
经典卷积神经网络 - VGG
使用块的网络 - VGG。
使用多个 3 × 3 3\times 3 3×3的要比使用少个 5 × 5 5\times 5 5×5的效果要好。
VGG全称是Visual Geometry Group,因为是由Oxford的Visual Geometry Group提出的。AlexNet问世之后,很多学者通过改进AlexNet的网络结构来提高自己的准确率,主要有两个方向:小卷积核和多尺度。而VGG的作者们则选择了另外一个方向,即加深网络深度。
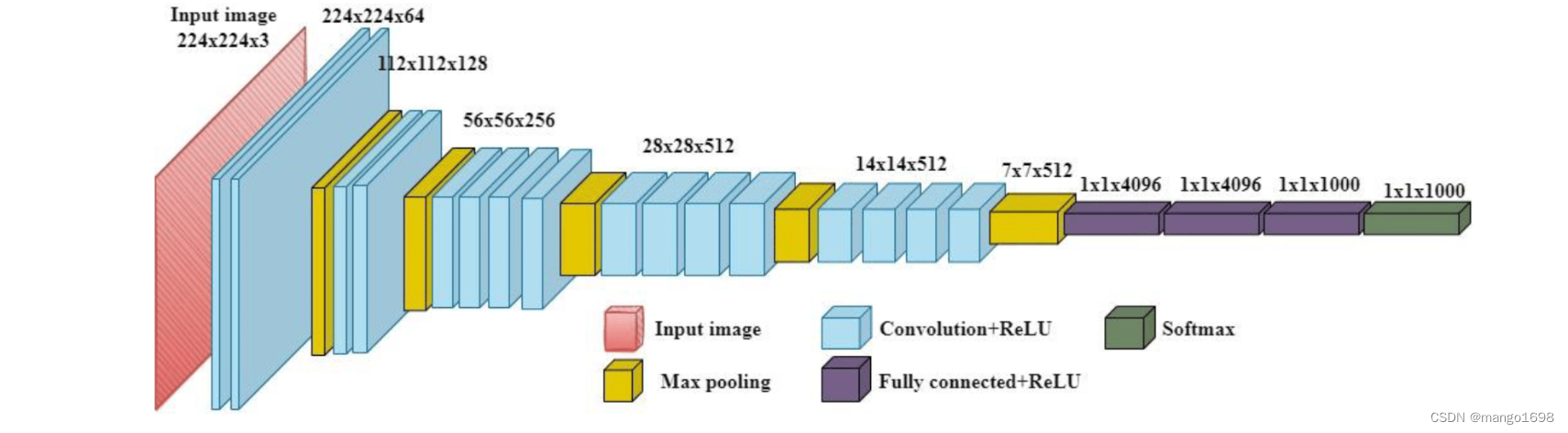
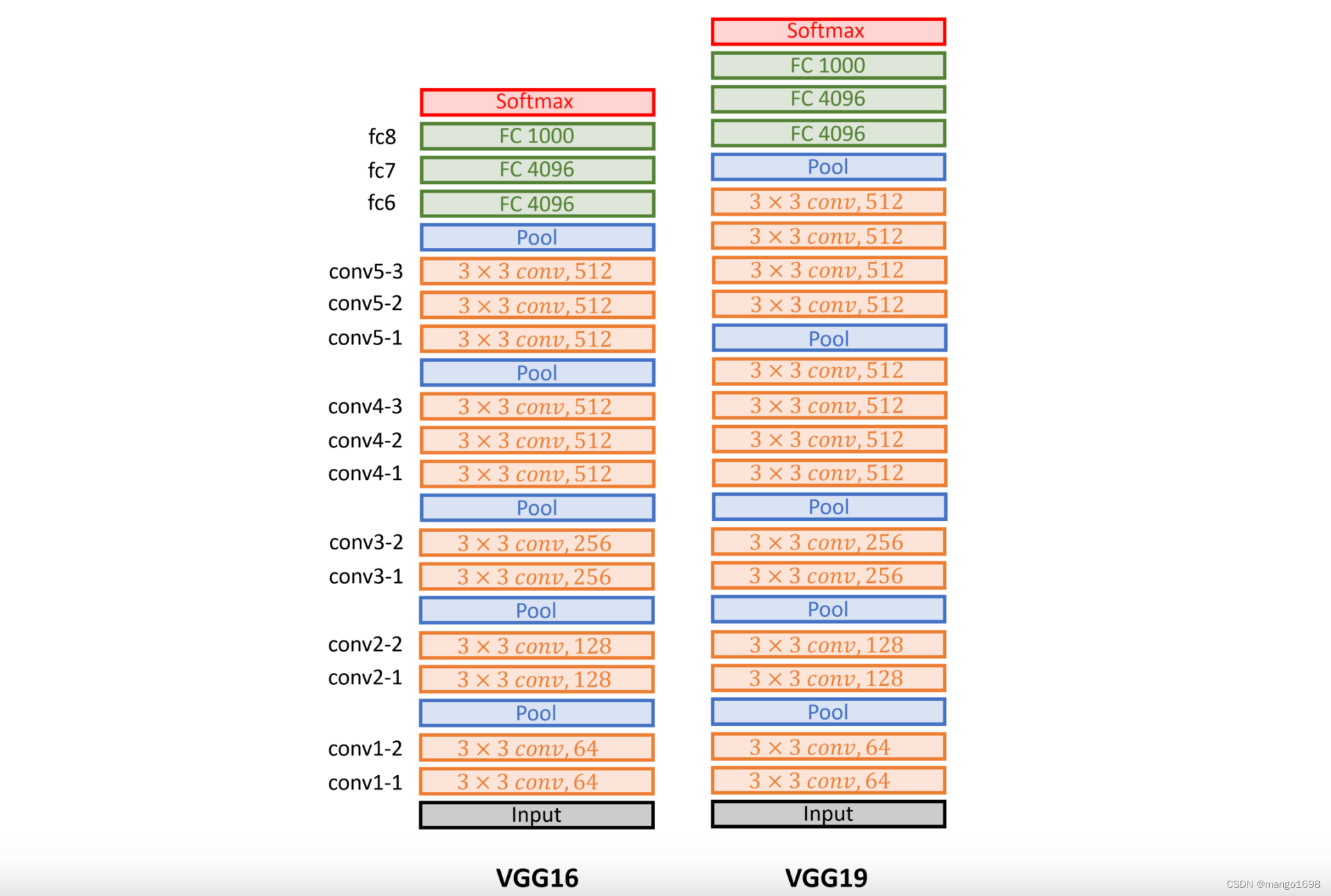
网络架构
卷积网络的输入是224 * 224的RGB图像,整个网络的组成是非常格式化的,基本上都用的是3 * 3的卷积核以及 2 * 2的max pooling,少部分网络加入了1 * 1的卷积核。因为想要体现出“上下左右中”的概念,3*3的卷积核已经是最小的尺寸了。
VGG16相比之前网络的改进是3个33卷积核来代替7x7卷积核,2个33卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,减少参数,提升了网络的深度。
多个VGG块后接全连接层。
不同次数的重复块得到不同的架构,如VGG-16,VGG-19等。
VGG:更大更深的AlexNet。
总结:
- VGG使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
代码实现
使用数据集CIFAR
model.py
"""
@Author :shw
@Date :2023/10/23 16:35
"""
from torch import nn
# 输入图像大小 224x224x3
class VGG(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.features = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64), # 出现了梯度消失问题,所以使用了BN层
nn.ReLU(inplace=True),
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(256,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(512, 512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(7*7*512,4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 10),
# 使用了交叉熵损失函数后,最后一层不再需要使用softmax
# nn.Softmax()
)
def forward(self,x):
x = self.features(x)
x = self.avgpool(x)
x = self.classifier(x)
return x
train.py
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch import nn
import torch
from model import VGG
class Train:
def __init__(self):
self.epochs = 10
self.lr = 1e-4 # 1e-3 -> 1e-4
self.train_step = 0
self.test_step = 0
self.batch_size = 64 # 32->64
self.train_size = None
self.test_size = None
self.train_loader = None
self.test_loader = None
def get_data(self):
transformer = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
train_data = datasets.CIFAR10(root="./dataset", train=True, transform=transformer, download=True)
test_data = datasets.CIFAR10(root="./dataset", train=False, transform=transformer, download=True)
self.train_size = len(train_data)
self.test_size = len(test_data)
self.train_loader = DataLoader(train_data, batch_size=self.batch_size, shuffle=True, num_workers=0)
self.test_loader = DataLoader(test_data, batch_size=self.batch_size, shuffle=True, num_workers=0)
print("训练集大小:{}".format(self.train_size))
print("测试集大小:{}".format(self.test_size))
def get_accuracy(self, accuracy_num, size):
return accuracy_num / size
def train(self):
self.get_data()
device = torch.device("cpu")
if torch.backends.mps.is_available():
device = torch.device("mps")
elif torch.cuda.is_available():
device = torch.device("cuda")
vgg = VGG()
vgg = vgg.to(device)
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
loss_func = loss_func.to(device)
# 定义优化器
# optimizer = torch.optim.SGD(vgg.parameters(), lr=self.lr, momentum=0.9)
optimizer = torch.optim.Adam(vgg.parameters(),lr=self.lr,betas=(0.9,0.999),eps=1e-08)
writer = {
'train': SummaryWriter(log_dir="./logs/t2/train"),
'test': SummaryWriter(log_dir="./logs/t2/test")
}
for epoch in range(self.epochs):
print("-------------------第 {} 个Epoch训练开始-------------------".format(epoch + 1))
total_train_accuracy_num = 0
total_test_accuracy_num = 0
total_test_loss = 0
total_train_loss = 0
vgg.train()
for data in self.train_loader:
self.train_step += 1
images, targets = data
images = images.to(device)
targets = targets.to(device)
outputs = vgg(images)
loss_out = loss_func(outputs, targets)
vgg.zero_grad()
loss_out.backward()
optimizer.step()
if self.train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(self.train_step, loss_out))
writer['train'].add_scalar('Train Loss', loss_out, self.train_step)
total_train_accuracy_num += (torch.argmax(outputs,dim=1) == targets).sum()
total_train_loss += loss_out
train_accuracy =self.get_accuracy(total_train_accuracy_num , self.train_size)
writer['train'].add_scalar("Accuracy", train_accuracy, epoch + 1)
# print("Epoch:{},Train Accuracy:{}".format(epoch+1,train_accuracy))
# print("Epoch:{},Total Train Loss:{}".format(epoch+1,total_train_loss))
vgg.eval()
with torch.no_grad():
for data in self.test_loader:
self.test_step += 1
images, targets = data
images = images.to(device)
targets = targets.to(device)
outputs = vgg(images)
loss_out = loss_func(outputs, targets)
total_test_loss += loss_out
total_test_accuracy_num += (torch.argmax(outputs,dim=1) == targets).sum()
test_accuracy = self.get_accuracy(total_test_accuracy_num, self.test_size)
# print("Epoch:{},Test Accuracy:{}".format(epoch + 1, test_accuracy))
# print("Epoch:{},Total Test Loss:{}".format(epoch + 1, total_test_loss))
print("Epoch:{},Train Loss:{},Test Loss:{},Train Accuracy:{},Test Accuracy:{}".format(epoch + 1,
total_train_loss,
total_test_loss,
train_accuracy,
test_accuracy))
writer['test'].add_scalar("Test Total Loss", total_test_loss, epoch + 1)
writer['test'].add_scalar("Accuracy", test_accuracy, epoch + 1)
torch.save(vgg,"./model/vgg_{}.pth".format(epoch+1))
writer['test'].close()
writer['train'].close()
main.py
from train import Train
if __name__ == '__main__':
train = Train()
train.train()

