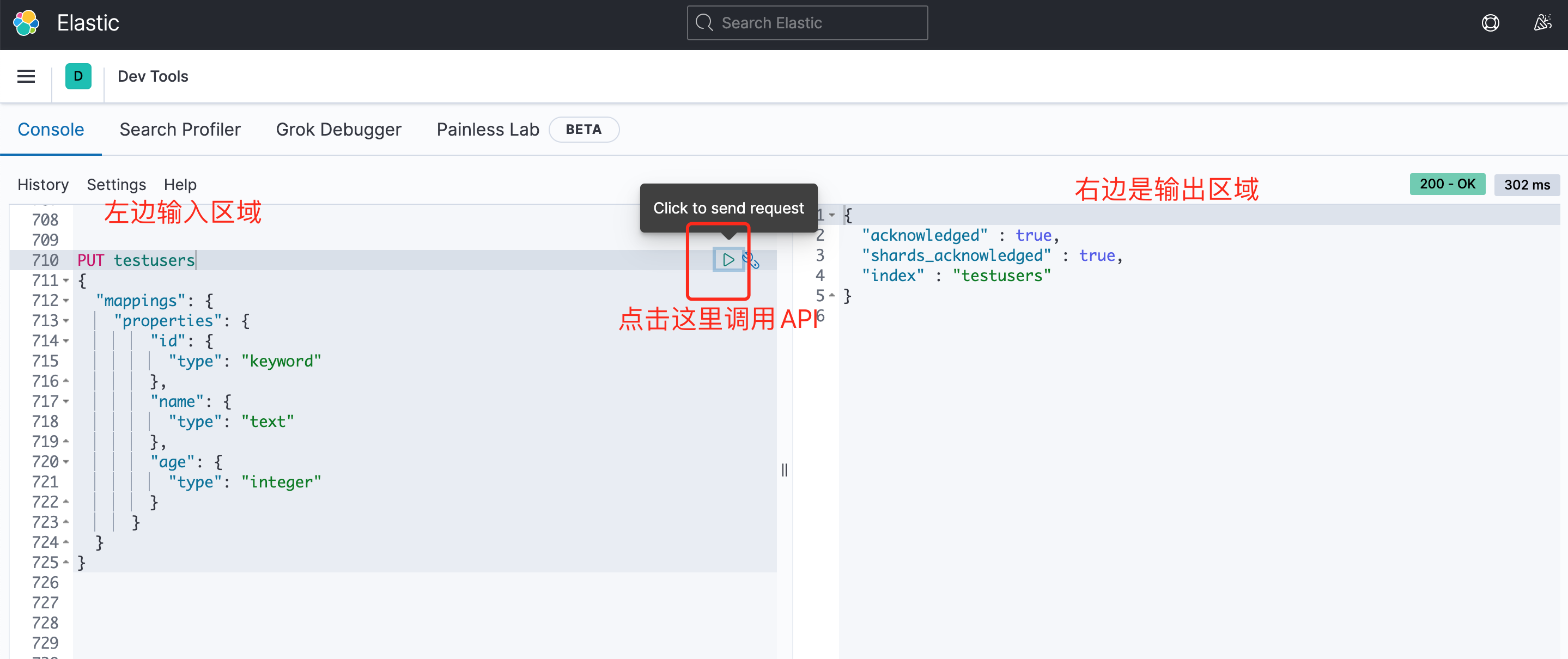
1.5.1、创建Mapping,比如创建一个testusers数据结构
PUT testusers
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
结果如下:
1.5.2、写入数据
POST /testusers/_doc
{
"id":"1",
"name":"不焦躁的程序员",
"age":10
}
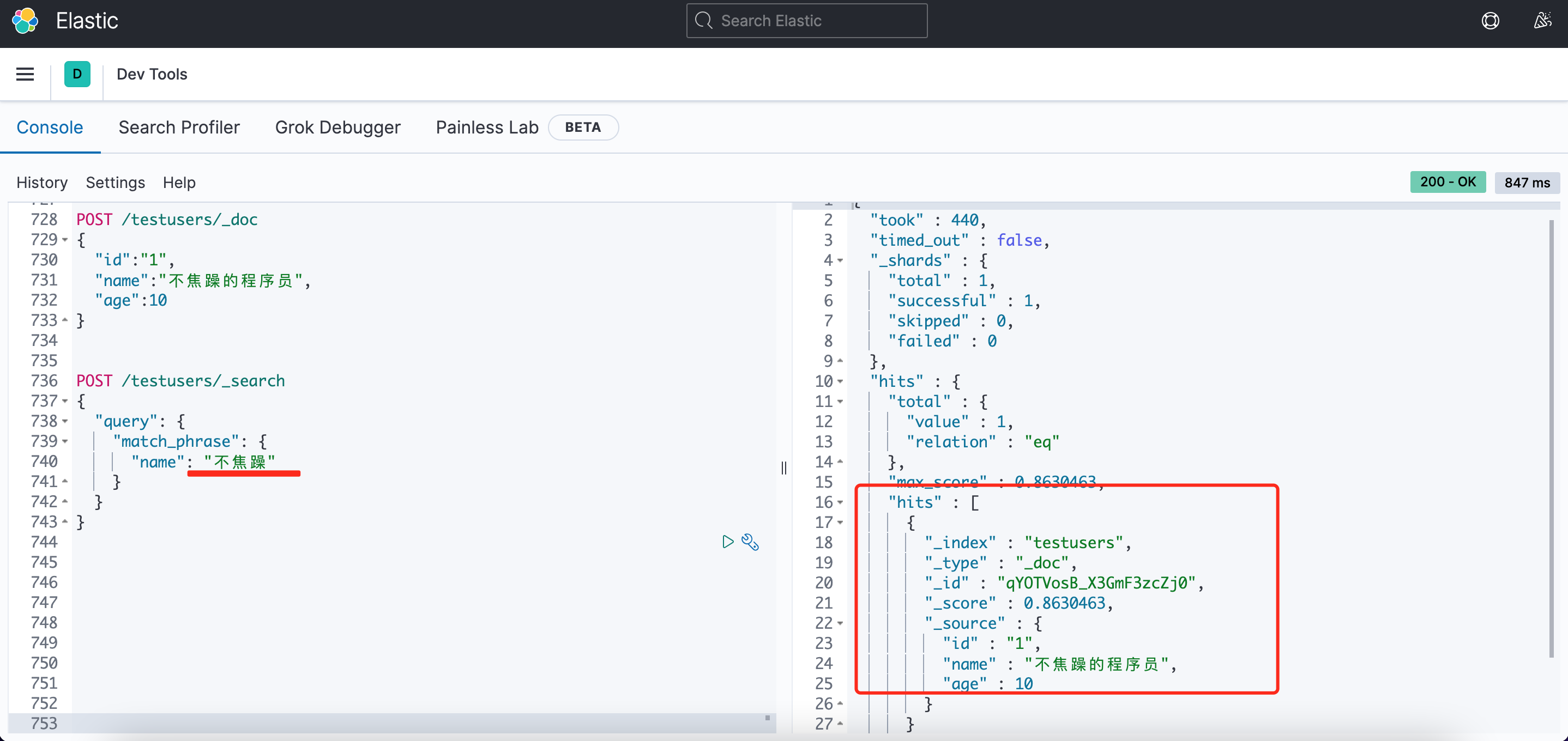
1.5.3、查询数据
POST /testusers/_search
{
"query": {
"match_phrase": {
"name": "不焦躁"
}
}
}
结果如下:
2、基本概念
基础工作准备好之后,就开始了解Elasticsearch里的基本概念了。
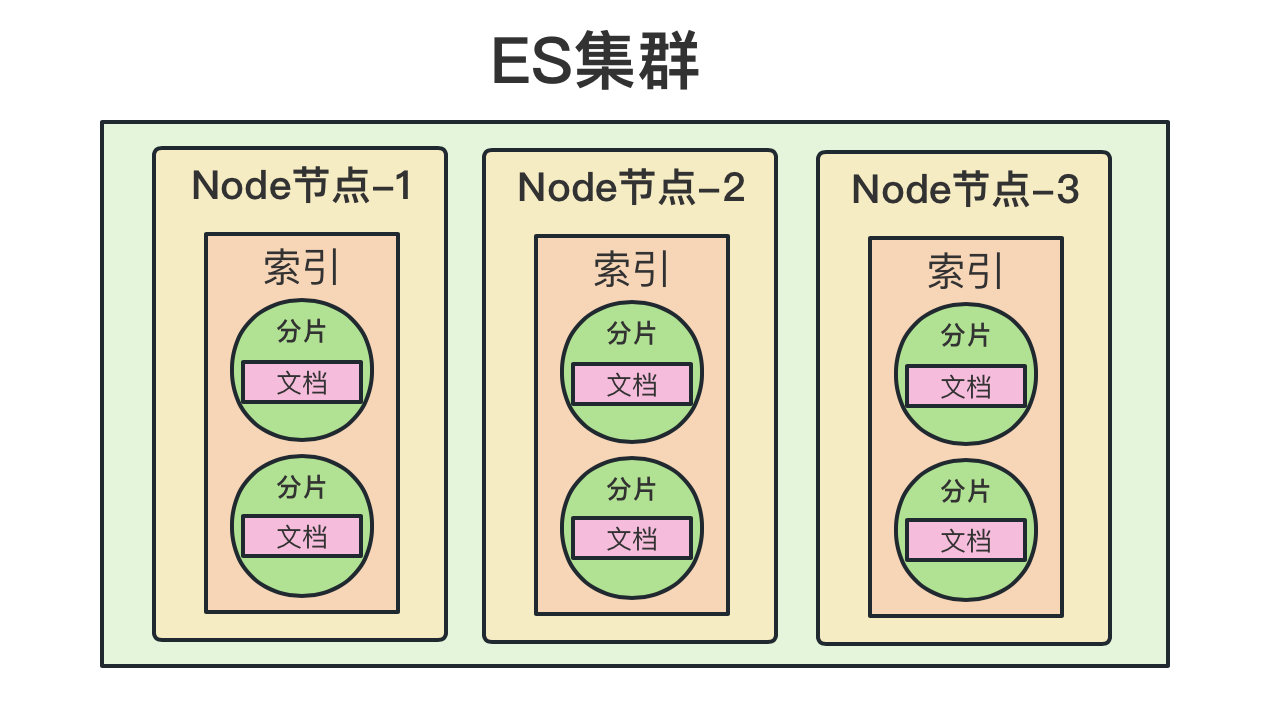
ES的基本概念除了集群、节点之外,还有:索引、Mapping、文档、字段、分词、分词器、分片、副本、倒排索引。
- 索引:索引是某一类文档的集合,类似Mysql的数据库。
- Mapping:Mapping是定义索引中有哪些字段,以及字段类型,以及字段是否会分词等,类似数据库中定义的表结构。
- 文档:文档就是索引里的一条记录,类似数据库表中的一行记录。
- 字段:文档有一个或多个字段,每个字段有指定的类型,常用的类型有:keyword、text、数字类型(integer、long、float、double等)、日期类型、对象类型等。类型是
text类型时,创建文档时ES会对该字段进行分词操作,其余类型则不会做分词。 - 分词:ES里最核心的概念就是
分词了,ES会对text类型的字段进行分词,分词后就会得到一个个的词项,常用Term表述。 - 分词器:ES里有各种各样的分词器,用于不用场景下对
text类型的字段进行分词。 - 分片:分片实际上是将某个索引的数据切分成多个块,然后均匀地将各个块分配到集群里的各个Node节点上。可以通过ES的策略查找数据块所在的Node。这种方案是面向海量数据而设计的,这样数据可以分布在各个节点上,数据量扩张时通过扩充Node数量来快速解决。
- 副本:只要涉及到分布式的场景,几乎都有副本的概念。副本主要是为了备份数据,保障数据的安全性。同时也可以将查询请求分摊到各个副本里,缓解系统压力,提高吞吐量。ES里的数据分为主分片和副本分片,写数据时先写入主分片,然后在异步写入副本分片。
- 倒排索引:比如我们常用的数据库索引,是把索引字段建立目录,保存目录和数据的关系,然后根据目录去查找文档,使用 B+ 树来实现。但是倒排索引(又称反向索引),是根据分词后的Term与文档建立关系,每个Term都对应着一堆文档,然后搜索文本时先将文本分词,然后去匹配Term,然后再去根据匹配的得分找出相关文档。
3、分词器
分词说白了通过分词器将文本转换为各种Term的过程。ES内置了多种分词器,Standard Analyzer 是默认的分词器,它将文本按单词切分并且转为小写,一般用于英文分词,另外还有多种中文分词器,本文以IK分词器为例。
安装IK分词器
在中文场景下,一般会选择IK 分词器。IK分词器需要单独安装,如果是集群场景,每台节点都需要安装,安装如下:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.2/elasticsearch-analysis-ik-7.10.2.zip
在每个节点安装之后,需要重启ES才能使IK分词器 插件生效。
查看分词效果
重启后,可以在 Kibana 中测试一下 IK 分词器的效果。IK分词器有两种模式:ik_max_word 和 ik_smart:
- ik_max_word: 会做细粒度的拆分,尽量找出各种可能的组合。ik_max_word适合Term词项查询,因为Term查询不会对查询文本做分词,所以最好是在创建文档尽量拆分出更多可能性的词,才能尽量的与查询文本匹配上。
Term词项查询会在下文介绍。 - ik_smart: 类似于稍微聪明点的分词,拆分粒度会粗一些。ik_smart适合match phrase 短语匹配查询。因为match phrase 短语匹配查询要求查询文本被分词后要被连续匹配上,所以最好文档在分词时尽量分的粒度要粗一些。
match phrase 短语匹配查询会在下文介绍。
测试ik_max_word场景:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
ik_max_word场景的结果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "国歌",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 9
}
]
}
测试ik_smart场景:
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
ik_smart场景结果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "国歌",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 1
}
]
}
4、文档基本操作
以上将入门内容讲完,下面做一些文档实操。文档基本操作包括:创建索引、新建文档、更新文档、删除文档、查询文档。
4.1、创建Mapping、创建索引
创建Mapping,实际上也是创建索引。
PUT /goods
{
"mappings": {
"properties": {
"brandName": {
"type": "keyword"
},
"categoryName": {
"type": "keyword"
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"id": {
"type": "keyword"
},
"price": {
"type": "double"
},
"saleNum": {
"type": "integer"
},
"status": {
"type": "integer"
},
"stock": {
"type": "integer"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
4.2、新建文档
有2种方式,Index API方式 和 Create API方式:
- Index API方式,这种方式创建文档时,碰到相同的文档id,依旧会创建成功,但会删掉旧的创建新的。
PUT 索引名称/_doc/文档id
PUT goods/_doc/1
{
"id": 1,
"brandName": "Apple",
"categoryName": "手机",
"createTime": "2023-10-22 19:12:56",
"price": 8799,
"saleNum": 599,
"status": 0,
"stock": 1000,
"title": "Apple iPhone 13 Pro (A2639) 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机"
}
- Create API方式,这种方式创建文档时,碰到相同文档id,则创建失败。
PUT 索引名称/_create/文档id
PUT goods/_create/1
{
"id": 1,
"brandName": "Apple",
"categoryName": "手机",
"createTime": "2023-10-22 19:12:56",
"price": 8799,
"saleNum": 599,
"status": 0,
"stock": 1000,
"title": "Apple iPhone 13 Pro (A2639) 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机"
}
4.3、更新文档
POST 索引名称/_update/文档id
POST goods/_update/1
{
"doc": {
"title":"Apple iPhone 13 Pro (A2639) 256GB 远峰蓝色 支持移动联通电信5G 双卡双待手机111"
}
}
4.4、删除文档
DELETE 索引名称/文档id
DELETE goods/_doc/1
4.5、查询文档
查询主要分为:match匹配查询、term词项查询、组合查询、聚合统计。本文主要介绍match匹配查询和term词项查询。
match匹配查询
- match匹配查询
如果查询字段是文本,则会对文本进行分词,只要分词后的Term存在于文档中,就返回对应的文档。
如果查询的字段是日期、keyword、数字等精确类型,则不会进行分词,必须要查询的内容在文档里完全匹配上,才会返回对应的文档。
使用如下:
// 这种方式查到数据
POST goods/_search
{
"query": {
"match": {
"categoryName": "手机"
}
}
}
// 这种方式查不到数据,categoryName是keyword类型,不做分词,必须完全匹配
POST goods/_search
{
"query": {
"match": {
"categoryName": "手机多余"
}
}
}
// 这种方式查到数据
POST goods/_search
{
"query": {
"match": {
"title": "移动"
}
}
}
// 这种方式查到数据,title是text类型,会做分词,只要有分词能匹配上就行
POST goods/_search
{
"query": {
"match": {
"title": "移动多余"
}
}
}
- match phrase短语匹配查询
短语匹配查询要求就比较高了,短语匹配会对查询的内容进行分词,分词后的Term必须全部出现在文档中,并且顺序必须一致,才会返回对应的文档,当然这个一致的程度也是可以调整的。
使用如下:
// 这样可以查到数据
POST goods/_search
{
"query": {
"match_phrase": {
"title": "移动联通"
}
}
}
// 这样查不到数据,短语匹配时,虽然做了分词,但是要分词后的顺序一致,索引匹配补上
POST goods/_search
{
"query": {
"match_phrase": {
"title": "联通移动"
}
}
}
Term词项查询
Term词项查询 与match查询,有个最大的区别,Term 词项查询时ES不会对检索内容进行分词,会将检索文本作为一个整体进行查询。而match查询会对检索内容做分词,然后对分词后的各个词项做查询。
使用如下:
// 这样查到数据,因为基于文档的内容分词后,建立的倒排索引里,有“移动”、“联通”索引,但是没有“移动联通”这个索引
POST goods/_search
{
"query": {
"match": {
"title": "移动联通"
}
}
}
// 这样查不到数据,因为基于文档的内容分词后,建立的倒排索引里,没有“移动联通”这个索引,因为term查询不分词。
POST goods/_search
{
"query": {
"term": {
"title": {
"value": "移动联通"
}
}
}
}
5、总结
本文从安装、基本概念、分词器、文档基本操作这4个方面带你快速入门Elasticsearch。所有的文档在写入时,只要字段是text类型都会被分词,然后建立倒排索引。需要特别注意的点是:match匹配查询会对查询文本做分词,Term词项查询不会对查询文本做分词。
本篇完结!感谢你的阅读,欢迎点赞 关注 收藏 私信!!!
原文链接:http://www.mangod.top/articles/2023/10/23/1698024179725.html、https://mp.weixin.qq.com/s/mD7Nj-BC27YYRXlLu1kOCA


 浙公网安备 33010602011771号
浙公网安备 33010602011771号