
CKA认证
一、报名
https://training.linuxfoundation.cn/
考试地址:https://trainingportal.linuxfoundation.org/learn/course/certified-kubernetes-administrator-china-exam-cka-cn/exam/exam
二、环境搭建
https://www.cnblogs.com/mancheng/articles/18010041
三、知识点复习
3.1、容器的监控检查
Liveness:容器的存活性探测,pod是否为Running,不是Running状态则杀死容器,依据策略重启;Pod是否创建成功;
Redness:容器就绪性探测,判断Condition是否为Ready;应用容器是否创建成功;
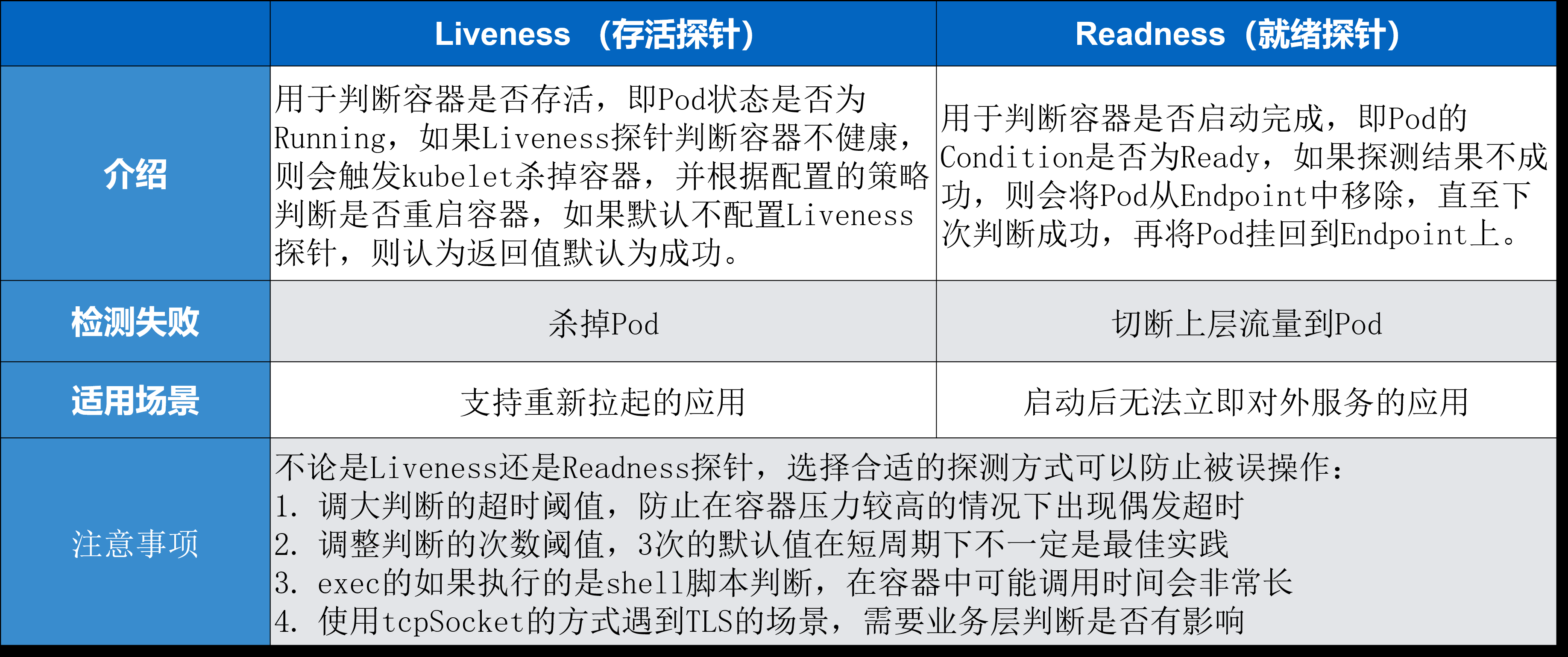
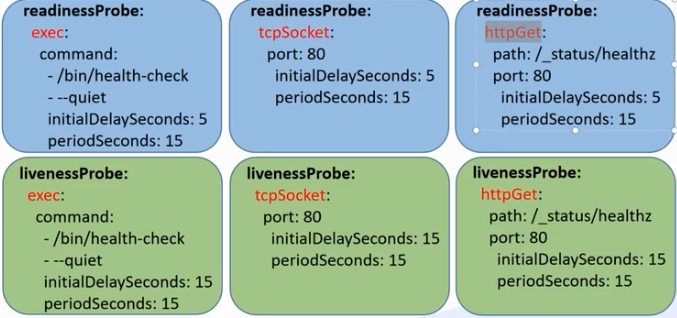
检测方式:
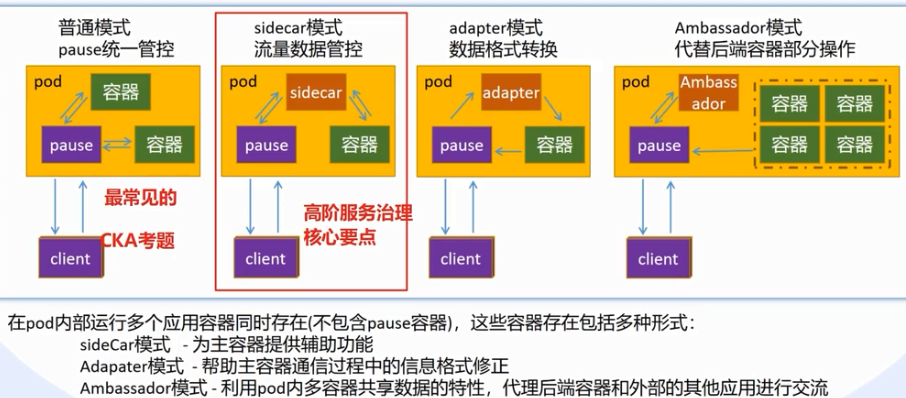
3.2、多容器实践
pause容器:
在每个Pod中都运行着一个特殊的被称为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此他们之间的通信和数据交换更为高校,在设计时候我们可以充分利用这一特性将一组密切相关的服务进程放入同一个Pod中。
Puase容器是pod容器的父容器,它主要负责僵尸进程的回收管理,同时可以通过puase容器可以是一个pod里边的不同容器共享存储、网络、PID、IPC等,容器之间可以通过localhost:port可以互相访问,可以使用volume等实现数据共享。根据Docker的构造Pod可以被建模为一组具有共享命令空间、卷、IP地址和Port端口的容器。
在Kubernetes(简称K8S)中,pause容器是每个Pod中的一个基础且至关重要的组成部分。它的主要作用和功能包括:
-
创建共享网络命名空间:
- pause容器首先启动,并创建一个网络命名空间,所有该Pod内的其他业务容器都加入到这个共享的网络命名空间中。这意味着这些容器可以相互通信就如同它们在同一台主机上的进程一样,共享相同的网络栈和IP地址。
-
PID命名空间共享:
- Pod中的不同容器通过共享pause容器的PID命名空间,使得容器间能够看到彼此的进程ID。
-
IPC命名空间共享:
- 在同一Pod内的容器也可以通过pause容器共享IPC命名空间,从而允许它们使用SystemV IPC或POSIX消息队列进行跨容器通信。
-
资源隔离与管理:
- 虽然pause容器本身通常是一个非常小且不执行任何实际业务逻辑的镜像(仅包含一个无限循环或暂停进程),但它作为Pod内所有容器的父进程,有助于系统管理和跟踪容器生命周期。
-
存储卷挂载点共享:
- pause容器也是负责挂载Pod级别Volume的实体,这样同一个Pod中的多个容器就可以访问相同的持久化存储资源。
3.3、标签
[root@master ~]# kubectl label pod mynginx label1=value pod/mynginx labeled [root@master ~]# kubectl get pod --show-labels NAME READY STATUS RESTARTS AGE LABELS mynginx 1/1 Running 1 (5m7s ago) 24h label1=value,run=mynginx
删除标签
[root@master ~]# kubectl label pod mynginx label1-
pod/mynginx unlabeled
3.4、控制器
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.14.2 ports: - containerPort: 80
更新镜像
[root@master ~]# kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 deployment.apps/nginx-deployment image updated
3.5、扩缩容
[root@master ~]# kubectl scale deployment nginx-deployment --replicas=5 deployment.apps/nginx-deployment scaled
3.6、节点调度nodeAffinity
apiVersion: v1 kind: Pod metadata: name: with-node-affinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - antarctica-east1 - antarctica-west1 preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: another-node-label-key operator: In values: - another-node-label-value containers: - name: with-node-affinity image: registry.k8s.io/pause:2.0
节点亲和性权重:你可以为 preferredDuringSchedulingIgnoredDuringExecution 亲和性类型的每个实例设置 weight 字段,其取值范围是 1 到 100。 当调度器找到能够满足 Pod 的其他调度请求的节点时,调度器会遍历节点满足的所有的偏好性规则, 并将对应表达式的 weight 值加和。
apiVersion: v1 kind: Pod metadata: name: with-affinity-anti-affinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: label-1 operator: In values: - key-1 - weight: 50 preference: matchExpressions: - key: label-2 operator: In values: - key-2 containers: - name: with-node-affinity image: registry.k8s.io/pause:2.0
3.7、Pod亲和性调度
Pod 间亲和性与反亲和性使你可以基于已经在节点上运行的 Pod 的标签来约束 Pod 可以调度到的节点,而不是基于节点上的标签。
podAntiAffinity:反亲和性调度
podAffinity:亲和性调度
apiVersion: apps/v1 kind: Deployment metadata: name: redis-cache spec: selector: matchLabels: app: store replicas: 3 template: metadata: labels: app: store spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - store topologyKey: "kubernetes.io/hostname" containers: - name: redis-server image: redis:3.2-alpine
3.8、污点和容忍度调度
污点(Taint) :它使节点能够排斥一类特定的 Pod;
容忍度Toleration:是应用于 Pod 上的。容忍度允许调度器调度带有对应污点的 Pod。
动作:
NoExecute,这会影响已在节点上运行的 Pod,具体影响如下:
- 如果 Pod 不能容忍这类污点,会马上被驱逐。
- 如果 Pod 能够容忍这类污点,但是在容忍度定义中没有指定
tolerationSeconds, 则 Pod 还会一直在这个节点上运行。 - 如果 Pod 能够容忍这类污点,而且指定了
tolerationSeconds, 则 Pod 还能在这个节点上继续运行这个指定的时间长度。 这段时间过去后,节点生命周期控制器从节点驱除这些 Pod。
NoSchedule,除非具有匹配的容忍度规约,否则新的 Pod 不会被调度到带有污点的节点上。 当前正在节点上运行的 Pod 不会被驱逐。
PreferNoSchedulePreferNoSchedule 是“偏好”或“软性”的 NoSchedule。 控制平面将尝试避免将不能容忍污点的 Pod 调度到的节点上,但不能保证完全避免。
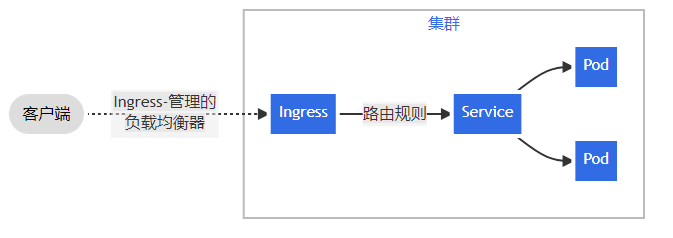
3.9、流量调度
Ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP;
Ingress 提供从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源所定义的规则来控制。
四、考题实验
4.1、etcd备份
查看官方文档 https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/configure-upgrade-etcd/
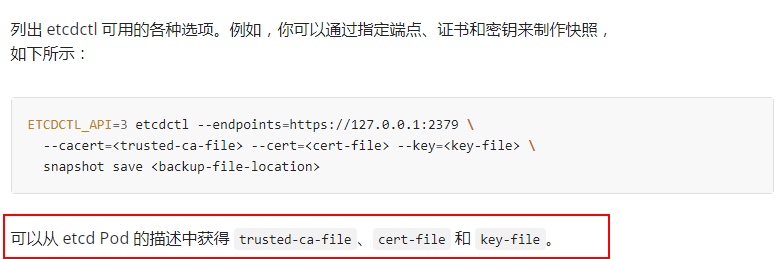
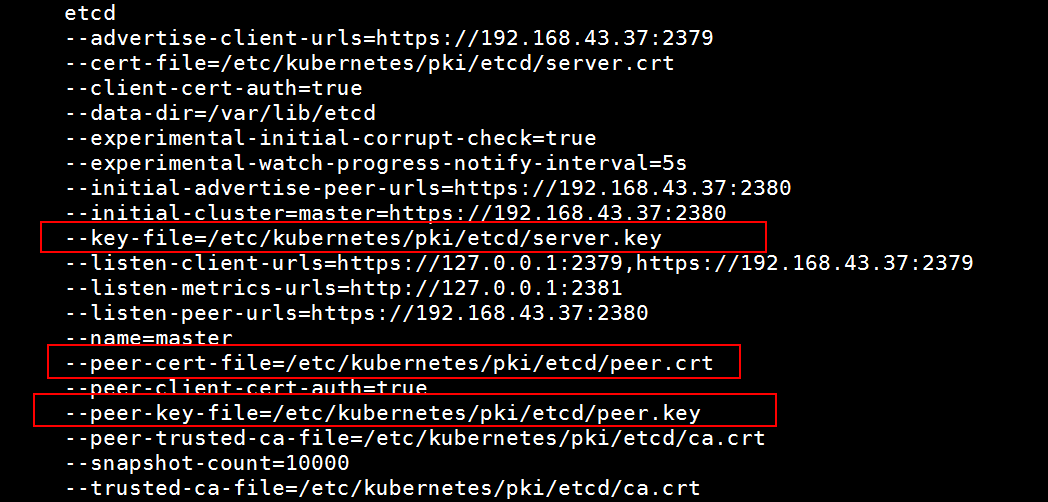
先找到这三个证书:
[root@master manifests]# kubectl describe pod etcd-master -n kube-system
然后执行备份命令
[root@master manifests]# ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key snapshot save etcd-snapshout.db
提示备份成功
![]()
4.2、取消节点污点
[root@master01 ~]# kubectl taint nodes work02 offline=testtaint:NoSchedule-
node/work02 untainted
4.3、清空节点
[root@master01 ~]# kubectl drain work02 --ignore-daemonsets node/work02 cordoned WARNING: ignoring DaemonSet-managed Pods: kube-system/calico-node-8cqp4, kube-system/kube-proxy-kz9h4, kube-system/node-exporter-nsw56 evicting pod default/nginx-deployment-6b474476c4-8mvhk evicting pod default/nginx-deployment-6b474476c4-kr86c pod/nginx-deployment-6b474476c4-8mvhk evicted pod/nginx-deployment-6b474476c4-kr86c evicted node/work02 evicted
恢复调度
[root@master01 ~]# kubectl uncordon work02
node/work02 uncordoned
4.4、RABC鉴权
创建clusterrole
kubectl create clusterrole deployment-clusterrole --verb=create --resource=deployment,statefulset,daemonset
创建serviceount
kubectl create serviceaccount cicd-token -n app-team1
创建rolebinding绑定servicecount
kubectl create rolebinding cicd-boding --clusterrole=deployment-clusterrole --serviceaccount=app-team1:cicd-token --namespace=app-team1
4.5、设置节点不可用
执行报错
[root@master01 ~]# kubectl drain work01 --ignore-daemonsets node/work01 cordoned error: unable to drain node "work01", aborting command... There are pending nodes to be drained: work01 error: cannot delete Pods with local storage (use --delete-local-data to override): kube-system/grafana-core-768b6bf79c-b2tzv, kube-system/prometheus-7486bf7f4b-j2tmr
按照提示加参数
[root@master01 ~]# kubectl drain work01 --delete-local-data --ignore-daemonsets node/work01 already cordoned WARNING: ignoring DaemonSet-managed Pods: kube-system/calico-node-b5dwh, kube-system/kube-proxy-x6vqb, kube-system/node-exporter-x6qx8 evicting pod default/nginx-deployment-6b474476c4-dr55z evicting pod ingress-nginx/nginx-ingress-controller-766fb9f77-wlncg evicting pod kube-system/grafana-core-768b6bf79c-b2tzv evicting pod kube-system/prometheus-7486bf7f4b-j2tmr pod/nginx-deployment-6b474476c4-dr55z evicted pod/grafana-core-768b6bf79c-b2tzv evicted pod/prometheus-7486bf7f4b-j2tmr evicted pod/nginx-ingress-controller-766fb9f77-wlncg evicted node/work01 evicted
4.6、节点升级
参考官方文档 https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
首先清空节点
[root@master01 ~]# kubectl drain master01 --ignore-daemonsets --delete-local-data node/master01 already cordoned WARNING: ignoring DaemonSet-managed Pods: kube-system/calico-node-52rhs, kube-system/kube-proxy-gns5n evicting pod kube-system/calico-kube-controllers-65f8bc95db-tlwqv evicting pod kube-system/coredns-7ff77c879f-pfhzm evicting pod kube-system/coredns-7ff77c879f-b9nhr evicting pod kubernetes-dashboard/dashboard-metrics-scraper-6b4884c9d5-24d8k evicting pod kubernetes-dashboard/kubernetes-dashboard-7f99b75bf4-zqrlr pod/calico-kube-controllers-65f8bc95db-tlwqv evicted pod/kubernetes-dashboard-7f99b75bf4-zqrlr evicted pod/dashboard-metrics-scraper-6b4884c9d5-24d8k evicted pod/coredns-7ff77c879f-b9nhr evicted pod/coredns-7ff77c879f-pfhzm evicted node/master01 evicted
下载镜像
[root@master01 ~]# yum install -y kubeadm-1.18.1-0 --disableexcludes=kubernetes
验证升级计划
[root@master01 ~]# sudo kubeadm upgrade plan [upgrade/config] Making sure the configuration is correct: [upgrade/config] Reading configuration from the cluster... [upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [preflight] Running pre-flight checks. [upgrade] Running cluster health checks [upgrade] Fetching available versions to upgrade to [upgrade/versions] Cluster version: v1.18.0 [upgrade/versions] kubeadm version: v1.18.1 I0521 08:59:49.859097 42708 version.go:252] remote version is much newer: v1.30.1; falling back to: stable-1.18 [upgrade/versions] Latest stable version: v1.18.20 [upgrade/versions] Latest stable version: v1.18.20 [upgrade/versions] Latest version in the v1.18 series: v1.18.20 [upgrade/versions] Latest version in the v1.18 series: v1.18.20 Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply': COMPONENT CURRENT AVAILABLE Kubelet 3 x v1.18.0 v1.18.20 Upgrade to the latest version in the v1.18 series: COMPONENT CURRENT AVAILABLE API Server v1.18.0 v1.18.20 Controller Manager v1.18.0 v1.18.20 Scheduler v1.18.0 v1.18.20 Kube Proxy v1.18.0 v1.18.20 CoreDNS 1.6.7 1.6.7 Etcd 3.4.3 3.4.3-0 You can now apply the upgrade by executing the following command: kubeadm upgrade apply v1.18.20 Note: Before you can perform this upgrade, you have to update kubeadm to v1.18.20. _____________________________________________________________________
升级
[root@master01 ~]# sudo kubeadm upgrade apply v1.18.1 --etcd-upgrade=false [upgrade/config] Making sure the configuration is correct: [upgrade/config] Reading configuration from the cluster... [upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [preflight] Running pre-flight checks. [upgrade] Running cluster health checks [upgrade/version] You have chosen to change the cluster version to "v1.18.1" [upgrade/versions] Cluster version: v1.18.0 [upgrade/versions] kubeadm version: v1.18.1 [upgrade/confirm] Are you sure you want to proceed with the upgrade? [y/N]: y [upgrade/prepull] Will prepull images for components [kube-apiserver kube-controller-manager kube-scheduler] [upgrade/prepull] Prepulling image for component kube-scheduler. [upgrade/prepull] Prepulling image for component kube-apiserver. [upgrade/prepull] Prepulling image for component kube-controller-manager. [apiclient] Found 0 Pods for label selector k8s-app=upgrade-prepull-kube-controller-manager [apiclient] Found 0 Pods for label selector k8s-app=upgrade-prepull-kube-scheduler [apiclient] Found 0 Pods for label selector k8s-app=upgrade-prepull-kube-apiserver [apiclient] Found 1 Pods for label selector k8s-app=upgrade-prepull-kube-controller-manager [apiclient] Found 1 Pods for label selector k8s-app=upgrade-prepull-kube-scheduler [apiclient] Found 1 Pods for label selector k8s-app=upgrade-prepull-kube-apiserver [upgrade/prepull] Prepulled image for component kube-apiserver. [upgrade/prepull] Prepulled image for component kube-scheduler. [upgrade/prepull] Prepulled image for component kube-controller-manager. [upgrade/prepull] Successfully prepulled the images for all the control plane components [upgrade/apply] Upgrading your Static Pod-hosted control plane to version "v1.18.1"... Static pod: kube-apiserver-master01 hash: 73577cfc8d375fc352d9822868bd483d Static pod: kube-controller-manager-master01 hash: c4d2dd4abfffdee4d424ce839b0de402 Static pod: kube-scheduler-master01 hash: ca2aa1b3224c37fa1791ef6c7d883bbe [upgrade/staticpods] Writing new Static Pod manifests to "/etc/kubernetes/tmp/kubeadm-upgraded-manifests422211952" W0521 09:04:23.620360 45029 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC" [upgrade/staticpods] Preparing for "kube-apiserver" upgrade [upgrade/staticpods] Renewing apiserver certificate [upgrade/staticpods] Renewing apiserver-kubelet-client certificate [upgrade/staticpods] Renewing front-proxy-client certificate [upgrade/staticpods] Renewing apiserver-etcd-client certificate [upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-apiserver.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2024-05-21-09-04-23/kube-apiserver.yaml" [upgrade/staticpods] Waiting for the kubelet to restart the component [upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s) Static pod: kube-apiserver-master01 hash: 73577cfc8d375fc352d9822868bd483d E0521 09:04:26.212373 45029 request.go:975] Unexpected error when reading response body: unexpected EOF Static pod: kube-apiserver-master01 hash: 763d395eb053a437e411b788b6c43f2c [apiclient] Found 1 Pods for label selector component=kube-apiserver [upgrade/staticpods] Component "kube-apiserver" upgraded successfully! [upgrade/staticpods] Preparing for "kube-controller-manager" upgrade [upgrade/staticpods] Renewing controller-manager.conf certificate [upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-controller-manager.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2024-05-21-09-04-23/kube-controller-manager.yaml" [upgrade/staticpods] Waiting for the kubelet to restart the component [upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s) Static pod: kube-controller-manager-master01 hash: c4d2dd4abfffdee4d424ce839b0de402 Static pod: kube-controller-manager-master01 hash: 7f41863dcd18ecbe4486e9011b98eb40 [apiclient] Found 1 Pods for label selector component=kube-controller-manager [upgrade/staticpods] Component "kube-controller-manager" upgraded successfully! [upgrade/staticpods] Preparing for "kube-scheduler" upgrade [upgrade/staticpods] Renewing scheduler.conf certificate [upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-scheduler.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2024-05-21-09-04-23/kube-scheduler.yaml" [upgrade/staticpods] Waiting for the kubelet to restart the component [upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s) Static pod: kube-scheduler-master01 hash: ca2aa1b3224c37fa1791ef6c7d883bbe Static pod: kube-scheduler-master01 hash: 2c04fc5e4761bd2ada4d5c31bd4317ad [apiclient] Found 1 Pods for label selector component=kube-scheduler [upgrade/staticpods] Component "kube-scheduler" upgraded successfully! [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.18" in namespace kube-system with the configuration for the kubelets in the cluster [kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.18" ConfigMap in the kube-system namespace [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy [upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.18.1". Enjoy! [upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.
升级kubelet和kubectl
[root@master01 ~]# sudo yum install -y kubelet-1.18.1-0 kubectl-1.18.1-0 --disableexcludes=kubernetes Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com Resolving Dependencies --> Running transaction check ---> Package kubectl.x86_64 0:1.18.0-0 will be updated ---> Package kubectl.x86_64 0:1.18.1-0 will be an update ---> Package kubelet.x86_64 0:1.18.0-0 will be updated ---> Package kubelet.x86_64 0:1.18.1-0 will be an update --> Finished Dependency Resolution Dependencies Resolved ========================================================================================================================= Package Arch Version Repository Size ========================================================================================================================= Updating: kubectl x86_64 1.18.1-0 kubernetes 9.5 M kubelet x86_64 1.18.1-0 kubernetes 21 M Transaction Summary ========================================================================================================================= Upgrade 2 Packages Total download size: 30 M Downloading packages: Delta RPMs disabled because /usr/bin/applydeltarpm not installed. (1/2): 9b65a188779e61866501eb4e8a07f38494d40af1454ba9232f98fd4ced4ba935-kubectl-1.18.1-0.x86_64.r | 9.5 MB 00:00:33 (2/2): 39b64bb11c6c123dd502af7d970cee95606dbf7fd62905de0412bdac5e875843-kubelet-1.18.1-0.x86_64.r | 21 MB 00:00:46 ------------------------------------------------------------------------------------------------------------------------- Total 670 kB/s | 30 MB 00:00:46 Running transaction check Running transaction test Transaction test succeeded Running transaction Updating : kubectl-1.18.1-0.x86_64 1/4 Updating : kubelet-1.18.1-0.x86_64 2/4 Cleanup : kubectl-1.18.0-0.x86_64 3/4 Cleanup : kubelet-1.18.0-0.x86_64 4/4 Verifying : kubelet-1.18.1-0.x86_64 1/4 Verifying : kubectl-1.18.1-0.x86_64 2/4 Verifying : kubectl-1.18.0-0.x86_64 3/4 Verifying : kubelet-1.18.0-0.x86_64 4/4 Updated: kubectl.x86_64 0:1.18.1-0 kubelet.x86_64 0:1.18.1-0 Complete!
重启服务
[root@master01 ~]# systemctl daemon-reload
[root@master01 ~]# systemctl restart kubelet
重新调度节点
[root@master01 ~]# kubectl uncordon master01
node/master01 uncordoned
查看升级后的版本
[root@master01 ~]# kubectl version Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.1", GitCommit:"7879fc12a63337efff607952a323df90cdc7a335", GitTreeState:"clean", BuildDate:"2020-04-08T17:38:50Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.1", GitCommit:"7879fc12a63337efff607952a323df90cdc7a335", GitTreeState:"clean", BuildDate:"2020-04-08T17:30:47Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"} [root@master01 ~]# kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.1", GitCommit:"7879fc12a63337efff607952a323df90cdc7a335", GitTreeState:"clean", BuildDate:"2020-04-08T17:36:32Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}
4.7、etcd还原
第一步
[root@master01 ~]# mv /etc/kubernetes/manifests /etc/kubernetes/manifests.bak
第二步
[root@master01 kubernetes]# mv /var/lib/etcd /var/lib/etcd.bak
第三步
[root@master01 backup]# ETCDCTL_API=3 etcdctl snapshot restore /data/backup/etcd-snapshot.db --data-dir=/var/lib/etcd 2024-05-21 15:11:01.032006 I | mvcc: restore compact to 2465742 2024-05-21 15:11:01.057757 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
还原文件夹
[root@master01 backup]# mv /etc/kubernetes/manifests.bak /etc/kubernetes/manifests
4.8、检查检点就绪
[root@master01 ~]# kubectl get node NAME STATUS ROLES AGE VERSION master01 Ready master 362d v1.18.1 work01 Ready <none> 362d v1.18.0 work02 Ready <none> 362d v1.18.0
可以看到STATUS的状态,然后describe看看节点的污点状态
[root@master01 ~]# kubectl describe work01
4.9、节点NotReady处理
[root@master01 ~]# systemctl status kubelet^C [root@master01 ~]# systemctl start kubelet [root@master01 ~]# systemctl enable kubelet
4.10、获取日志
[root@master01 ~]# kubectl logs nginx-dep-9fb696769-bzvkt
4.11、CPU使用最高的pod
kubectl top pod -l app=cpu-utilizer --sort-by="cpu"
4.12、扩容pod数量
[root@master01 ~]# kubectl scale deployment nginx-dep --replicas=4 deployment.apps/nginx-dep scaled
4.13、service
官方文档: https://kubernetes.io/zh-cn/docs/concepts/services-networking/service/
kubectl expose deployment front-end --port=80 --target-port=80 --type=NodePort --name=front-end-svc
五、节点处理
5.1、节点NotReady处理
kubectl get node ssh k8s-work2 sudo -i systemctl start kubectl systemctl status kubectl systemctl enable kubectl
5.2、获取pod的错误日志
kubectl config use-context k8s kubectl logs bar| grep "file-not-found" > /opt/KUTR00101/bar
5.3、获取CPU使用率最高的pod
kubectl top pod -l name=cpu-utilizer --sort-by="CPU" -A
6、工作负载和调度
6.1、扩容deployment
kubectl scale deployment loadbalance --replicate=5
6.2、节点选择调度
任务——配置pods和容器——将pod分配给节点
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: nginx nodeSelector: disktype: ssd
6.3、pod配置多容器
apiVersion: v1 kind: Pod metadata: name: kucc4 spec: containers: - name: nginx image: nginx - name: redis image: redis -name: memcached image: memcached
6.3、边车容器
概念——集群管理——日志架构
首先创建实验数据
apiVersion: v1 kind: Pod metadata: name: legacy-app spec: containers: - name: count image: docker.io/library/busybox imagePullPolicy: IfNotPresent args: - /bin/sh - -c - > i=0; while true; do echo "$i: $(date)" >> /var/log/legacy-app.log; sleep 1; done
导出yaml文件
[root@master ~]# kubectl get pod legacy-app -o yaml > legacy2.yaml
编辑导出的yaml文档
apiVersion: v1 kind: Pod metadata: annotations: cni.projectcalico.org/containerID: f3f2e1b28b9d73b7dcc7d2762a69a3d3fe081a483a99c4e27ad17f4d9e19683c cni.projectcalico.org/podIP: 10.244.140.81/32 cni.projectcalico.org/podIPs: 10.244.140.81/32 kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"name":"legacy-app","namespace":"default"},"spec":{"containers":[{"args":["/bin/sh","-c","i=0; while true; do \n echo \"$i: $(date)\" \u003e\u003e /var/log/legacy-app.log; \n sleep 1; \ndone \n"],"image":"docker.io/library/busybox","imagePullPolicy":"IfNotPresent","name":"count"}]}} creationTimestamp: "2024-06-25T03:06:28Z" name: legacy-app namespace: default resourceVersion: "817549" uid: 58793a8c-94b0-4229-9878-add3519f9fa1 spec: containers: - args: - /bin/sh - -c - "i=0; while true; do \n echo \"$i: $(date)\" >> /var/log/legacy-app.log; \n sleep 1; \ndone \n" image: docker.io/library/busybox imagePullPolicy: IfNotPresent name: count resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /var/run/secrets/kubernetes.io/serviceaccount name: kube-api-access-qzkqn readOnly: true volumeMounts: - name: varlog mountPath: /var/log - name: sidecar image: busybox args: [/bin/sh, -c, 'tail -n+1 -f /var/log/legacy-app.log'] volumeMounts: - name: varlog mountPath: /var/log dnsPolicy: ClusterFirst enableServiceLinks: true nodeName: node02 preemptionPolicy: PreemptLowerPriority priority: 0 restartPolicy: Always schedulerName: default-scheduler securityContext: {} serviceAccount: default serviceAccountName: default terminationGracePeriodSeconds: 30 tolerations: - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists tolerationSeconds: 300 - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists tolerationSeconds: 300 volumes: - name: kube-api-access-qzkqn projected: defaultMode: 420 sources: - serviceAccountToken: expirationSeconds: 3607 path: token - configMap: items: - key: ca.crt path: ca.crt name: kube-root-ca.crt - downwardAPI: items: - fieldRef: apiVersion: v1 fieldPath: metadata.namespace path: namespace volumes: - name: varlog emptyDir: {} status: conditions: - lastProbeTime: null lastTransitionTime: "2024-06-25T03:06:28Z" status: "True" type: Initialized - lastProbeTime: null lastTransitionTime: "2024-06-25T03:06:29Z" status: "True" type: Ready - lastProbeTime: null lastTransitionTime: "2024-06-25T03:06:29Z" status: "True" type: ContainersReady - lastProbeTime: null lastTransitionTime: "2024-06-25T03:06:28Z" status: "True" type: PodScheduled containerStatuses: - containerID: containerd://a52bfd6a806ba5d276237f9b14ede11e2ff18b6daa37d00686557cd0f9e25fc5 image: docker.io/library/busybox:latest imageID: docker.io/library/busybox@sha256:6d9ac9237a84afe1516540f40a0fafdc86859b2141954b4d643af7066d598b74 lastState: {} name: count ready: true restartCount: 0 started: true state: running: startedAt: "2024-06-25T03:06:29Z" hostIP: 192.168.43.134 phase: Running podIP: 10.244.140.81 podIPs: - ip: 10.244.140.81 qosClass: BestEffort startTime: "2024-06-25T03:06:28Z"
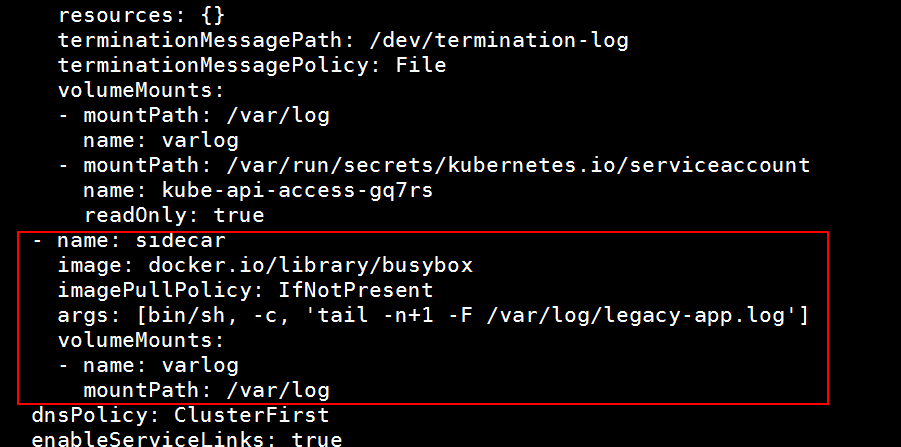
然后删除原有的pod
[root@master ~]# kubectl delete pod legacy-app
然后用修改的yaml文件重新创建
[root@master ~]# kubectl apply -f sidetest2.yaml
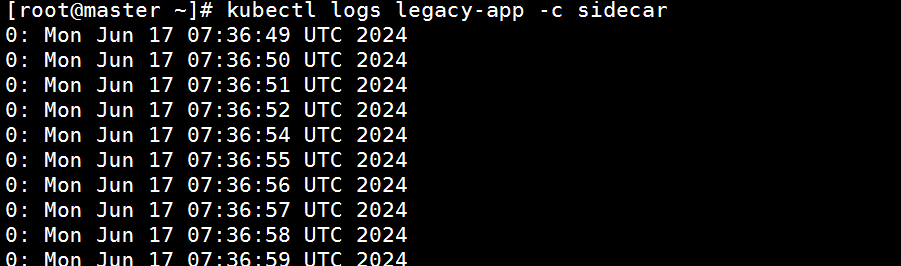
然后检查
[root@master ~]# kubectl logs legacy-app -c sidecar
七、网络策略
7.1、网络策略 概念——服务、负载均衡和联网
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-port-namespace #注意修改 namespace: my-app #注意修改 spec: podSelector: {} #注意修改为大括号 policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: name: big-corp #注意修改为name ports: - protocol: TCP port: 8080
7.2、SVC暴露
首先编辑deployment
kubectl edit deployment front-end
ports: - containerPort: 80 name: http protocol: TCP
创建service, 概念——服务、负载均衡和联网
apiVersion: v1 kind: Service metadata: name: front-end-svc spec: type: NodePort #注意加TYPE selector: app: myapp #注意修改 ports: - protocol: TCP port: 80 targetPort: 80
7.3、创建Ingress 概念——服务、负载均衡和联网
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ping nemespace: default annotations: nginx.ingress.kubernetes.io/rewrite-target: / spec: #ingressClassName: nginx-example 这一行不要 rules: - http: paths: - path: /hello pathType: Prefix backend: service: name: front-end-svc port: number: 80
八、存储
8.1、创建PV
任务——配置Pod和容器
apiVersion: v1 kind: PersistentVolume metadata: name: app-data spec: storageClassName: nfs-client capacity: storage: 2Gi accessModes: - ReadWriteOnce hostPath: path: "/srv/app-data"
创建PVC
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pv-volume spec: storageClassName: nfs-client accessModes: - ReadWriteOnce resources: requests: storage: 10Mi
创建Pod
apiVersion: v1 kind: Pod metadata: name: web-server spec: volumes: - name: task-pv-storage persistentVolumeClaim: claimName: pv-volume containers: - name: task-pv-container image: nginx ports: - containerPort: 80 name: "http-server" volumeMounts: - mountPath: "/usr/share/nginx/html" name: task-pv-storage
扩容PVC,不要忘了--save-config
kubectl edit pvc pv-volume --save-config
九、访问控制
clusterrole 参考——API访问控制——使用RBAC鉴权
[root@master ~]# kubectl create clusterrole deployment-clusterrole --verb=create --resource=deployment,statefulset,daemonset
创建servicecount,注意
[root@master ~]# kubectl create serviceaccount cicd-touken -n app-team1
serviceaccount/cicd-touken created
绑定
kubectl create rolebinding myappnamespace-myapp-view-binding --clusterrole=deployment-clusterrole --serviceaccount=app-team1:cicd-token --namespace=app-team1
十、版本升级
任务——集群管理——升级kubeadm集群
首先驱逐主节点的pod
[root@master ~]# kubectl drain master --ignore-daemonsets
然后连接到主节点
ssh master
sudo -i
然后安装官网的操作进行
sudo apt update
sudo apt-cache madison kubeadm
升级kubeadm
sudo apt-mark unhold kubeadm && \ sudo apt-get update && sudo apt-get install -y kubeadm='1.30.x-*' && \ sudo apt-mark hold kubeadm
检查版本
kubeadm version
验证升级计划
sudo kubeadm upgrade plan
升级——注意,一定要忽略etcd
sudo kubeadm upgrade apply v1.30.x --etcd-upgrade=false
升级kubelet和kubectl
sudo apt-mark unhold kubelet kubectl && \ sudo apt-get update && sudo apt-get install -y kubelet='1.30.x-*' kubectl='1.30.x-*' && \ sudo apt-mark hold kubelet kubectl
重启服务
sudo systemctl daemon-reload
sudo systemctl restart kubelet
解除节点保护
kubectl uncordon master
https://www.cnblogs.com/vinsent/p/12460973.html
https://cloud.tencent.com/developer/article/2372359
https://cloud.tencent.com/developer/article/2324926

 浙公网安备 33010602011771号
浙公网安备 33010602011771号