
Redis学习笔记
Redis学习 记录
1、NoSQL 数据库
NoSQL,泛指非关系型的数据库。
- 分类
- 键值(Key-Value)存储数据库
- 列存储数据库
- 文档型数据库
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
2、Redis 事务
基本介绍
- Redis 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 作用:串联多个命令防止别的命令插队。
执行流程(过程是原子性的)
- multi(开启事务)
- 从输入 multi 开始输入的命令都会依次进入命令队列中,但不会执行,直到输入 exec 命令后
- 命令操作(set···)
- exec/discard(执行/回滚)
- 组队的过程中可以使用 discard 命令来放弃组队。
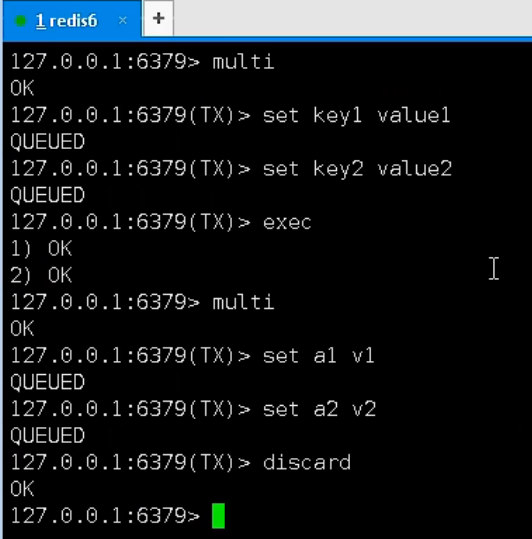
- 组队的过程中可以使用 discard 命令来放弃组队。
事务的错误处理
- 情况一:在组队 multi 过程中有错误
- 所有命令都不会执行
- 情况二:在执行 exec 过程中发生错误
- 谁有错谁不会执行,其他命令正常执行
事务和锁机制
在并发操作下,我们需要对部分数据加以控制,防止多线程环境下,造成数据不一致。比较常见的操作就是加锁。从加锁方式上主要分为两大类。
-
悲观锁
- 只允许该数据被单线程访问,在该数据被一个线程访问时,获取该数据的这把锁,其他线程只能排队等待。
- MySQL中的行锁,表锁,读锁(S),写锁(X),以及 syncronized 实现的锁均为悲观锁。
- Java中synchronized和ReentrantLock等独占锁本质上就是悲观锁。
-
乐观锁
- 不需要对操作的数据进行加锁,只有到数据提交的时候才通过一种机制来验证数据是否存在冲突。
- 乐观锁通常是通过在表中增加一个版本(version)或时间戳(timestamp)来实现,其中,版本最为常用。
- 最常见的乐观锁就是 Java 中 JUC 工具类就是基于操作系统底层 CAS 来实现的,CAS 操作就是乐观锁体现。
- 用途
- Redis 就是利用这种 set and check 机制来实现事务的。适用于读多写少的场景。
-
乐观锁应用 ---- 监视器
- watch key
- 在执行multi之前,先执行 watch key1,key2···,如果事务咋执行之前这些 key 被其他客户端改动,那么事务将被打断(
- 由于检查到乐观锁机制中的版本号不一致)
- watch key
Redis 事务特性
-
单独的隔离操作
- 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
-
没有隔离级别的概念
- 队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行
-
不保证原子性
- 事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
3、秒杀案例
超卖问题解决:使用事务加watch(乐观锁)解决,使用watch监视库存,然后放到事务中进行组队操作。
// 监视库存
// Redis Watch 命令用于监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断
jedis.watch(key);
// 组队执行
Transaction multi = jedis.multi();
multi.decr(key);
multi.sadd(userKey, userId);
List<Object> results = multi.exec();
// 对执行结果进行判断,执行失败结果集为空
if (results == null || results.size() == 0) {
jedis.close();
return false;
}
return true;
连接超时问题
- 线程池解决
乐观锁造成库存遗留问题
通过 lua 脚本解决争抢问题,实际上是 Redis 利用其单线程的特性,用任务队列的方式解决多任务并发的问题。
4、Redis 持久化
Redis 提供了2种不同形式的持久化方式
- RDB(Redis DataBase)
- AOF(Append Of File)
4.1、Redis 持久化之 RDB
RDB(Redis DataBase)
- 在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是 Snapshot 快照,它恢复时是将快照文件直接读到内存里
- 备份是如何执行的
- Redis 会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何 IO 操作的,这就确保了极高的性能
- 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那么 RDB 方式要比 AOF 方式更加的高效
- 优缺点
- 优点:
- 适合大规模的数据恢复
- 对数据完整性和一致性要求不高更适合使用
- 节省磁盘空间
- 缺点:
- Fork 的时候,需要 2倍的空间
- fork “写时拷贝” 消耗性能
- 最后一次持久化前机器 down 掉,数据会丢失
- 优点:

Fork
- Fork 的作用是赋值一个与当前进程一样的进程,创建一个子进程。
- fork() 会产生一个和父进程完全相同的子进程,遵循 “读时共享,写时复制” 原则。
- 一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容赋值一份给子进程。
4.2、Redis 持久化之 AOF
基本介绍
- 以日志的形式来记录每个写操作(增量保存)
- 将 Redis 执行过的所有写指令记录下来(读操作不记录)
- 只许追加文件担保户可以改写文件
- Redis 启动之初会读取该文件重新构建数据(根据日志文件将写指令从前到后执行一次完成数据的恢复)
AOF 持久化流程
- 客户端的请求写命令会被 append 追加到 AOF 缓冲区内
- AOF 缓冲区根据 AOF 持久化策略 [always,everysec,no] 将操作 sync 同步到磁盘的 AOF 文件中
- 持久化同步频率设置
- always: 每次的写入都会立刻记入日志;性能较差但数据完整性比较好
- everysec:每秒同步,如果宕机,本秒的数据可能丢失
- no:不主动进行同步,把同步时机交给操作系统
- 持久化同步频率设置
- AOF 文件大小超过重写策略或手动重写时,会对 AOF 文件 rewrite 重写,压缩 AOF 文件容量
- Redis 服务重启时,会重新 load 加载 AOF 文件中的写操作达到数据恢复的目的
AOF 默认不开启
- 可以在 redis.conf 中配置文件名称,默认为 appendonly.aof
- AOF 文件的保存路径同 RDB 的路径一直
AOF 和 RDB 同时开启,Redis 优先哪种?
- 系统默认选择 AOF 的数据(数据不会存在丢失,安全至上,数据一致性、完整性优先)
恢复
-
正常恢复
- 重启 Redis 重新加载
-
异常恢复
- 修改默认的 appendonly no 改为 yes
优缺点
- 优点:

- 备份机制更稳健,丢失数据概率更低
- 可读的日志文本,通过操作 AOF 文件,可以处理误操作
-
缺点:
- 比起 RDB 占用更多的磁盘空间
- 恢复备份速度要慢
- 每次读写同步的话,性能压力较大
- 存在潜在 BUG,会造成不能恢复
------官方建议------:两种同时开启
5、Redis 主从复制
介绍
- 只能一主一(多)从
- 可以采用集群防止这一台主机挂掉导致服务瘫痪
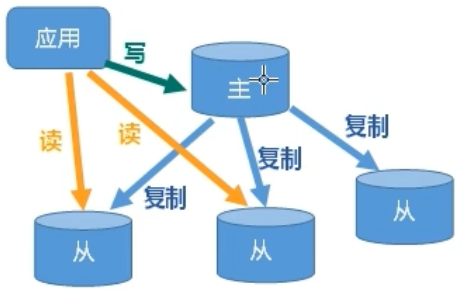
用途作用
- 读写分离,性能扩展
- 容灾快速恢复
常用 3 招
-
一主二仆
- 当一台从服务器挂掉后,从服务器重启后不能继承上次的主从配置,需要重新配置从服务器,并且配置成功后会从头复制主库中的数据
- slaveof [ip addr] [port]
- 主服务器 down 掉后,不会抹除从服务器的配置,待主服务器重启后,主从关系照旧
- 当一台从服务器挂掉后,从服务器重启后不能继承上次的主从配置,需要重新配置从服务器,并且配置成功后会从头复制主库中的数据
-
薪火相传
- 主服务器A 负责其中一个从服务器B 的数据发送,其他的从服务器的数据来源由服务器B 来负责。
- 优缺点:
- 优点:性能提升,主服务器A 压力减小
- 缺点:从服务器B 挂掉之后导致其他从服务器无法同步
-
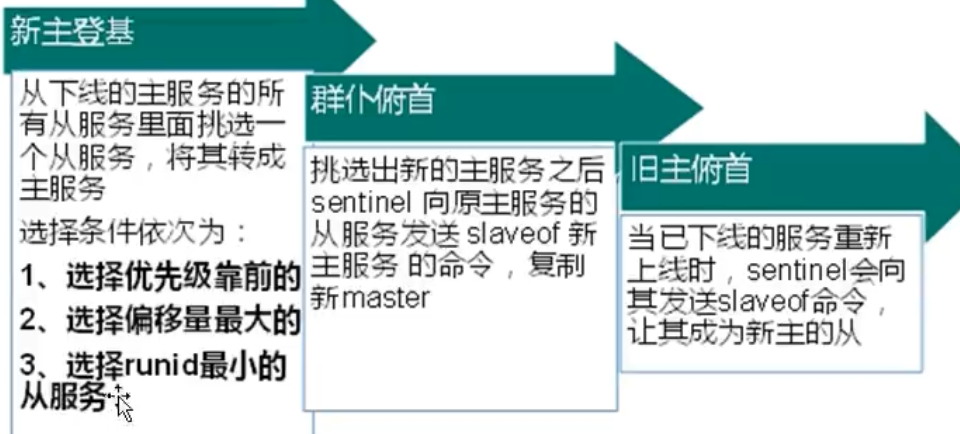
反客为主
- 命令:
slaveof no one - 主服务器A 挂掉后,A 的从服务器B 立马摇身一变成主服务器(前提是给从库配置好)
- 命令:
哨兵模式
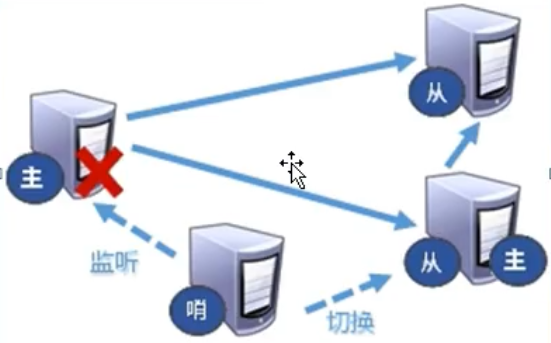
- 概念:反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转为主库。
- 配置哨兵,填写内容
sentinel monitor mymaster 127.0.0.1 6379 1- 其中 mymaster 为监控对象起的服务器名称,1 为至少有多少个哨兵同一迁移的数量
- 原主机重启后会变为从机
- 故障恢复
主从复制原理
- 从服务器请求主服务器
- 主服务器接收到命令,主动向从服务器发送数据文件

两种复制方式
- 全量复制:slave 服务在接收到数据库文件数据后,将其存盘并加载到内存种。
- 增量复制:Master 继续将新的所有收集到的修改命令一次传给 slave,完成同步。

6、Redis 集群
问题引入
- 容量不够,redis 如何进行扩容?
- 并发写操作,redis 如何分摊?
- 之前通过代理主机来解决(需要 8台 服务器),但是 redis3.0 中提供了解决方案。就是无中心化集群配置。
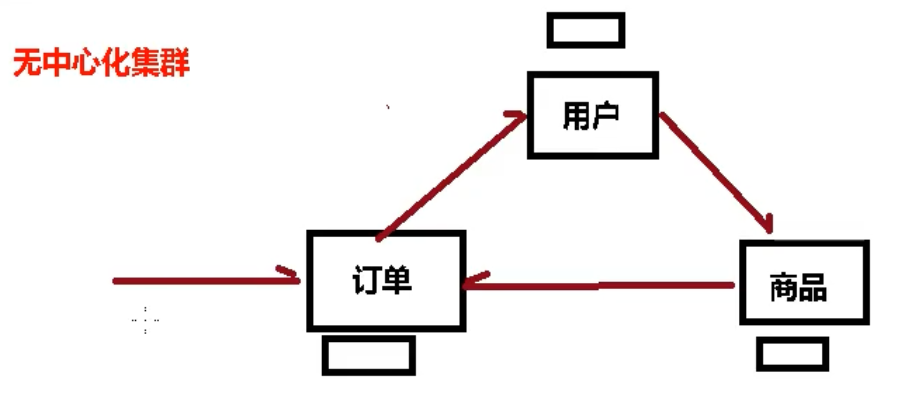
什么是集群?
Redis 集群实现了对 Redis 的水平扩容,即启动 N 个 redis 节点,将整个数据库分布存储在这 N 个节点中,每个节点存储总数据的 1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
删除持久化数据
- 将 rdb、aof 文件都删除掉。
集群配置
cluster-enabled yes打开集群模式cluster-config-file nodes-6379.conf设置节点配置文件名cluster-node-timeout 15000设置节点失联时间,超过该时间(毫秒),集群自动进行主从切换4
redis cluster 如何分配这六个节点?
一个集群至少要有三个主节点
选项 --cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
分配原则尽量保证每个主数据库运行在不同的 IP 地址,每个从库和主库不在一个 IP 地址上。
什么是 slots(插槽)
-
一个 Redis 集群包括16384 个插槽,会将插槽分配到每个节点主机上,每个主机负责一个范围的插槽
-
入值
- set key ,key 是根据 hash 算法得出插槽编号,随机分配到插槽对应主机存储
- 可以采用分组在一个 slot 中存储多个 key
- 语法 :
mset k1{groupname} v1 k2{groupname} v2 ···
- 语法 :
-
查值
- 每个主机只能查询自己的对应的插槽范围内的值
-
故障恢复
- 主节点主机 down 掉,节点的从机上位。
Redis 集群优缺点
-
优点
-
实现扩容
-
分摊压力
-
无中心配置相对简单
-
-
缺点
- 多键操作是不被支持的
- 多键的 Redis 事务是不被支持的。lua 脚本不被支持
7、Redis 应用问题解决
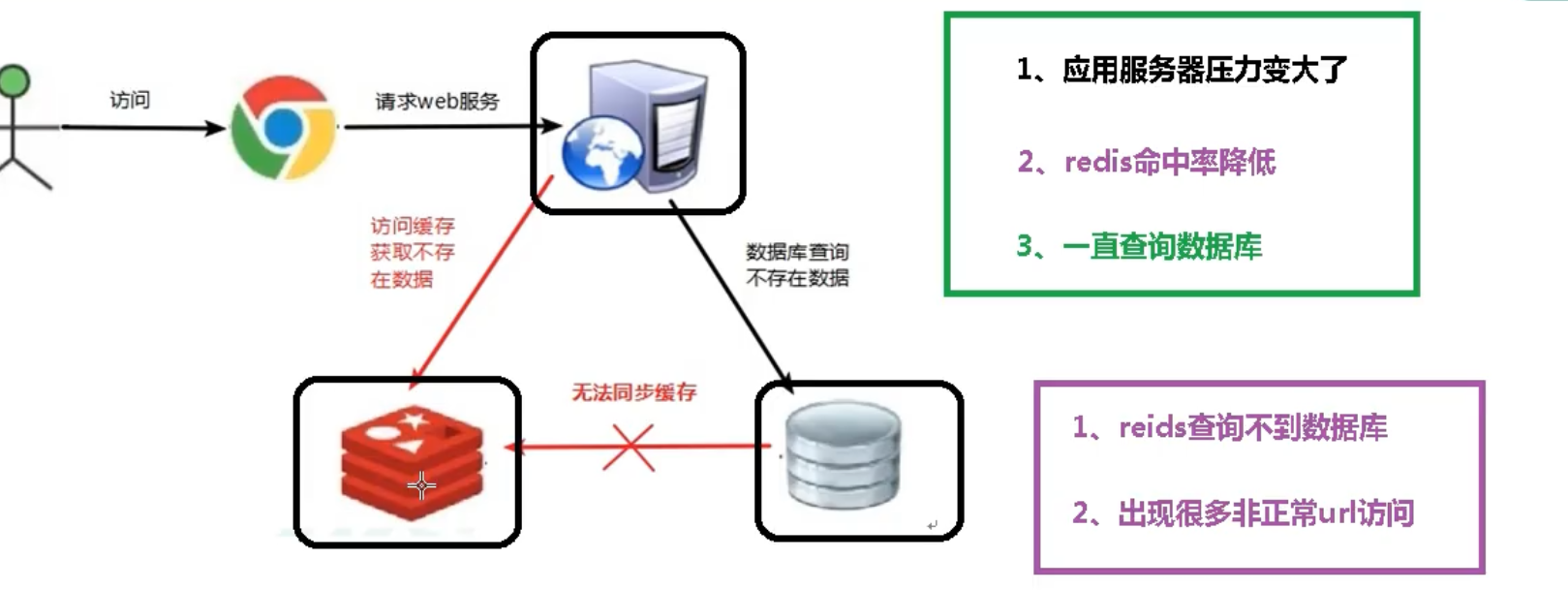
缓存穿透
-
分析原因
-
被黑客攻击
-
-
-
解决方案

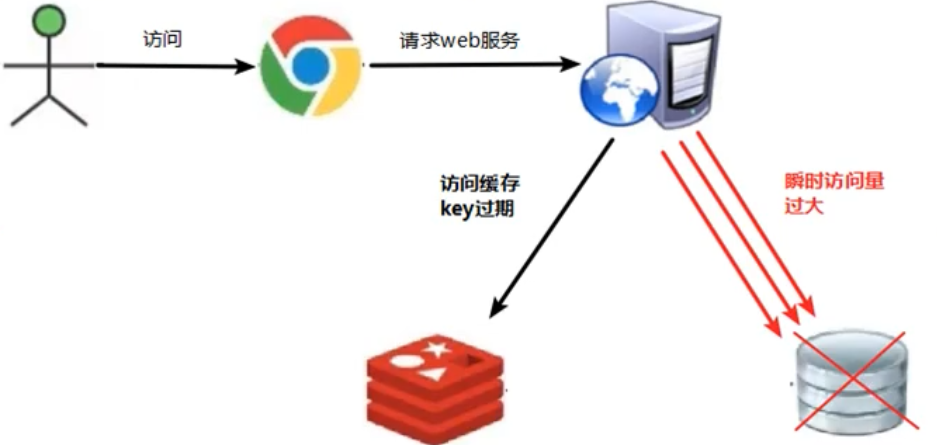
缓存击穿
-
分析原因
- 热点 key 过期
-
解决方案

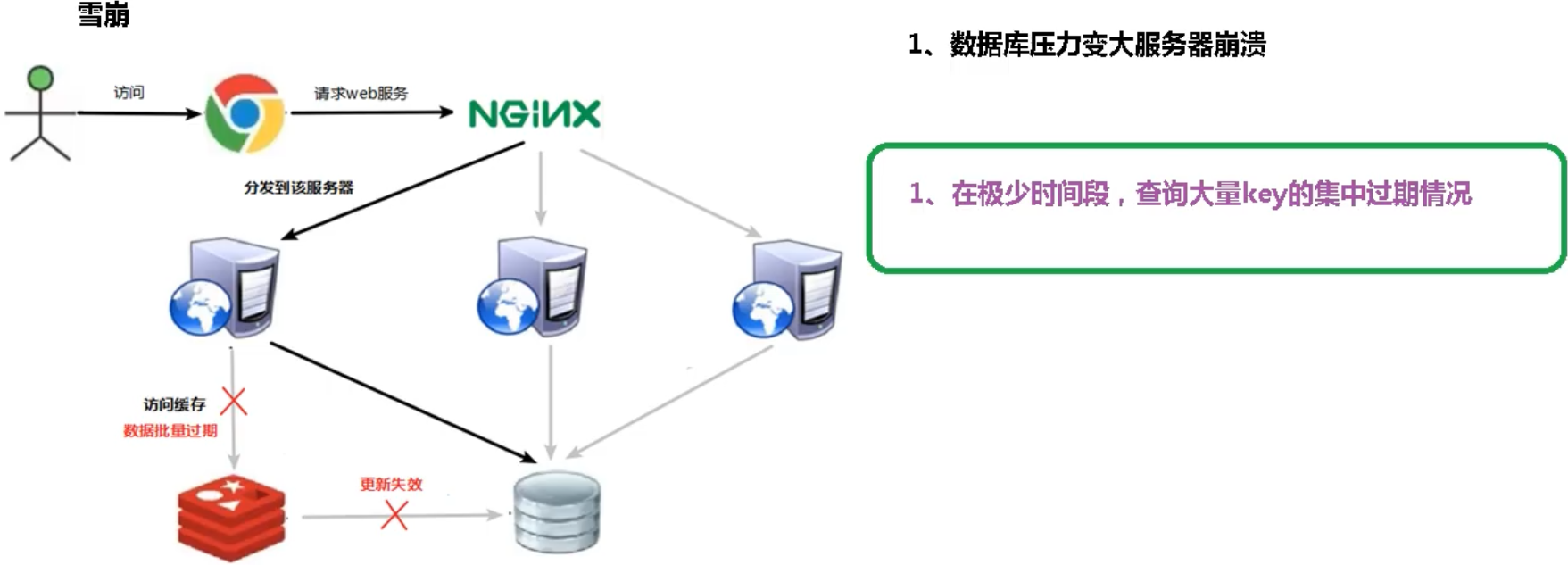
缓存雪崩
-
问题分析
-
解决方案
-


分布式锁
-
问题描述
-
解决方案
-

-
优缺点:
-
-
具体实现
-

-
NX 条件:不存在
-
EX 条件:过期时间
-
-
满足条件



