
经典卷积神经网络 - NIN
网络中的网络,NIN。
AlexNet和VGG都是先由卷积层构成的模块充分抽取空间特征,再由全连接层构成的模块来输出分类结果。但是其中的全连接层的参数量过于巨大,因此NiN提出用1*1卷积代替全连接层,串联多个由卷积层和“全连接”层构成的小网络来构建⼀个深层网络。
AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。
或者,可以想象在这个过程的早期使用全连接层。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。
网络中的网络(NiN)提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机。也就是使用了多个1*1的卷积核。同时他认为全连接层占据了大量的内存,所以整个网络结构中没有使用全连接层。
NIN块
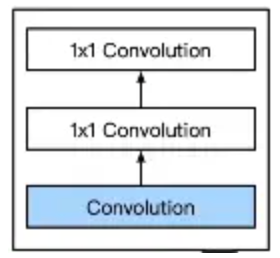
一个卷积层后跟两个全连接层。
- 步幅为1,无填充,输出形状跟卷积层输出一样。
- 起到全连接层的作用。
NIN网络结构

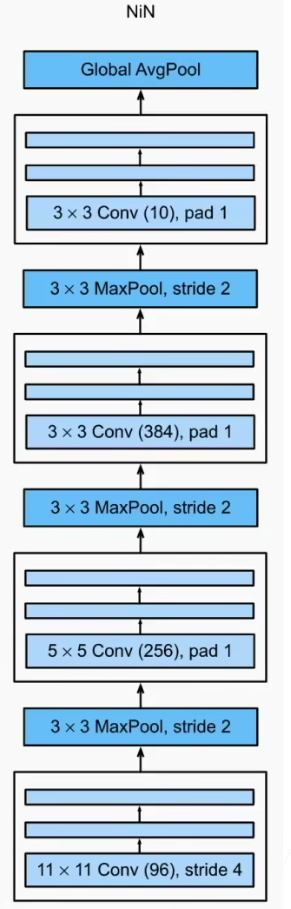
-
无全连接层
-
交替使用NIN块和步幅为2的最大池化层
逐步减小高宽和增大通道数
-
最后使用全局平均池化层得到输出
其输入通道数是类别数
此网络结构总计4层: 3mlpconv + 1global_average_pooling
优点:
- 提供了网络层间映射的一种新可能;
- 增加了网络卷积层的非线性能力。
总结:
- NIN块使用卷积层加上个 1 × 1 1\times 1 1×1卷积,后者对每个像素增加了非线性性
- NIN使用全局平均池化层来替代VGG和AlexNet中的全连接层,不容易过拟合,更少的参数个数
代码实现
使用CIFAR-10数据集。
maxpooling不改变通道数,只改变长和宽
model.py
import torch
from torch import nn
# nin块
def nin_block(in_channels,out_channels,kernel_size,strides,padding):
return nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size,strides,padding),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1),
nn.ReLU(),
)
# 构建网络
class NIN(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.model = nn.Sequential(
nin_block(3,96,kernel_size=11,strides=4,padding=0),
nn.MaxPool2d(3,stride=2),
nin_block(96,256,kernel_size=5,strides=1,padding=2),
nn.MaxPool2d(3,stride=2),
nin_block(256,384,kernel_size=3,strides=1,padding=1),
nn.MaxPool2d(3,stride=2),
nn.Dropout(0.5),
nin_block(384,10,kernel_size=3,strides=1,padding=1),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten()
)
def forward(self,x):
return self.model(x)
# 验证模型正确性
if __name__ == '__main__':
nin = NIN()
x = torch.ones((64,3,244,244))
output = nin(x)
print(output)
train.py
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets
from torchvision.transforms import transforms
from model import NIN
# 扫描数据次数
epochs = 3
# 分组大小
batch = 64
# 学习率
learning_rate = 0.01
# 训练次数
train_step = 0
# 测试次数
test_step = 0
# 定义图像转换
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor()
])
# 读取数据
train_dataset = datasets.CIFAR10(root="./dataset",train=True,transform=transform,download=True)
test_dataset = datasets.CIFAR10(root="./dataset",train=False,transform=transform,download=True)
# 加载数据
train_dataloader = DataLoader(train_dataset,batch_size=batch,shuffle=True,num_workers=0)
test_dataloader = DataLoader(test_dataset,batch_size=batch,shuffle=True,num_workers=0)
# 数据大小
train_size = len(train_dataset)
test_size = len(test_dataset)
print("训练集大小:{}".format(train_size))
print("验证集大小:{}".format(test_size))
# GPU
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(device)
# 创建网络
net = NIN()
net = net.to(device)
# 定义损失函数
loss = nn.CrossEntropyLoss()
loss = loss.to(device)
# 定义优化器
optimizer = torch.optim.SGD(net.parameters(),lr=learning_rate)
writer = SummaryWriter("logs")
# 训练
for epoch in range(epochs):
print("-------------------第 {} 轮训练开始-------------------".format(epoch))
net.train()
for data in train_dataloader:
train_step = train_step + 1
images,targets = data
images = images.to(device)
targets = targets.to(device)
outputs = net(images)
loss_out = loss(outputs,targets)
optimizer.zero_grad()
loss_out.backward()
optimizer.step()
if train_step%100==0:
writer.add_scalar("Train Loss",scalar_value=loss_out.item(),global_step=train_step)
print("训练次数:{},Loss:{}".format(train_step,loss_out.item()))
# 测试
net.eval()
total_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
test_step = test_step + 1
images, targets = data
images = images.to(device)
targets = targets.to(device)
outputs = net(images)
loss_out = loss(outputs, targets)
total_loss = total_loss + loss_out
accuracy = (targets == torch.argmax(outputs,dim=1)).sum()
total_accuracy = total_accuracy + accuracy
# 计算精确率
print(total_accuracy)
accuracy_rate = total_accuracy / test_size
print("第 {} 轮,验证集总损失为:{}".format(epoch+1,total_loss))
print("第 {} 轮,精确率为:{}".format(epoch+1,accuracy_rate))
writer.add_scalar("Test Total Loss",scalar_value=total_loss,global_step=epoch+1)
writer.add_scalar("Accuracy Rate",scalar_value=accuracy_rate,global_step=epoch+1)
torch.save(net,"./model/net_{}.pth".format(epoch+1))
print("模型net_{}.pth已保存".format(epoch+1))

