web自动化——Selenium 之环境搭建+元素定位+元素等待
一、环境搭建
1.1、安装selenium
pip install selenium
1.2、安装webdriver
不同浏览器driver不同,自行百度下载驱动。注:看自己浏览器版本号下载对应版本号的驱动。
谷歌:chromedriver 火狐:geckodriver ie:ieserver
这里以谷歌为例:
国内源下载地址:https://registry.npmmirror.com/binary.html?path=chromedriver/
120+版本下载地址:https://googlechromelabs.github.io/chrome-for-testing/#canary
下载对应版本的chromedrive后解压,将解压的chromedriver.exe文件放到python所在目录下。
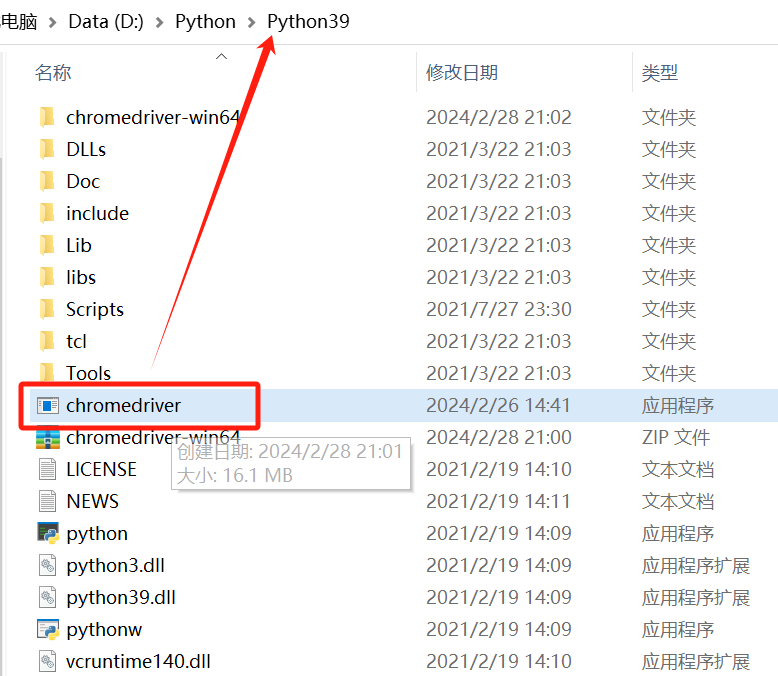
1.3、导入selenium包
from selenium import webdriver
二、selenium常用方法
1)启动驱动程序,启动浏览器,开始与浏览器之间进行会话
driver=webdriver.Chrome()
2)最大化浏览器
driver.maximize_window()
3)访问一个网页
driver.get("网站地址")
4)刷新页面
driver.refresh()
5)后退-回到上一个url
driver.back()
6)前进-回到下一个url
driver.forward()
7)关闭当前窗口
driver.close()
8)关闭浏览器、关闭驱动程序,结束与浏览器之间的会话
driver.quit()
三、元素
3.1、html页面由标签对组成
<标签名>
其它的标签对/文本内容
</标签名>
<标签名/>
每一个标签对:都有对应的作用
<script></script> 不包含任何html的内容。
标签名:元素的类型。一个标签名是一类元素
img元素:图片
a元素:链接
input元素:表单,包括文本输入框、提交,上传文件等
div标签名:分区
<html lang="en">
<head>
<title>py39期web自动化</title>
</head>
<body>
<div>
<h1>图片</h1>
<img src="https://www.baidu.com/img/540x258_2179d1243e6c5320a8dcbecd834a025d.png">
</div>
<div>
<h1 name="big title">链接</h1>
<a href="https://www.baidu.com/">百度一下,你就知道</a>
</div>
<form>
输入框:<input type="text">
按钮:<input type="button" value="提 交">
文件:<input type="file">
</form>
</body>
</html>
3.2、元素本身的特征
1)标签名
2)属性
起始标签当中,标签名之后,以key=value的形式存在
id:类似于人的身份证和指纹,独一无二。但是,它不像指纹不会变。要去判断
class: 对页面的元素进行分类
style: 行内样式
[name]: name属性,取名字
其它的属性 - 不同的元素有不同的
3)文本内容
4)元素关系。父元素/兄弟元素
四、元素定位
4.1、8大元素
1)元素的id属性:id
2)元素的class属性:class_name
3)元素的标签名:tag_name
4)元素的name属性:name
5)a元素的文本内容去定位-完全匹配:link_text
6)a元素的文本内容去定位-模糊匹配-只要包含文本就可以了:partial_link_text
7)通过xpath表达式定位 - 多属性组合/层级关系:xpath
8)通过css选择器定位:css_selector
4.2、万能定位方式
可以根据元素的多个特征组合定位! 多条件筛选!
支持通过文本内容定位
支持通过元素的层级关系定位!
4.3、xpath定位
- xpath其实就是一个path(路径),一个描述页面元素位置信息的路径,相当于元素的坐标
- xpath基于XML文档树状结构,是XML路径语言,用来查询xml文档中的节点
- 既可以用于XML,也可以用于HTML(因为XML与HTML结构类似,所以xpath都可以解析)
4.3.1、绝对定位(绝对路径)
以/开头,后面的定位当中,父/子 -- copy定位表达式
从html开始,每一个层级都会罗列出来(顺序);还有会列出在同级的兄弟姐妹当中的(位置)[1/2/3..]
/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
//div[@id="xx"]/div[1]/div[5]/div/div
不稳定 -- 太过于依赖当前的页面结构!
4.3.2、相对定位(相对路径)
1、以//开头,不管元素在哪个位置,或者不管元素处于顺序当中的哪一层。只要符合筛选条件
2、检验表达式是否正确、是否能匹配到元素的一个工具:F12-elements-选中任意一个元素-Ctrl+F
3、表达式
1)通过标签名筛选
//标签名
//a
2)通过标签名+属性筛选
//标签名[@属性="值"]
//input[@name="wd"]
3)通过标签名+文本内容筛选
//标签名[text()="值"]
//p[text()="已签到"]
4)通过contains()匹配部分属性值或者部分文本内容
//标签名[contains(@属性/text(),"要包含的值")]
//input[contains(@class,"s_btn")]
//a[contains(text(),"123")]
5)逻辑运算:and or
//标签名[@属性="值" and @属性="值" and @属性="值"]
//标签名[text()="值" and @属性="值"]
//标签名[contains(@属性/text(),"要包含的值") and @属性="值"]
//img[@class="index-logo-src" and @text()="到百度首页"]
//a[text()="视频" and @id="1"]
//a[contains(@class,"mnav") and text()="视频"]
6)从上到下的层级定位
- 方式一://表达式1//表达式2 --- 第二个//,是在第一个//表达式1找到的元素的【子孙后代】当中去定位。
//div[@id="wrapper"]//a[text()="视频"]
- 方式二://表达式1/表达式2 --- 第二个/,是在第一个//表达式1找到的元素的【儿子】当中去定位。
//div[@id="s-top-left"]/a[text()="视频"]
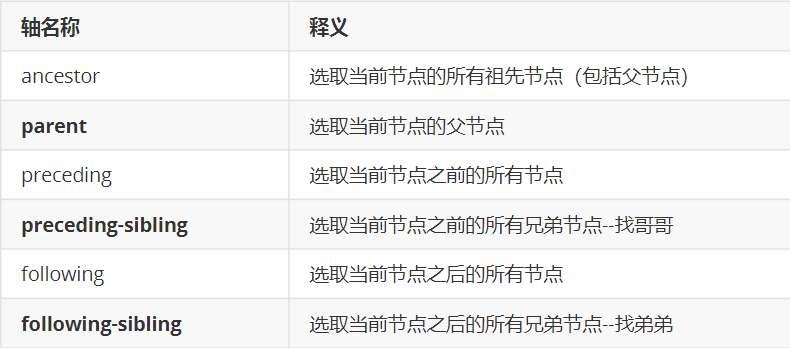
7)轴定位
方式一:通过子孙元素,找父元素、祖先元素
已知的元素/轴名称::标签名称[@属性=值]
//div[@id="u1"]/parent::div
//div[@id="u1"]/ancestor::div
方式二:通过兄弟姐妹元素,找元素
//div[@id="u1"]/following-sibling::div[@id="s_wrap"]
//div[@id="u1"]/parent::div/following-sibling::div
//span[contains(text(),"发布时间")]/parent::div/preceding-sibling::h6
4.4、css选择器定位
from selenium.webdriver.common.by import By
1、根据标签名-它的问题??不唯一,一般页面中会有很多相同标签的元素
driver.find_element(By.CSS_SELECTOR,"input")
2、根据ID
driver.find_element(By.CSS_SELECTOR,"标签名#id")
driver.find_element(By.CSS_SELECTOR,"#kw")
driver.find_element(By.CSS_SELECTOR,'input#kw')
3、根据className(样式名)
driver.find_element(By.CSS_SELECTOR,".样式名")
driver.find_element(By.CSS_SELECTOR,"标签名.样式名")
driver.find_element(By.CSS_SELECTOR, '.s_ipt')
driver.find_element(By.CLASS_NAME,'s_btn') # classname定位的时候只能支持单个样式,CSS选择器可以解决这个问题
driver.find_element(By.CSS_SELECTOR, '.s_btn') # 如果通过CSS选择器进行多样式的定位,那么每个样式的前面都需要加.
4、单属性选择定位
driver.find_element(By.CSS_SELECTOR."标签名[属性名='属性值"]")
driver.find_element(By.CSS_SELECTOR,'input[id="kw"]')
5、多属性选择定位
driver.find_element(By.CSS_SELECTOR,"标签名[属性1='属性值'][属性2='属性值’]")
driver.find_element(By.CSS_SELECTOR,'input[maxlength="255"][autocomplete="off"]')
五、WebElement对象
5.1、获取元素对象
方法一:只能找到一个元素。在html当中,从上到下去搜索,先找到的就是第一个,返回的WebElement对象。
find_element(定位策略,定位表达式)
driver.find_element(By.ID, "s-top-loginbtn")
方法二:找到多个元素,在html当中匹配到的所有元素,返回的是列表。
find_elements(定位策略,定位表达式)
driver.find_elements(By.XPATH,"//input[@id='kw']")
5.2、定位策略
通过By类定义8种元素定位策略
from selenium.webdriver.common.by import By #导入By
#获取元素
#ele=driver.find_element_by_id("kw") #写法一
#ele=driver.find_element(By.ID,"kw") #写法二
user_input=(By.ID,"kw") #写法三,拆包
ele=driver.find_element(*user_input)
5.3、元素对象常用操作方法
1)点击:click()
driver.find_element(By.ID,"su").click()
2)输入:send_keys(文本)
driver.find_element(By.XPATH,"//input[@id='kw']").send_keys("selenium webdriver")
3)清除输入框的内容:clear()
user_input = (By.XPATH,"//input[@id='kw']")
ele = driver.find_element(*user_input)
ele.clear()
4)获取元素的属性值:get_attribute()
user_input = (By.XPATH,"//input[@id='kw']")
ele = driver.find_element(*user_input)
# 获取元素的属性
print(ele.get_attribute("class"))
5)获取元素的文本内容:text
driver.find_element(By.ID, "s-top-loginbtn").text
六、元素等待
6.1、定义
当你的某一个操作,给页面带来了变化/改变,你的下一步操作要在改变之后的元素/页面上面操作,那么就需要等待元素可见
6.2、三大元素等待
6.2.1、强制等待(硬性等待)
优点:使用简单
缺点:等待时间把握不准,容易造成时间浪费或者等待时间不足
import time
time.sleep(2)
6.2.2、隐性等待
在设置的时间内(秒)不断查找元素,直到元素被找到或超时
优点:全局应用,它适用于WebDriver会话期间中所有查找的Web元素(通过findElement方法),每个会话只需要调用一次
缺点:只能等待元素存在,不能适用条件更复杂的情况,如:元素可点击、元素可见
driver.implicitly_wait(20) #最多等待20秒
6.2.3、显性等待
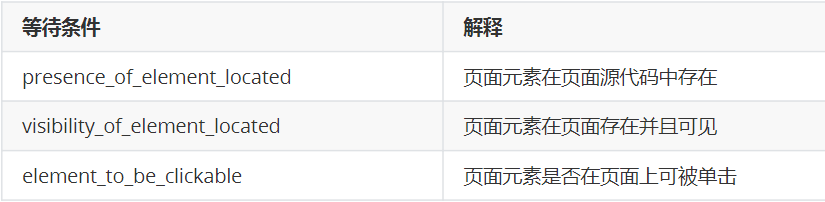
等待WebDriverWait(until()/not_until()) + 条件expected_condition
在设置的时间内(秒)根据特定的条件不断查找元素,直到找到元素为止。(如元素存在、元素可点击、元素可见等),可以实现更加精细化的控制。
优点:可以设置更加丰富的特定条件
缺点:仅对指定的元素生效,什么时候需要等,什么时候就要调用一次,代码略复杂
注意:等待条件里面的参数是元组类型的
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver=webdriver.Chrome() #打开浏览器
driver.maximize_window() #浏览器最大化
driver.get("https://www.baidu.com") #打开网页
driver.find_element(By.XPATH,'//input[@id="kw"]').send_keys("python") #找到元素并输入python
driver.find_element(By.XPATH,'//input[@id="su"]').click() #找到元素并点击
#显性等待
wait=WebDriverWait(driver,30) #最多等待30秒
fist_ele=(By.XPATH,'//*[@id="2"]//h3/a') #元素定位
wait.until(EC.visibility_of_element_located(fist_ele)) #等待元素可见
driver.find_element(By.XPATH,'//*[@id="2"]//h3/a').click() #找到元素并点击
sleep(10)
driver.close()
driver.quit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号