mysql-视图、触发器、事务、存储过程、流程控制
目录
- 视图
- 触发器
- 事务
- 存储过程
- 流程控制
一、视图
视图是由查询结果构成的一张虚拟表,和真实的表一样,带有名称的列和行数据
强调:视图是永久存储的,但是视图存储的不是数据,只是一条sql语句
视图的特点:
- 视图的列可以来自不同的表,是表的抽象和逻辑意义上建立的新关系。
- 视图是由基本表(实表)产生的表(虚表)。
- 视图的建立和删除不影响基本表。
- 对视图内容的更新(添加、删除和修改)直接影响基本表。
- 当视图来自多个基本表时,不允许添加和删除数据。
优点:
- 可以简化查询(多表查询转换为直接通过视图查询)
- 可以进行权限控制(把表的权限封闭,开发对应的视图权限)
(一)、创建视图
create view 视图名称 as sql 查询语句 例子:CREATE view test_view as SELECT * from test;
(二)、查询视图
select * from 视图名 [where 条件]
(三)、修改视图
alter view 视图名称 AS SQL语句; 例子:ALTER view test_view as SELECT * from test_view WHERE salary>10000
(四)、删除视图
drop view 视图名称; 例子:drop view test_view
二、触发器
触发器可以监视用户对表的增、删、改操作,并触发某种操作(没有查),自动执行,无法直接调用。
创建触发器语法的四要素:
1.监视地点(table)
2.监视事件(insert/update/delete)
3.触发时间(before/after)
4.触发事件(insert/update/delete)
(一)、创建触发器


# 插入前 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW BEGIN ... END # 插入后 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW BEGIN ... END # 删除前 CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW BEGIN ... END # 删除后 CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW BEGIN ... END # 更新前 CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW BEGIN ... END # 更新后 CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW BEGIN ... END
#准备表 CREATE TABLE cmd ( id INT PRIMARY KEY auto_increment, USER CHAR (32), priv CHAR (10), cmd CHAR (64), sub_time datetime, #提交时间 success enum ('yes', 'no') #0代表执行失败 ); CREATE TABLE errlog ( id INT PRIMARY KEY auto_increment, err_cmd CHAR (64), err_time datetime ); #创建触发器 delimiter // CREATE TRIGGER tri_after_insert_cmd AFTER INSERT ON cmd FOR EACH ROW BEGIN IF NEW.success = 'no' THEN #等值判断只有一个等号 INSERT INTO errlog(err_cmd, err_time) VALUES(NEW.cmd, NEW.sub_time) ; #必须加分号 END IF ; #必须加分号 END// delimiter ; #往表cmd中插入记录,触发触发器,根据IF的条件决定是否插入错误日志 INSERT INTO cmd ( USER, priv, cmd, sub_time, success ) VALUES ('A','0755','ls -l /etc',NOW(),'yes'), ('A','0755','cat /etc/passwd',NOW(),'no'), ('A','0755','useradd xxx',NOW(),'no'), ('A','0755','ps aux',NOW(),'yes'); #查询错误日志,发现有两条 mysql> select * from errlog; +----+-----------------+---------------------+ | id | err_cmd | err_time | +----+-----------------+---------------------+ | 1 | cat /etc/passwd | 2018-09-18 20:18:48 | | 2 | useradd xxx | 2018-09-18 20:18:48 | +----+-----------------+---------------------+ 2 rows in set (0.00 sec)
强调:NEW表示即将插入的数据行,OLD表示即将删除的数据行
(二)、查看触发器
show triggers
(三)、删除触发器
drop trigger 触发器的名称
三、事务
事务用于将某些操作的多个SQL作为原子性操作,意思就是,事务是一组sql语句集合。
一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性。在事务内的语句, 要么全部执行成功, 要么全部执行失败。
(一)、事务的特性
事务具有以下四个特性(ACID)
1.原子性:事务是一个整体,不可分割,包含在其中的sql操作要么全部成功,要么全部失败回滚,不可能只执行其中一部分操作。
2.一致性:当事务执行后 所有的数据都是完整的(外键约束 非空约束)。
3.持久性:一旦事务提交,数据永久保存在数据库中
4.隔离性:事务之间相互隔离,一个事务的执行不影响其他事务的执行
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
(二)、事务的隔离级别
1.READ UNCOMMITED(未提交读):所有事务都可以看到其他未提交事务的执行结果。很少用于实际应用,因为它的性能不比其他级别好多少
2.READ COMMITED(提交读):大部分数据库默认级别,不包括mysql。一个事务从开始到提交之前, 所做的任何修改对其他事务都是不可见的。
3.REPEATABLE READ(可重复读):mysql默认级别,解决了脏读的问题. 该级别保证了在同一个事务中多次读取同样记录的结果时一致的. 无法解决幻读问题
4.SERIALIZABLE(可串行化):是最高的隔离级别,强制事务排序,使之不可能相互冲突,从而解决幻读问题
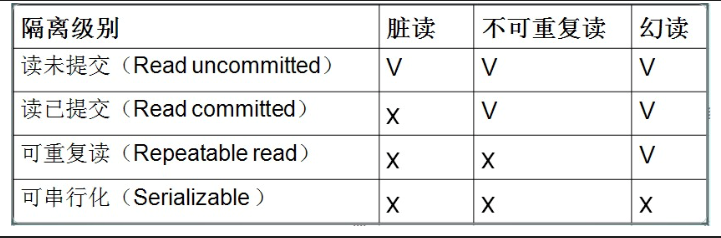
脏读: 一个事物 读到了 另一个事务未提交的数据 查询 之前要保证 所有的更新都已经完成。
不可重复读:在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读:指的是当某个事务在读取某个范围内的记录时, 另外一个事务又在该范围内插入了新的记录, 当之前的事务再次读取该范围的记录时, 会产生幻行(Phantom Row).
(三)、事务操作
start transaction; 开启一个事物 commit 提交事物 rollback 回滚事务
注:mysql默认开启自动提交事务,pymysql默认是不自动提交,需手动commit
四、存储过程
存储过程包含了一系列可执行的sql语句的集合,类似于函数(方法)。
使用存储过程的优点:
#1. 用于替代程序写的SQL语句,实现程序与sql解耦 #2. 基于网络传输,传别名的数据量小,而直接传sql数据量大
缺点:不方便扩展
(一)、使用存储过程
创建语法: create procedure 过程的名称 ({in,out,inout} 数据类型 参数名称) begin 具体的sql代码 end 参数前面需要指定参数的作用
in 表示该参数用于传入数据 out 用于返回数据 inout 即可传入 也可返回 参数类型是 mysql中的数据类型
调用语法:
call 存储过程()
案例:创建一个存储过程 作用是将两个整数相加 create procedure add_p (in a int,in b int) begin select a + b; end // 调用 call add_p(1,2) 案例:创建一个存储过程 作用是将两个整数相加 将结果保存在变量中 定义一个变量 set @su = 100; create procedure add_p2 (in a int,in b int,out su int) begin set su = a + b; end // 定义变量 set @su = 100; 调用过程 call add_p2(10,20,@su); 注意 在存储过程中 需要使用分号来结束一行 但是分号有特殊含义 得将原始的结束符 修改为其他符号 delimiter // 结束符更换为// delimiter;
在存储过程中 需要使用分号来结束一行 但是分号有特殊含义 得将原始的结束符 修改为其他符号 delimiter // 结束符更换为// delimiter;
create procedure show_p (in a int) begin if a = 1 then select "壹"; elseif a = 2 then select "贰"; else select "other"; end if; end //
(二)、删除存储过程
drop procedure proc_name;
五、流程控制
(一)、条件语句
delimiter // CREATE PROCEDURE proc_if () BEGIN declare i int default 0; if i = 1 THEN SELECT 1; ELSEIF i = 2 THEN SELECT 2; ELSE SELECT 7; END IF; END // delimiter ;
(二)、循环语句
delimiter // CREATE PROCEDURE proc_while () BEGIN DECLARE num INT ; SET num = 0 ; WHILE num < 10 DO SELECT num ; SET num = num + 1 ; END WHILE ; END // delimiter ;
delimiter // CREATE PROCEDURE proc_repeat () BEGIN DECLARE i INT ; SET i = 0 ; repeat select i; set i = i + 1; until i >= 5 end repeat; END // delimiter ;
BEGIN declare i int default 0; loop_label: loop set i=i+1; if i<8 then iterate loop_label; end if; if i>=10 then leave loop_label; end if; select i; end loop loop_label; END

 浙公网安备 33010602011771号
浙公网安备 33010602011771号