
Python爬虫 - 网易云音乐下载
爬取网易云音乐实战,仅供学习,不可商用,出现问题,概不负责!
分为爬取网易云歌单和排行榜单两部分。
因为网页中,只能显示出歌单的前20首歌曲,所以仅支持下载前20首歌曲(非VIP音乐)
具体过程:
1.通过抓包,获取到请求头
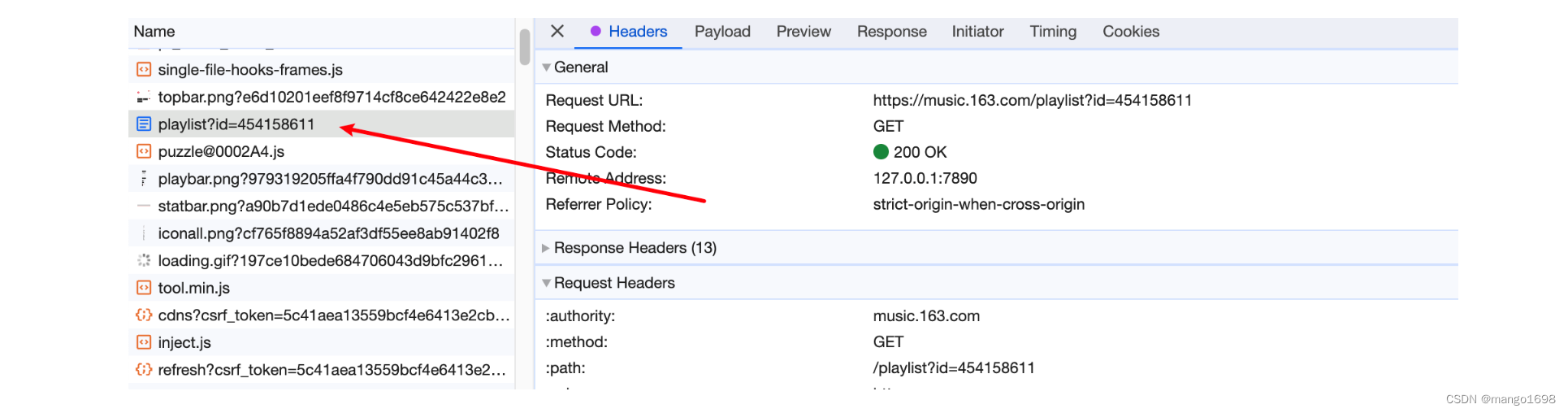
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "替换为自己的Cookie",
"Sec-Ch-Ua-Platform": "macOS",
"Sec-Fetch-Dest": "iframe",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Upgrade-Insecure-Requests": "1"
}
2.发送请求,获取到网页源代码,通过Xpath进行解析,获取到歌曲名称,歌手名字,以及歌曲id
url = input("请输入要抓取的歌单链接:")
url = url.replace("/#", "")
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
res = res.text
html = etree.HTML(res)
title = html.xpath('//h2[@class="f-ff2 f-brk"]/text()')
songs = html.xpath('//ul[@class="f-hide"]/li/a/@href')
names = html.xpath('//ul[@class="f-hide"]/li/a/text()')
3.并分别对歌单创建单独的文件夹,进行歌曲存放
if len(title)!=0:
path = './网易云歌单/' + title[0] + "/"
else:
path = "./网易云歌单/未知歌单/"
if not os.path.exists(path):
os.makedirs(path)
4.判断是否为VIP歌曲,将VIP歌曲排除
for i in range(len(music_urls)):
try:
res = requests.get(music_urls[i], headers=headers).content.decode('utf-8')
if res.find('很抱歉,你要查找的网页找不到') != -1:
print(names[i] + ',VIP专属歌曲,无法下载')
remove_url.append(music_urls[i])
remove_name.append(names[i])
continue
except:
pass
for item in remove_name:
names.remove(item)
for url in remove_url:
music_urls.remove(url)
5.下载歌曲
for i in range(len(music_urls)):
try:
print('正在下载..', names[i])
res = requests.get(music_urls[i], headers=headers)
with open(path + names[i] + ".mp3", "wb") as f:
f.write(res.content)
print('下载成功..', names[i])
except Exception as e:
if os.path.exists(path + names[i] + ".mp3"):
os.remove(path + names[i] + ".mp3")
print('下载失败,请联系管理员')
6.对于排行榜部分,和歌单逻辑基本相同
url = input("请输入榜单链接:")
url = url.replace("/#", "")
res = requests.get(url, headers=headers)
res.encoding = 'utf-8'
res = res.text
html = etree.HTML(res)
title = html.xpath('//h2[@class="f-ff2"]/text()')
songs = html.xpath('//ul[@class="f-hide"]/li/a/@href')
names = html.xpath('//ul[@class="f-hide"]/li/a/text()')
if len(title)!=0:
path = './网易云歌单/' + title[0] + "/"
else:
path = "./网易云歌单/未知歌单/"
if not os.path.exists(path):
os.makedirs(path)
for item in songs:
temp = str(item).replace("/song?id=", "")
ids.append(temp)
music_urls = []
for id in ids:
music_urls.append(baseUrl + id + '.mp3')
downLoad(music_urls, names, path)
下载部分与下载歌单歌曲相同。
结果:


完整代码
联系邮箱:mango_1698@163.com

