学习python自动化——接口测试
一、接口测试用例
1.1、测试用例设计方法
1)等价类
2)边界值
3)因果图
4)判定表
5)正交试验(筛选时)
6)流程覆盖
7)错误推测
1.2、接口测试用例怎么写
1.2.1、功能(自动化测试关注)
1、有效等价类(还要考虑前置条件、参数替换)
1)登录成功
2、无效等价类(还要考虑前置条件、参数替换)
1)手机号格式错误
2)手机号不存在
3)手机号为空
4)密码错误
5)密码为空
6)必填项字段的缺失

1.2.2、兼容性
1.2.3、性能
1.2.4、安全
1.2.5、UI/易用性
二、接口测试
2.1、怎么做好接口测试
1)了解熟悉公司的业务【核心业务】
2)了解接口相关的信息
3)了解接口协议类型
web:F12 app:抓包工具
4)核对接口文档和实际的抓包数据
5)设计接口测试用例
6)数据准备(requests去做单节口的测试):请求参数、断言数据(requests)
7)引入测试框架(unittest)
8)jenkins持续集成
2.2、自动化测试分类
1、只测单接口:测试单个接口有没有问题
定时任务,可放到单接口测试,也可放到流程测试中测试
2、流程测试:核心业务的流程
例如:用户:投资人、借款人、审核
投资人:登录、充值、随机选一个标的投资、提现
登录、实名认证、添加银行卡、设置密码、修改密码、修改提现卡
借款人:登录、实名认证、添加银行卡、提现、修改密码、设置密码、授信额度(风控决定)
登录、发起借款(不同借款期限利率不一样)
审核:登录、审核、驳回、分配业务员、背调(打标签)
定时任务,可放到单接口测试,也可放到流程测试中测试
2.3、分层设计:分类管理
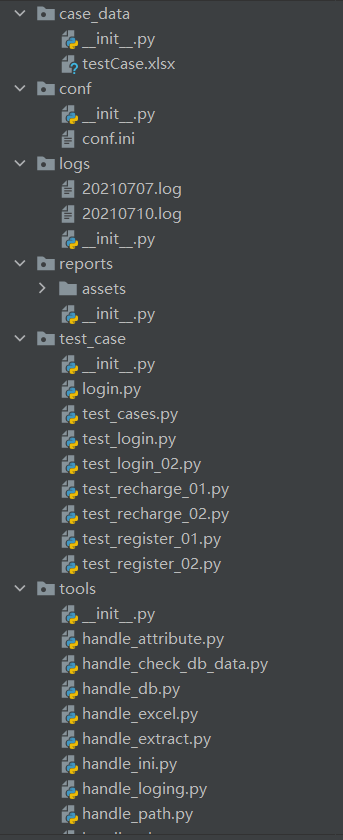
2.3.1、tools:工具
1)封装excel:读取excel表测试用例
from openpyxl import load_workbook
from my_Autotest.tools.handle_logging import my_logger
class HandleExcel:
def __init__(self,file_path,sheet_name):
my_logger.info('用例文件名称:{}'.format(file_path))
my_logger.info('表名:{}'.format(sheet_name))
self.file_name=file_path
self.work_book=load_workbook(filename=self.file_name)
self.sheet=self.work_book[sheet_name]
def __get_all_data(self):
try:
all_datas=list(self.sheet.iter_rows(values_only=True))
my_logger.info('excel读取到的全部数据:{}'.format(all_datas))
title=all_datas[0]
my_logger.info('excel读取到的表头数据:{}'.format(title))
case_datas=all_datas[1:]
my_logger.info('excel读取到的测试用例数据:{}'.format(case_datas))
return title,case_datas
except Exception as e:
my_logger.info('报错信息:{}'.format(e))
raise e
def get_case_datas_dict(self):
try:
case_list=[]
title, case_datas=self.__get_all_data()
for case in case_datas:
result=dict(zip(title,case))
case_list.append(result)
my_logger.info('测试用例拼接数据:{}'.format(case_list))
return case_list
except Exception as e:
my_logger.info('报错信息:{}'.format(e))
raise e
def write_result(self,rows,column,result=None):
self.sheet.cell(row=rows,column=column).value=result
self.__save_excel()
self.__close_excel()
def __save_excel(self):
self.work_book.save(filename=self.file_name)
def __close_excel(self):
self.work_book.close()
2)封装配置文件
from configparser import ConfigParser
from my_Autotest.tools.handle_path import conf_dir
class HandleIni(ConfigParser):
def __init__(self,filenames):
super().__init__()
self.read(filenames=filenames, encoding='utf-8')
conf=HandleIni(filenames=conf_dir)
3)封装日志文件
import logging
from logging import handlers
from my_Autotest.tools.handle_path import log_dir
def handle_log():
#创建日志收集器
py_39=logging.getLogger(name='py39')
#创建文件渠道
file=handlers.TimedRotatingFileHandler(filename=log_dir,when='D', interval=1, backupCount=5,
encoding='utf-8',)
#创建控制台渠道
#pycharm=logging.StreamHandler()
#日志格式
fmt='%(asctime)s-%(name)s-%(levelname)s-%(filename)s-%(funcName)s-[line:%(lineno)d]:%(message)s'
log_fmt=logging.Formatter(fmt=fmt)
#日志类型
py_39.setLevel(logging.DEBUG)
#渠道添加日志
#pycharm.setFormatter(log_fmt)
file.setFormatter(log_fmt)
#渠道与收集器绑定
#py_39.addHandler(pycharm)
py_39.addHandler(file)
return py_39
my_logger=handle_log()
4)封装路径处理
1、excel用例数据os路径处理
2、配置conf文件的路径
3、日志log文件的路径
4、测试报告文件的路径
import os
import time
base_dir=os.path.dirname(os.path.dirname(__file__))
#excel测试用例数据路径
excel_dir=os.path.join(base_dir,'case_data','testCase.xlsx')
#配置文件路径
conf_dir=os.path.join(base_dir,'conf','conf.ini')
#日志路径
log_file_name=time.strftime('%Y%m%d.log',time.localtime())
log_dir=os.path.join(base_dir,'logs',log_file_name)
#测试报告路径
report_file_name=time.strftime('%y%m%d_%H%M%S.html',time.localtime())
report_dir=os.path.join(base_dir,'reports',report_file_name)
5)封装requests
1、根据项目鉴权方式,无需鉴权的接口(注册、登陆、项目列表)
2、需要鉴权:传入token,拿到token就添加到请求头中,再去发起请求
3、不需要鉴权:不传token,token设置一个默认值,请求头就不做处理,再去发起请求
4、收集日志
2.3.2、test_case:unittest+ddt
1)执行测试用例
2)编写测试用例
1、创建测试类(继承unittest.TestCase,类名称建议Test开头)
2、创建测试函数(必须test开头)
2.1)发起request请求
2.2)断言
2.3.3、配置conf:host、数据库
[sheet]
name=register
#name=login
#name=recharge
[mysql]
host=api.lemonban.com
port=3306
user=future
password=123456
db=futureloan
[mobile_phone]
mobile_phone=18820992515
2.3.4、case_data:excel表(测试用例表)
2.3.5、report:测试报告——收集测试报告
2.3.6、logs:日志文件
2.3.7、main.py:框架入口
import unittest
import os
from my_Autotest.tools.handle_path import report_dir
from unittestreport import TestRunner
dir_path=os.path.dirname(__file__)
suite=unittest.defaultTestLoader.discover(start_dir=dir_path,pattern='test*.py')
runner=TestRunner(suite=suite,
filename=report_dir,
report_dir=report_dir,
title='测试报告',
tester='mango',
desc="柠檬项目测试生成的报告",
templates=1)
runner.run()
2.4、整体流程:持续集成Jenkins
三、手机号参数
3.1、Faker:生成随机数
详见:http://testingpai.com/article/1615615023407
1、安装
pip install faker
2、模块导入
from faker import Faker
3、创建实例
fk = Faker(locale='zh-CN')
#locale='zh-CN':语言环境,默认的 en_US 语言环境,支持传多个 ['ja_JP','en_US','zh-CN']
4、常用四要素方法
1)姓名
name = fk.name()
2)身份证
id_card = fk.ssn()
3)手机号
phone = fk.phone_number()
4)银行卡(信用卡)
card = fk.credit_card_number()
5、确保随机数据唯一性:fk.unique.方法名()
[fk.unique.name() for i in range(10)]
3.2、pymysql:数据库校验库(数据库检验手机号是否已注册,如果注册了,重新生成一个)
import pymysql
coon=pymysql.connect(host='api.lemonban.com', #主机名
port=3306, #端口
user='future', #用户名
password='123456', #密码
db='futureloan', #数据库名称
cursorclass=pymysql.cursors.DictCursor) #设置返回数据格式为dict,如果不设置默认返回元组
cur=coon.cursor()
sql='select * from member where id < 20;'
cur.execute(sql)
result=cur.fetchone()
result=cur.fetchall()
result=cur.fetchmany(size=3)
coon.commit()
cur.close()
coon.close()
3.2.1、安装
pip install pymysql
3.2.2、导入
import pymysql
3.2.3、步骤
1、创建数据库连接
import pymysql
coon=pymysql.connect(host='api.lemonban.com', #主机名
port=3306, #端口
user='future', #用户名
password='123456', #密码
db='futureloan', #数据库名称
cursorclass=pymysql.cursors.DictCursor) #设置返回数据格式为dict,如果不设置默认返回元组
2、创建游标(相当于工具页面上的查询窗口)
cur=coon.cursor()
3、需要执行的sql语句
sql='select * from member where id < 20;'
4、执行sql语句
cur.execute(sql)
5、返回数据
1)返回查询到的第一条数据,数据为元组
result=cur.fetchone()
2)返回查询到的所有数据,一行数据为一个元组,返回嵌套元组
result=cur.fetchall()
3)根据设置size,返回查询到的所有数据,一行数据为一个元组,返回嵌套元组
result=cur.fetchmany(size=3)
6、数据库提交,更新了数据库就必须要提交
coon.commit()
7、关闭游标
cur.close()
8、关闭数据库连接
coon.close()
3.3、使用生成的手机号,替换掉请求参数的手机号
3.3.1、请求参数替换
1.上一个接口或者历史接口返回值
2.数据库查询到数据
3.随机生成
3.3.2、发起请求
3.3.3、获取token,依赖参数
3.3.4、响应参数替换
四、参数替换思路
4.1、参数替换场景
1)从数据库获取数据替换
2)从配置文件获取数据替换
3)原来类属性中存在的
4)脚本替换随机生成的手机号
5)写死
4.2、参数替换实现思路
4.2.1、excel用例增加参数替换规则字段:replace_request_data
1、从数据库读取:{"mobile_phone":["db","select mobile_phone from member where type=0 order by id desc limit 1]}
2、从配置文件读取:{"mobile_phone":["conf"}
3、已经在全局变量存在的(类属性):{"mobile_phone":["attribute"]}
4、脚本替换随机生成的手机号:{"mobile_phone":["script"]}
5、replace_request_data 字段为空,表示写死,不需要参数替换
4.2.2、创建一个类,用来存储全局变量,将从数据库、配置文件、脚本中读取出来的值设置成全局变量,用来做参数替换使用
五、断言思路
6.1、响应结果断言
{"code": 0, "msg": "OK"}
6.1.1、从响应中获取实际结果
actual_data = {'code': response['code'], 'msg': response['msg']}
6.1.2、预期结果(expected_data)与实际结果(actual_data )进行比对(assert)
6.2、数据库断言
6.2.1、接口请求之后,做数据库断言
在excel中新增字段:check_db
{"actual_data":["db","select mobile_phone from member where mobile_phone = '#mobile_phone#'"],"expected_data":["mobile_phone"]}
1.获取到check_db这个字段的数据,通过actual_data获取到sql
2.替换掉sql里面的手机号
3.执行sql,获取sql执行结果
4.用这个sql执行结果替换掉actual_data结果的value
5.比对actual_data和expected_data的val
6.2.2、接口请求前和请求后数据库断言
1、存储接口请求前数据库数据
2、sql参数替换
3、多次数据库查询数据的运算
新增excel字段:check_db_many
{"first": ["db", "select leave_amount from member where mobile_phone='#mobile_phone#'"],
"second": ["db", "select leave_amount from member where mobile_phone='18820992515'"],
"expected_data": "first+second+100",
"actual_data": ["db", "select leave_amount from member where mobile_phone='#mobile_phone#'"]}
1.遍历check_db_many字段的key,将key不等于expected_data和actual_data的字段key和val单独拿出来,
新建一个字典,这个新字典即接口请求之前需要执行sql保留的数据
2.将新的字典进行参数替换,替换value
3.用替换完成后的新字典更新原来的check_db_many字典
{"first": 100
"second": 200,
"expected_data": "first+second+100",
"actual_data": ["db", "select leave_amount from member where mobile_phone='#mobile_phone#'"]}
4.获取expected_data字段,并解析期望结果中的计算规则进行计算,替换掉value
5.获取actual_data字段,根据标记位判断数据获取来源,获取数据(执行sql或直接获取值)并替换掉value
6.比对actual_data和expected_data的val
六、token提取思路(全局变量提取)
在excel中新增字段:extract_data
输入字段提取规则(jsonpath表达式):{"token":"$..token","member_id":"$..id"}
通过jsonpath提取出token或其他字段的值,将token值或其他字段的值设置成全局变量,然后将token放到需要的请求头中。
import ast
from jsonpath import jsonpath
from handle_attribute import HandleAttribute
from handle_loging import my_logger
class HandleExtract:
def __set_attribute(self,key,val):
setattr(HandleAttribute,key,val)
my_logger.info(msg="将{}={}设置为HandleAttribute类属性成功".format(key, val))
def handle_extract(self,response,extract_data):
"""
:param response:
:type=dict
响应结果
:param extract_data:
:type=dict
{"token":"$..token","member_id":"$..member_id"}
提取参数的key和提取规则
:return:无
"""
my_logger.info(msg="==============开始提取全局变量==============")
my_logger.info(msg="全局变量来源之接口响应结果:{},类型为:{}".format(response, type(response)))
my_logger.info(msg="全局变量提取规则:{},类型为:{}".format(extract_data, type(extract_data)))
if extract_data:
if isinstance(extract_data,dict):
extract_data=extract_data
else:
extract_data=ast.literal_eval(extract_data)
for key,value in extract_data.items():
#获取提取的结果
extract_result=jsonpath(response,value)
my_logger.info(msg="全局变量提取结果:{},类型为:{}".format(extract_result, type(extract_result)))
#设置成类属性
self.__set_attribute(key=key,val=extract_result[0])
else:
my_logger.info(msg="全局变量提取规则为空无需提取")
七、前置条件
在excel中新增字段:setup_sql
["update table set status=2 where id >100","update table set status=3 where id >100"]
1.获取setup_sql字段,遍历sql列表
2.执行sql
注:支持多个sql,只执行sql,不做参数替换,不设全局变量
def setup_sql(self,sql_list): #前置sql
"""
执行前置sql语句
:param sql_list:
:type=list
需要执行的sql语句
:return:无
"""
if sql_list:
if isinstance(sql_list,list):
sql_list=sql_list
else:
sql_list=ast.literal_eval(sql_list)
for sql in sql_list:
mysql.get_db_all_data(sql=sql)
else:
my_logger.info(msg="sql_list为空,不需要执行前置sql语句")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号