模型的评估
前面我们已经实现了七种模型,接下来我们分别会对这七种进行评估,主要通过auccuracy,precision,recall,F1-score,auc。最后画出各个模型的roc曲线
接下来分别看看各个评分的意义
accuracy(准确率)
对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。也就是损失函数是0-1损失时测试数据集上的准确率。比如有100个数据,其中有70个正类,30个反类。现在分类器分为50个正类,50个反类,也就是说将20个正类错误的分为了反类。准确率为80/100 = 0.8
precision(精确率)
表示被”正确被检索的item(TP)"占所有"实际被检索到的(TP+FP)"的比例.,这个指标越高,就表示越整齐不混乱。比如还是上述的分类中。在分为反类中有30个分类正确。那么精确率为30/50 = 0.6
recall(召回率)
所有"正确被检索的item(TP)"占所有"应该检索到的item(TP+FN)"的比例。在上述的分类中正类的召回率为50/70 = 0.71。一般情况下准确率高、召回率就低,召回率低、准确率高
F1-score
统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0。
![]()
auc
ROC曲线下与坐标轴围成的面积
模型评估
先导入所需要的包
import pandas as pd import numpy as py import matplotlib.pyplot as plt from xgboost import XGBClassifier from sklearn.metrics import roc_auc_score from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score from sklearn.metrics import roc_curve,auc from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier from lightgbm import LGBMClassifier from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn import svm data_all = pd.read_csv('D:\\data_all.csv',encoding ='gbk') X = data_all.drop(['status'],axis = 1) y = data_all['status'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,random_state=2018) #数据标准化 scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
接下定义一个函数实现了评价的方法以及画出了roc曲线
def assess(y_pre, y_pre_proba): acc_score = accuracy_score(y_test,y_pre) pre_score = precision_score(y_test,y_pre) recall = recall_score(y_test,y_pre) F1 = f1_score(y_test,y_pre) auc_score = roc_auc_score(y_test,y_pre_proba) fpr, tpr, thresholds = roc_curve(y_test,y_pre_proba) plt.plot(fpr,tpr,'b',label='AUC = %0.4f'% auc_score) plt.plot([0,1],[0,1],'r--',label= 'Random guess') plt.legend(loc='lower right') plt.title('ROCcurve') plt.xlabel('false positive rate') plt.ylabel('true positive rate') plt.show()
接着我们分别对这七种模型进行评估以及得到的roc曲线图
#LR lr = LogisticRegression(random_state = 2018) lr.fit(X_train, y_train) pre_lr = lr.predict(X_test) pre_porba_lr = lr.predict_proba(X_test)[:,1] assess(pre_lr,pre_porba_lr)
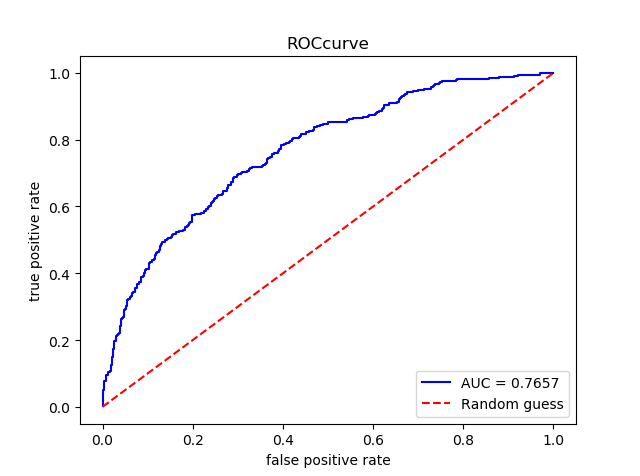
#DecisionTree dt = DecisionTreeClassifier(random_state = 2018) dt.fit(X_train , y_train) pre_dt = dt.predict(X_test) pre_proba_dt = dt.predict_proba(X_test)[:,1] assess(pre_dt,pre_proba_dt)

#SVM svc = svm.SVC(random_state = 2018) svc.fit(X_train , y_train) pre_svc = svc.predict(X_test) pre_proba_svc = svc.decision_function(X_test) assess(pre_svc,pre_proba_svc)

#RandomForest rft = RandomForestClassifier() rft.fit(X_train,y_train) pre_rft = rft.predict(X_test) pre_proba_rft = rft.predict_proba(X_test)[:,1] assess(pre_rft,pre_proba_rft)

#GBDT gb = GradientBoostingClassifier() gb.fit(X_train,y_train) pre_gb = gb.predict(X_test) pre_proba_gb = gb.predict_proba(X_test)[:,1] assess(pre_gb,pre_proba_gb)
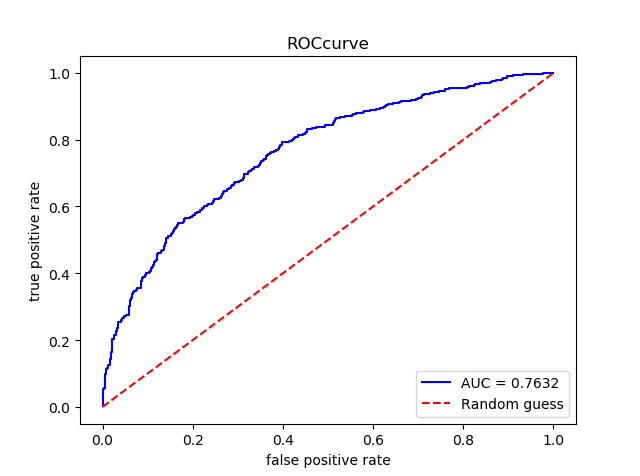
#XGBoost xgb_c = XGBClassifier() xgb_c.fit(X_train,y_train) pre_xgb = xgb_c.predict(X_test) pre_proba_xgb = xgb_c.predict_proba(X_test)[:,1] assess(pre_xgb,pre_proba_xgb)
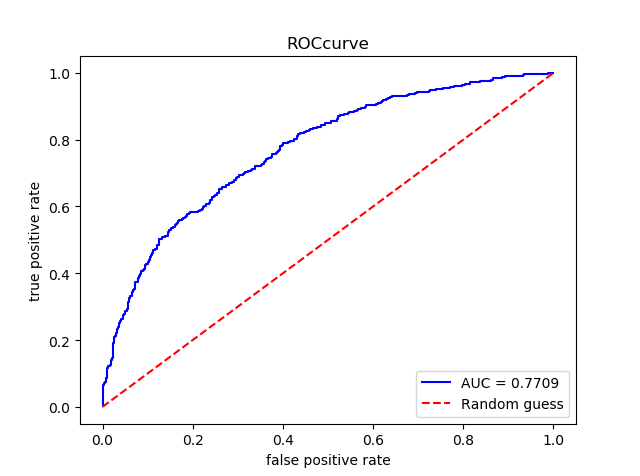
#LightGBM lgbm_c = LGBMClassifier() lgbm_c.fit(X_train,y_train) pre_lgbm = lgbm_c.predict(X_test) pre_proba_lgbm = lgbm_c.predict_proba(X_test)[:,1] assess(pre_lgbm,pre_proba_lgbm)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号