
目标检测 - FPN结构
论文:Feature Pyramid Networks for Object Detection
网址:https://arxiv.org/abs/1612.03144
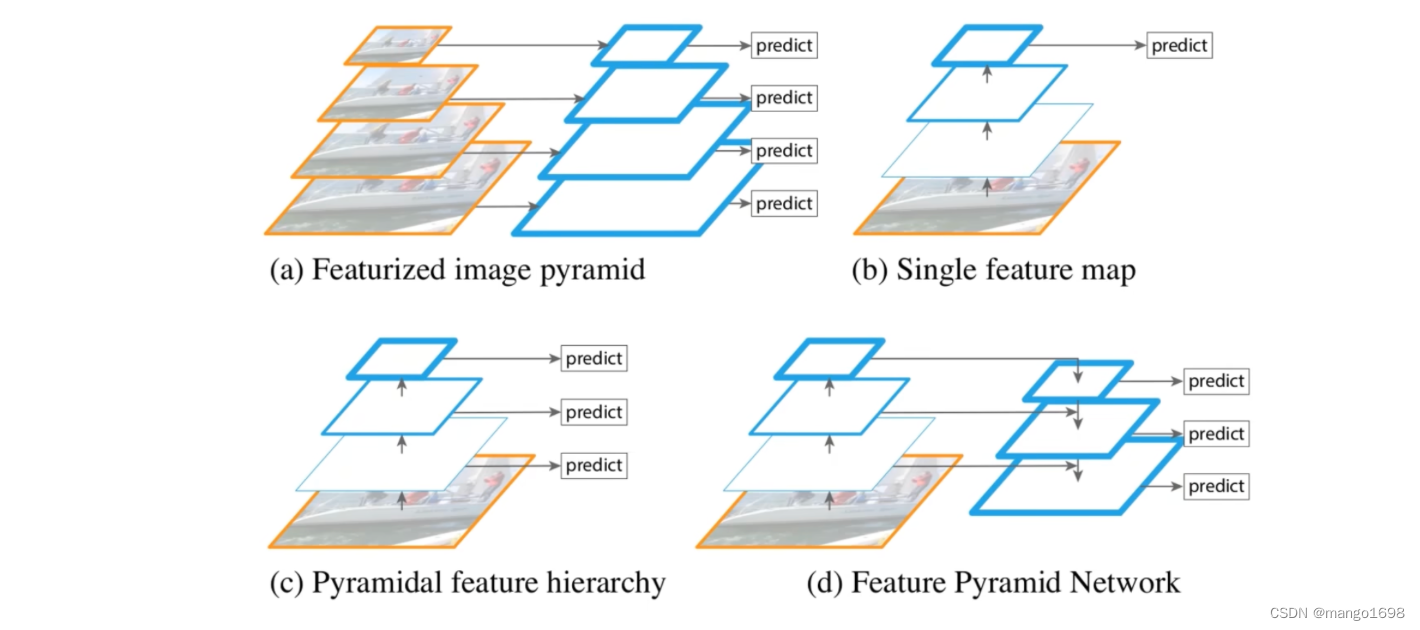
图a为特征图像金字塔,针对我们要检测不同尺度的目标时,我们会将图片缩放到不同的尺度,针对每个尺度的图片都经过我们的模型进行预测。面临问题:生成n个不同的尺度,就要重新预测n次,这样效率是很低的。
图b为Faster-CNN采用的一种方式,图片通过backbone得到最终的特征图,在最终的特征图上进行预测。这种情况下,针对小目标的预测并不是很好。
图c,与SSD算法很类似,将一张图片通过backbone,在backbone正向传播过程中得到的不同尺度的特征图上分别进行预测。
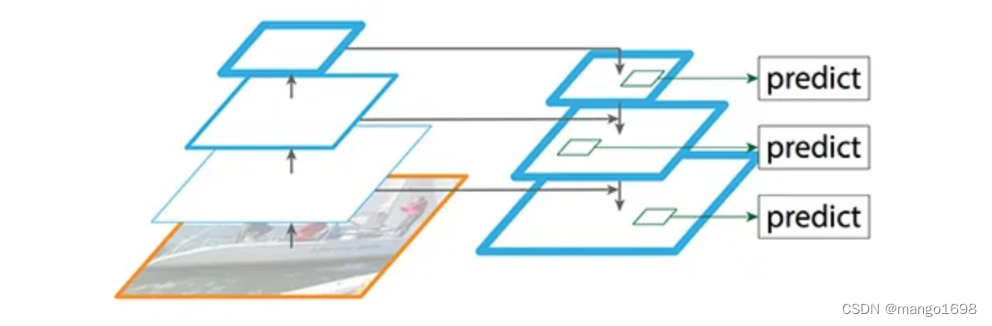
图d为FPN结构,并不是简单的在backbone得到的不同尺度的特征图上进行预测,而是将不同特征图上的特征进行融合,在融合所得到的特征图上,再进行预测。
那么该如何进行融合呢?
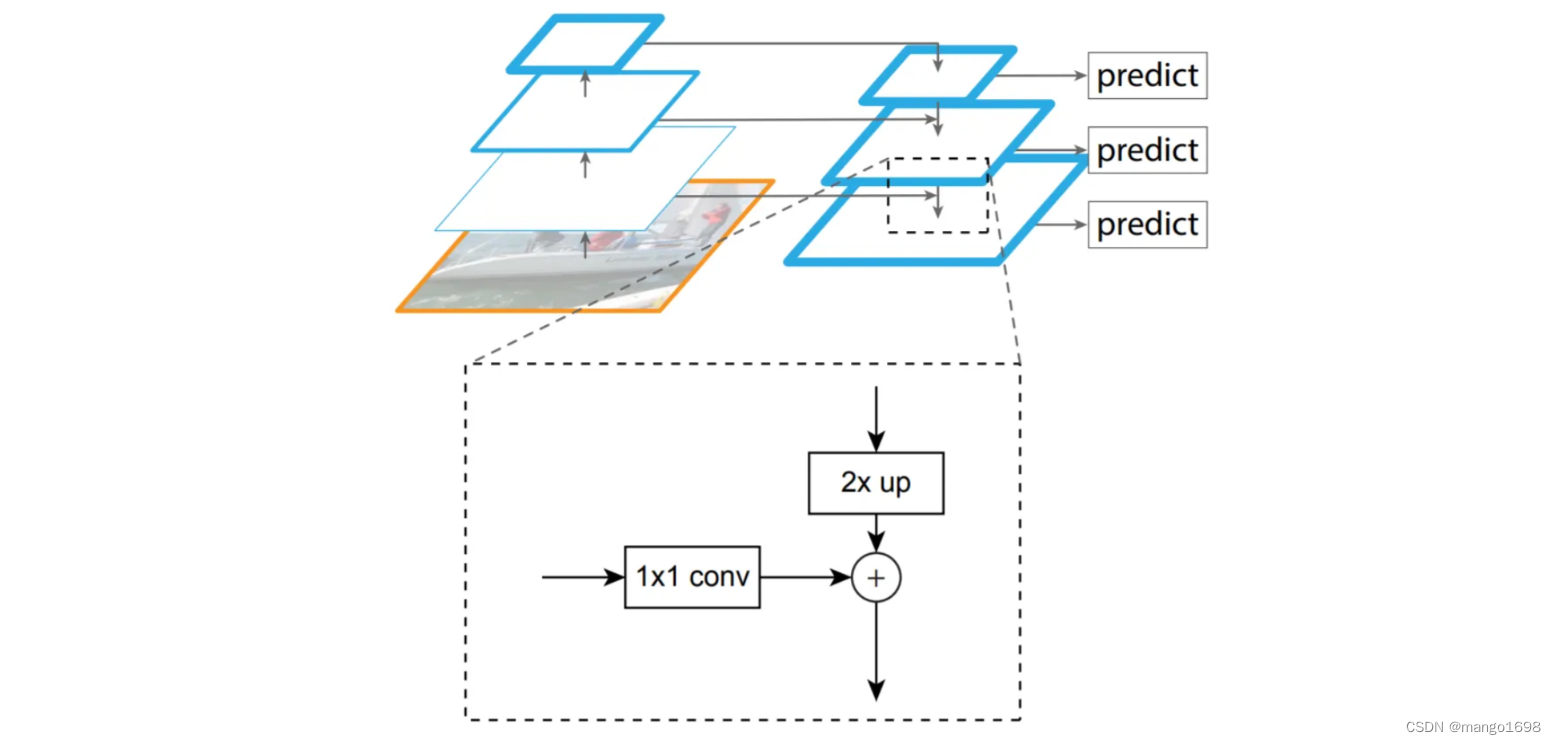
需要注意,所采用的不同特征图,是有一定的要求的,是按2的整数倍进行选取的。比如,最底层的特征图的高和宽是 28 × 28 28\times 28 28×28。那么上一层就需要采用 14 × 14 14\times14 14×14的特征图,再往上就需要采用 7 × 7 7\times7 7×7的特征图。
首先,针对backbone每个尺度的特征图,我们都会使用一个 1 × 1 1\times 1 1×1的conv进行处理,是为了调整backbone上不同特征图它的channel。(在原论文中, 1 × 1 1\times1 1×1的卷积核个数为256,即最终得到的特征图的channel都等于256。)
然后,对于上层的特征图,需要进行一个2倍的上采样(采用临近插值算法实现)。
最后,将本层经过 1 × 1 1\times1 1×1得到的特征图与上层特征图经过上采样得到的特征图进行融合。
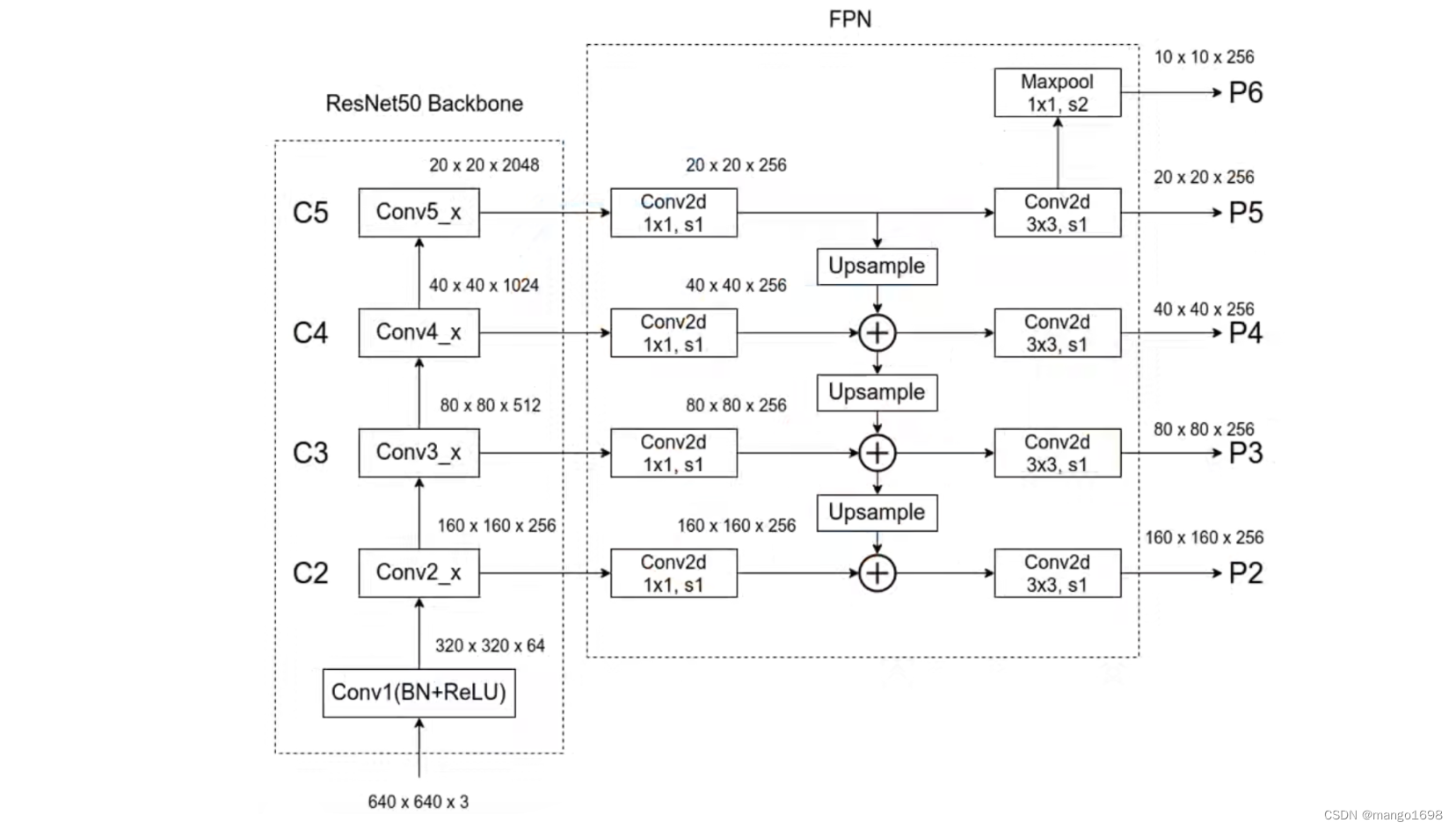
在不同尺度的特征融合后,接了一个 3 × 3 3\times3 3×3的卷积,是为了更好的融合特征。在P5的基础上进行一次下采样得到P6。(使用MaxPool,池化核大小为 1 × 1 1\times1 1×1,步长等于2)。然后会在生成的这5个特征图上进行预测。
注意:
如上图,P6只用于RPN部分,不在Faster-RCNN部分使用。
针对不同的预测特征层,RPN和Faster RCNN的权重共享。

