
使用爬虫scrapy库爬取58同城出租房的联系方式地址
一 .创建一个爬虫工程
scrapy startproject tongcheng
#创建一只爬虫
scrapy genspider zufang 域名(xa.58.com/zufang/)
二.配置setting文件
ROBOTSTXT_OBEY = Ture 改为 Fales
#打印日志的文件
LOC_FILE = "zufang.txt"
RETRY_ENABLED= True
RETAY_TIMES= 0
#设置爬取时间
DOWNLOAD_DELAY= 3
一。#开始定义数据结构
import scrapy
class CeshiItem(scrapy.Item):
name = scrapy.Field()
# 经纪人电话
phone = scrapy.Field()
# 所在小区
address = scrapy.Field()
# 房子价格
price = scrapy.Field()
写爬虫文件
import scrapy
from ceshi.items import CeshiItem
class TongchengSpider(scrapy.Spider):
name = 'tongcheng'
allowed_domains = ['xa.58.com/zufang']
start_urls = ['https://xa.58.com/zufang/']
#获取每一页的url
def start_requests(self):
#从第一页开始爬取到第17页
for i in range(1,70):
url = 'https://xa.58.com/zufang/pn{}/'
fururl = url.format(i)
yield scrapy.Request(fururl,callback=self.parse)
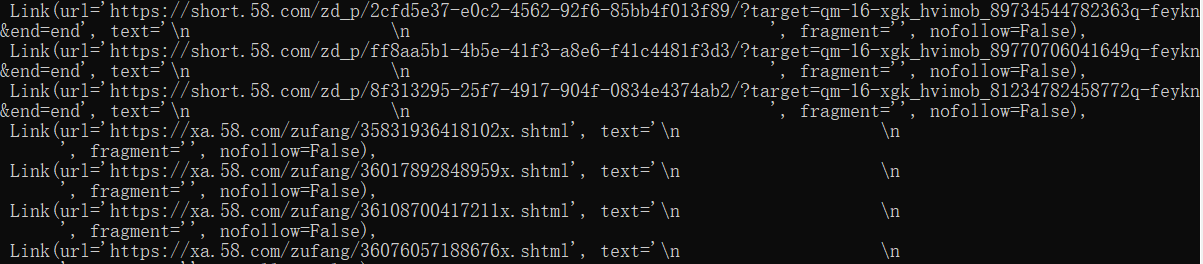
def parse(self, response):
#拼接详情页面的url
#print(response.url)
#因为直接抓包抓取出来的url格式不一样被处理过。如下
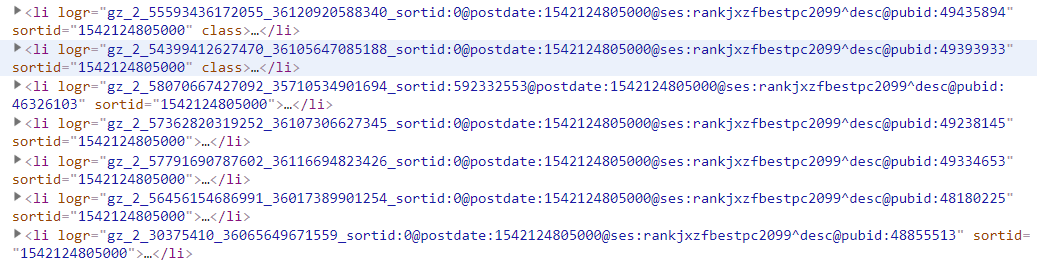
#拼接url需要<li logr 里面的_36065********这段数字拼接
logrs = response.xpath('//li[@logr]/@logr').extract()
list1 = []
for logr in logrs:
#得到的logr中间有空的list会出错 #列表的超出索引处理异常
try:
num = logr.split('_')[3]
list1.append(num)
except:
pass
for i in list1:
url='https://xa.58.com/zufang/{}x.shtml'
fulurl= url.format(i)
#
yield scrapy.Request(fulurl,callback=self.url_parse, dont_filter=True)
def url_parse(self, response):
# print(response.url)
item = CeshiItem()
#联系人名字
item['name'] = response.xpath('//p[@class="agent-name f16 pr"]/a/text()').extract_first().strip('(经纪人)')
#联系人电话
item['phone'] = response.xpath('//div[@class="house-chat-phone"]/span/text()').extract_first()
#所在小区
item['address']=response.xpath('//ul[@class="f14"]/li[4]/span/a/text()').extract_first()
#所属区域
item['area'] = response.xpath('//ul[@class="f14"]/li[5]/span/a/text()').extract_first()
yield item
配置管道
ITEM_PIPELINES = {
'ceshi.pipelines.CeshiPipeline': 300,
}
import json
class CeshiPipeline(object):
def open_spider(self,spider):
self.fp=open('chuzu.txt','w',encoding='utf8')
def process_item(self, item, spider):
t = dict(item)
string = json.dumps(t,ensure_ascii=False)
self.fp.write(string+'\n')
self.fp.flush()
return item
def close_spider(self,spider):
self.fp.close()
#配置ua和ip
#配置ip
class RandomDownloaderMiddleware(object):
def __init__(self):
self.ippools_list=[
'120.92.74.237:3128',
'120.92.74.189:3128',
'119.27.177.169:000',
'218.60.8.99:3129',
'203.86.26.9:312'
]
def process_request(self, request, spider):
self.ip = random.choice(self.ippools_list)
# print('#' * 50)
# print('当前使用的ip---%s' % self.ip)
# print('#' * 50)
request.meta['proxy'] ='http://'+ self.ip
request.meta['download_timeout'] = 5
def process_exception(self,request,exception,spider):
# print('*'*50)
# print(exception)
# print('*'*50)
self.ippools_list.remove(self.ip)
return request
#配置ua
class CeshiDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
def __init__(self):
self.ua_list=[
'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'
]
def process_request(self, request, spider):
ua=random.choice(self.ua_list)
# print('*'*50)
# print('当前使用的ua---%s'% ua)
# print('*'*50)
request.headers.setdefault('User-Agent',ua)

