


目标检测算法-SSD
1. SSD介绍
计算机确定图像中一个物体的位置需要四个参数:中心点的x轴、y轴坐标、框的高和宽。
当一张图片被传入SSD的网络中时,图片首先会被调整为300*300的大小。为了防止失真,其会在图片的边缘加上灰条。
之后SSD会将这种图片分为六种不同大小的网格,分别为 38 × 38 , 5 × 5 , 19 × 19 , 3 × 3 , 10 × 10 , 1 × 1 38\times 38,5\times 5,19\times 19,3\times 3,10\times 10,1\times 1 38×38,5×5,19×19,3×3,10×10,1×1的网格。
由于图像经过多次卷积压缩后,小物体的特征容易消失,所以 38 × 38 , 19 × 19 38\times 38,19\times 19 38×38,19×19的网格用于检测小物体, 3 × 3 , 1 × 1 3\times 3,1\times 1 3×3,1×1的网格用于检测大物体。
对于下图中的猫来说,它在图像中属于一个比较大的物体,因此使用 5 × 5 5\times 5 5×5或者 3 × 3 3\times 3 3×3的网格来检测。
每个网格中心负责网格内部物体的检测,如果物体的中心落在这个区域,这个物体的位置就由这个网格点来确定。
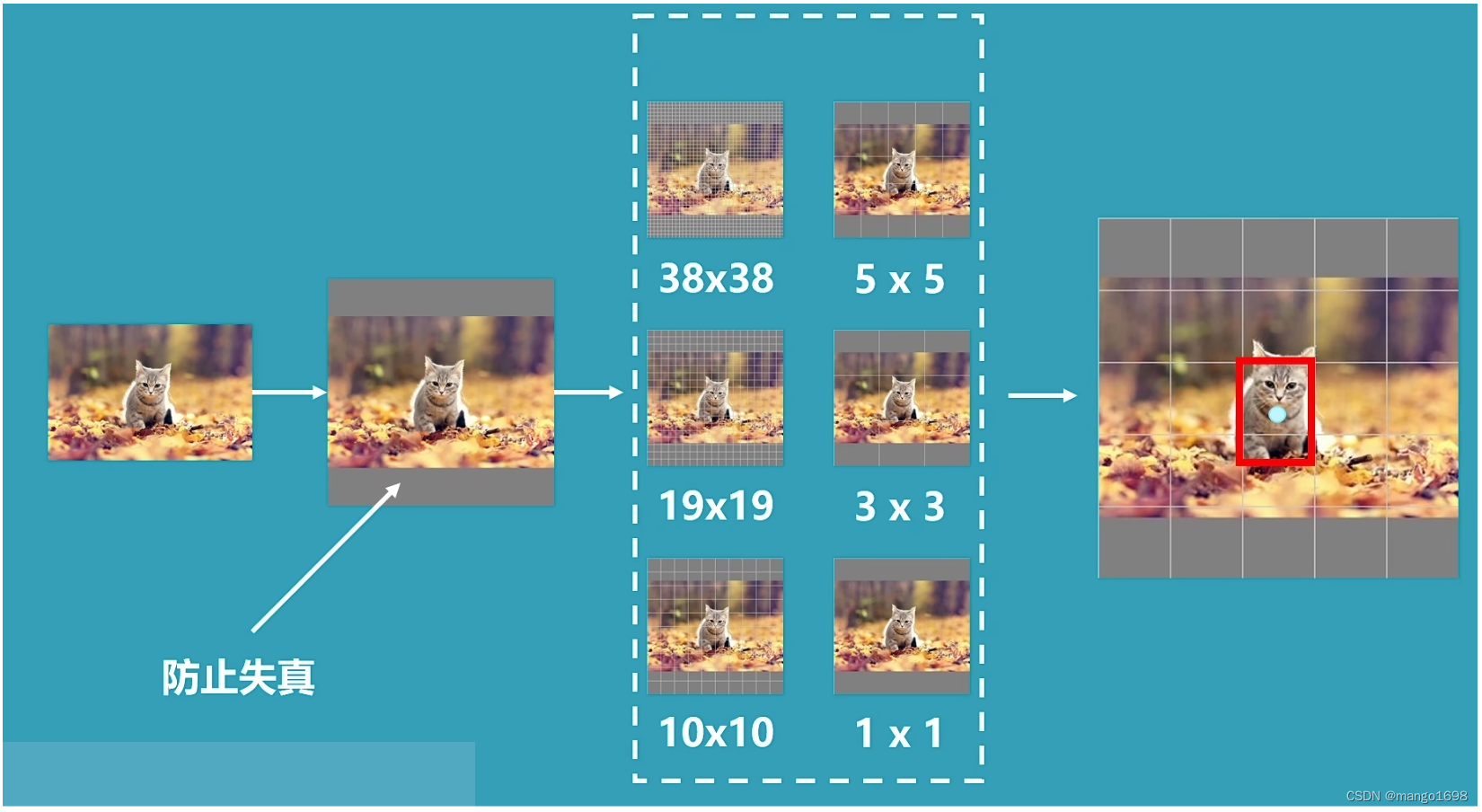
总结而言,SSD不过是把一张踢平划分成不同的网格,当某一个物体的中心点落在这个区域,这个物体就由这个网格来确定。
2. SSD网络整体结构
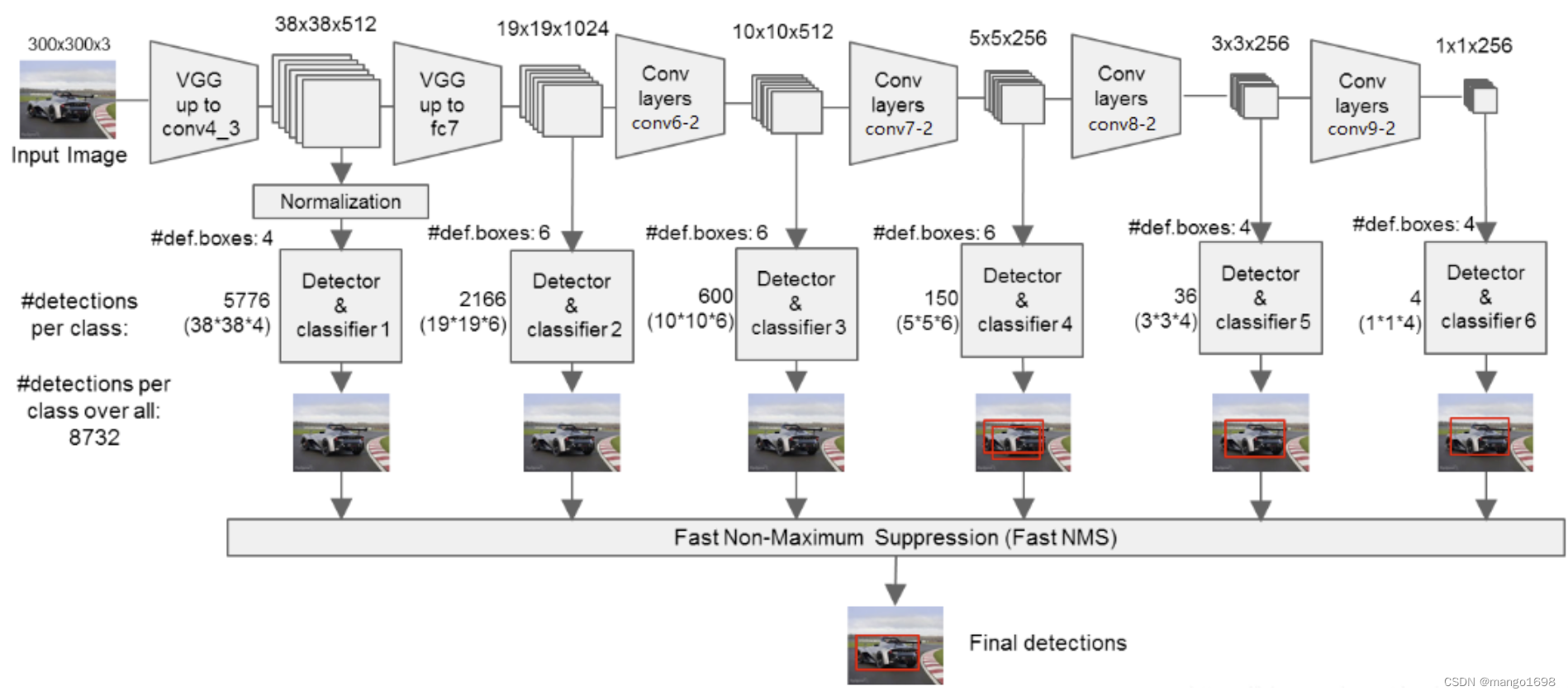
特征提取:在VGG的基础上进行改变,增加一些卷积层。
先验框,即锚框。
每一个网格都存在先验框,它以网格的中心为中心,存在多个先验框。这些先验框是我们事先在图中生成好的,我们之后的预测结果就会对这些先验框进行调整,获得我们的预测结果。
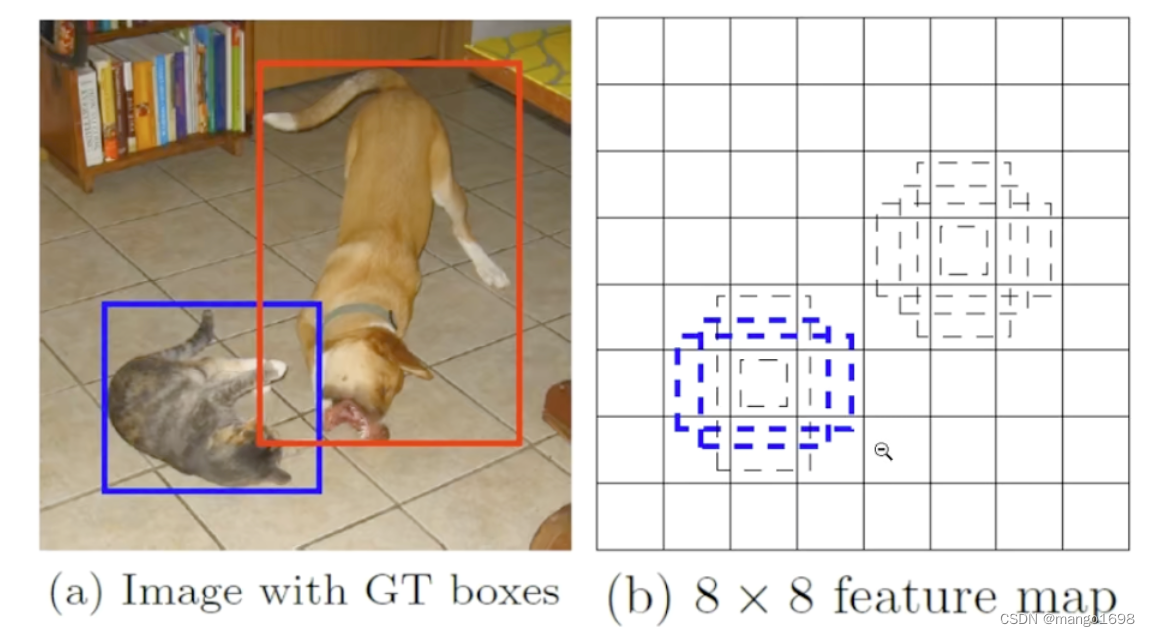
如 38 × 38 38\times 38 38×38的网格,每个网格对应来4个先验框。
3. 特征提取模块
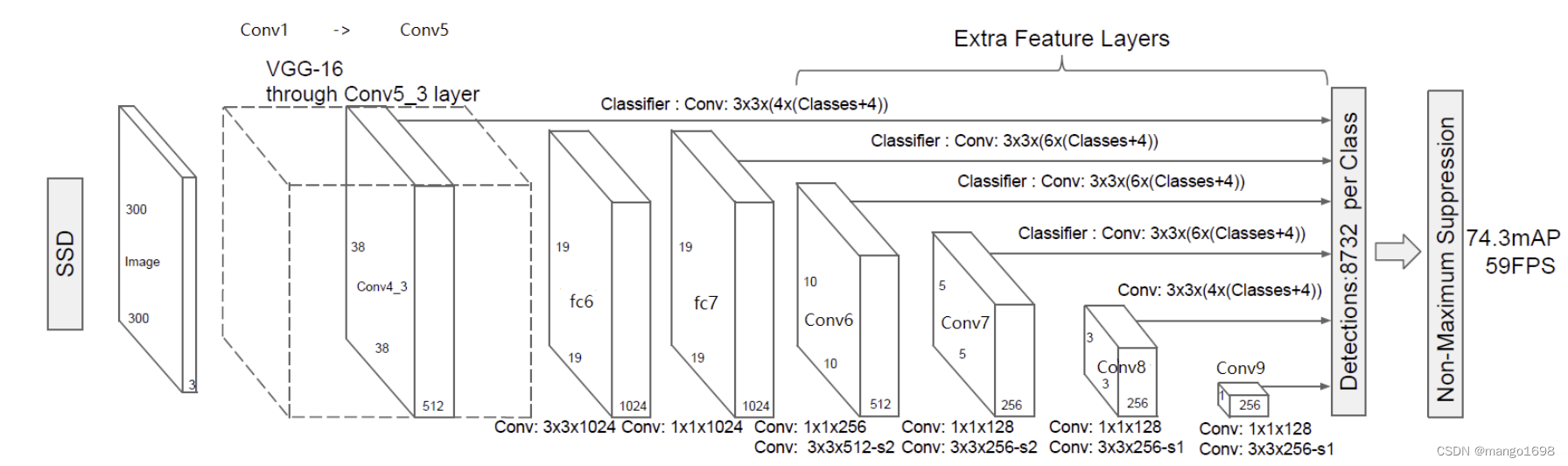
如图所示,输入的图片经过了改进的VGG网络(Conv1->fc7)和几个另加的卷积层(Conv6->Conv9),进行特征提取:
-
输入一张图片后,被resize到300x300的shape
-
conv1,经过两次[3,3]卷积网络,输出的特征层为64,输出为(300,300,64),再2X2最大池化,该最大池化步长为2,输出net为(150,150,64)。
-
conv2,经过两次[3,3]卷积网络,输出的特征层为128,输出net为(150,150,128),再2X2最大池化,该最大池化步长为2,输出net为(75,75,128)。
-
conv3,经过三次[3,3]卷积网络,输出的特征层为256,输出net为(75,75,256),再2X2最大池化,该最大池化步长为2,输出net为(38,38,256)。
-
conv4,经过三次[3,3]卷积网络,输出的特征层为512,输出net为(38,38,512),再2X2最大池化,该最大池化步长为2,输出net为(19,19,512)。
-
conv5,经过三次[3,3]卷积网络,输出的特征层为512,输出net为(19,19,512),再3X3最大池化,该最大池化步长为1,输出net为(19,19,512)。
-
利用卷积代替全连接层,进行了一次[3,3]卷积网络和一次[1,1]卷积网络,分别为fc6和fc7,输出的通道数为1024,因此输出的net为(19,19,1024)。(从这里往前都是VGG的结构)
-
conv6,经过一次[1,1]卷积网络,调整通道数,一次步长为2的[3,3]卷积网络,输出的通道数为512,因此输出的net为(10,10,512)。
-
conv7,经过一次[1,1]卷积网络,调整通道数,一次步长为2的[3,3]卷积网络,输出的通道数为256,因此输出的net为(5,5,256)。
-
conv8,经过一次[1,1]卷积网络,调整通道数,一次padding为valid的[3,3]卷积网络,输出的通道数为256,因此输出的net为(3,3,256)。
-
conv9,经过一次[1,1]卷积网络,调整通道数,一次padding为valid的[3,3]卷积网络,输出的特征层为256,因此输出的net为(1,1,256)。
在第三次卷积后,经过的最大池化,指定ceil_mode=True,解释:
步长为2,75/2不为一个整数,需要进行处理。如果将ceil_mode指定为False,就会将多余的舍弃掉。


