Effective STL 第四部分
条款38:把仿函数类设计为用于值传递
STL函数对象在函数指针之后成型,所以STL中的习惯是当传给函数和从函数返回时函数对象也是值传递的(也就是拷贝)。最好的证据是标准的for_each声明,这个算法通过值传递获取和返回函数对象:
STL函数对象是对函数指针的抽象形式,在STL中函数对象在函数中的传递也是按值传递的。for_each算法的返回值就是一个函数对象,它的第三个参数也是函数对象。
template Function // 注意值返回 for_each(InputIterator first,InputIterator last,Function f); // 注意值传递
c和C++中 以函数指针为参数的例子,函数指针是按值传递的
1 void qsort(void* base, size_t nmemb, size_t size, 3 int(*cmpfcn)(const void *, const void *));
因为STL函数对象按值传递的特性,所以在设计函数对象时要:
- 将函数对象要尽可能的小,以减少拷贝的开销。
- 函数对象尽量是单态的(不要使用虚函数),以避免剥离问题。
函数对象本身只包含一个指针,而且是不含虚函数的单态对象。真正的数据和操作都是由指针所指向的对象完成的。
对于这个实现,要注意的是在函数对象拷贝的过程中,如何维护这个指针成员。既能避免内存泄漏而且可以保证指针有效性的智能指针是个不错的选择。
shared_ptr<functorImp<T> *> pImp;
条款39:用纯函数做判断式
判别式的一些基本概念:
- 判别式 - 返回值为bool类型或者可以隐式转换为bool类型的函数
- 纯函数 - 返回值仅与函数的参数相关的函数,即返回值只依赖于参数的函数
- 判别式类 – operator()函数是判别式的函数子类。 STL中凡是能接受判别式的地方,就可以接受一个判别式类的对象。
对于判别式不是纯函数的一个反例
class Remove3rdElement : public unary_function<int,bool> { public: Remove3rdElement():i(0){} bool operator() (const int&) { return ++i == 3; } int i; }; ... vector<int> myvector; vector<int>::iterator it; myvector.push_back(1); myvector.push_back(2); myvector.push_back(3); myvector.push_back(4); myvector.push_back(5); myvector.push_back(6); myvector.push_back(7); myvector.erase(remove_if(myvector.begin(), myvector.end(), Remove3rdElement()),myvector.end());
// 1,2,4,5,7 remove_if之后的结果为 1,2,4,5,7,6,7。 返回值指向的是第六个元素。
条款40:使仿函数类可适配
假设有一个Widget*指针的list和一个函数来决定这样的指针是否确定一个有趣的Widget:
list widgetPtrs; bool isInteresting(const Widget *pw);
如果要在list中找第一个指向有趣的Widget的指针,可以这样做:
list::iterator i = find_if(widgetPtrs.begin(), widgetPtrs.end(),isInteresting); if (i != widgetPtrs.end()) { ... // 处理第一个有趣的指向Widget的指针 }
取而代之的是,必须对isInteresting应用ptr_fun在应用not1之前:
list::iterator i = find_if(widgetPtrs.begin(), widgetPtrs.end(),not1(ptr_func(isInteresting))); // 没问题 if (i != widgetPtrs.end()) { ... // 处理第一个指向Widget的指针 }
解 释:ptr_fun做的唯一的事是使一些typedef有效,而四个标准函数适配器(not1、not2、bind1st和bind2nd)都需要这些 typedef,一些其他非标准STL兼容的适配器(比如来自SGI和Boost)也需要。提供这些必要的typedef的函数对象称为可适配的,而缺乏 那些typedef的函数对象不可适配。可适配的比不可适配的函数对象可以用于更多的场景,所以只要能做到你就应该使你的函数对象可适配。
条款41:了解使用ptr_fun、mem_fun和mem_fun_ref的原因
对于ptr_fun在第40条已经有了一些介绍,它可以用在任何的函数指针上来使其可配接。
下面的例子,希望在myvector和myvector2的每一个元素上调用元素的成员函数。
class Widget { public : void test(); }; ... vector<Widget> myvector; vector<Widget*> myvector2; ... for_each(myvector.begin(),myvector.end(), &Widget::test); // 编译错误 for_each(myvector2.begin(),myvector2.end(), &Widget::test); //编译错误
而for_each的实现可能是这样的
template<typename InputIterator, typename Function> Function for_each(InputIterator begin, InputIterator end, Function f) { while (begin != end) f(*begin++); }
对于mem_fun和mem_fun_reference, 就是要使成员方法可以作为合法的函数指针传递
for_each(myvector.begin(),myvector.end(), mem_fun_ref(&Widget::test));
// 当容器中的元素为对象时使用mem_fun_ref for_each(myvector2.begin(),myvector2.end(), mem_fun(&Widget::test));
// 当容器中的元素为指针时,使用mem_fun
那么mem_fun是如何实现的呢?
1 1 template<typename R, typename C> 2 2 mem_fun_t<R,C> 3 3 mem_fun(R(C::*pmf)());
mem_fun接受一个返回值为R且不带参数的C类型的成员函数,并返回一个mem_fun_t类型的对象。mem_fun_t是一个函数子类,拥有成员函数的指针,并提供了operator()接口。operator中调用了通过参数传递进来的对象上的成员函数。
那么mem_fun是如何实现的呢?
1 template<typename R, typename C> 2 mem_fun_t<R,C> 3 mem_fun(R(C::*pmf)());
解释:STL里的一个普遍习惯:函数和函数对象总使用非成员函数的语法形式调用,而不直接支持成员函数的调用。
为了解决这个问题,mem_fun和mem_fun_ref便提出来了。。。。
mem_fun接受一个返回值为R且不带参数的C类型的成员函数,并返回一个mem_fun_t类型的对象。mem_fun_t是一个函数子类,拥有成员函数的指针,并提供了operator()接口。operator中调用了通过参数传递进来的对象上的成员函数。
条款42:确保less<T>与operator<具有相同的语义
STL规定,less总是等价于operator<, operator<是less的默认实现。
应当尽量避免修改less的行为,而且要确保它与operator<具有相同的意义。如果希望以一种特殊的方式来排序对象,那么就去创建一个新的函数子类,它的名字不能是less.
条款43:算法调用优先于手写的循环
算法往往作用于一对迭代器所指定的区间中的每一个元素上,所以算法的内部实现是基于循环的。虽然说类似于find和find_if的算法可能不会遍历所有的元素就返回了结果,但是在极端情况下,还是需要遍历全部的元素。
从以下几点分析,算法调用是优于手写的循环的
- 效率
- 正确性
- 可维护性
如:有一个支持重画的Widget类:
class Widget { public: ... void redraw() const; ... };
要重画一个list中的所有Widget对象,可以使用这样一个循环:
list lw; ... for (list::iterator i =lw.begin();i != lw.end(); ++i) { i->redraw(); }
也可以用for_each算法来完成:
for_each(lw.begin(), lw.end(),mem_fun_ref(&Widget::redraw));
而第二种更优,提倡使用。
条款44:尽量用成员函数代替同名的算法
有 些容器拥有和STL算法同名的成员函数。关联容器提供了count、find、lower_bound、upper_bound和 equal_range,而list提供了remove、remove_if、unique、sort、merge和reverse。大多数情况下,应该 用成员函数代替算法。这样做有两个理由:首先,成员函数更快;其次,比起算法来,它们与容器结合得更好(尤其是关联容器)。
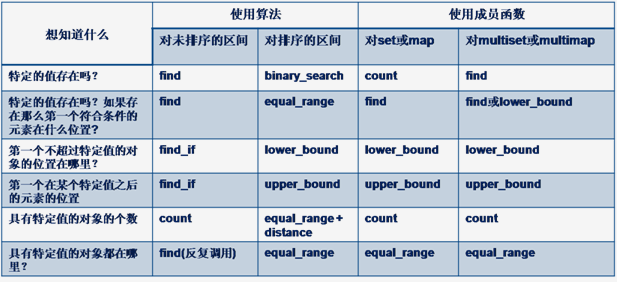
条款45:注意count、find、binary_search、lower_bound、upper_bound和equal_range的区别
你有一个容器或者你有一个由迭代器划分出来的区间——你要找的东西就在里面。你要
怎么完成搜索呢?可用的工具有:count、count_if、find、find_if、binary_search、lower_bound、
upper_bound和equal_range。面对着它们,怎么做出选择?下面是一个总结:
- count: 区间内是否存在某个特定的值,如果存在的话,这个值有多少个拷贝。
- find: 区间内时候存在某个特定的值,如果存在的话,第一个符合条件的值在哪里。
- binary_search:一个排序的区间内是否存在一个特定的值。
- lower_bound:返回一个迭代器,或者指向第一个满足条件的元素,或者指向适合于该值插入的位置。切记lower_bound是基于等价性的,用相等性来比较lower_bound的返回值和目标元素是存在潜在风险的。
- upper_bound:返回一个迭代器,指向最后一个满足条件元素的后面一个元素。
- equal_range:返回一对迭代器,第一个指向lower_bound的返回值,第二个指向upper_bound的返回值。如果两个返回值指向同一位置,则说明没有符合条件的元素。Lower_bound与upper_bound的distance可以求得符合条件的元素的个数。
对于multi容器来说,find并不能保证找出的元素是第一个具有此值的元素。如果希望找到第一个元素,必须通过lower_bound,然后在通过等价性的验证。Equal_range是另外一种方式,而且可以避免等价性测试,只是equal_range的开销要大于lower_bound。
下表总结了在什么情况下使用什么样的算法或成员函数
条款46:考虑使用函数对象代替函数作算法的参数
函数对象优于函数的第一个原因在于函数对象的operator方法可以被优化为内联函数,从而使的函数调用的开销在编译器被消化。而编译器并没有将函数指针的间接调用在编译器进行优化,也就是说,函数作为STL算法的参数相对于函数对象而言,具有函数调用的开销。
第二个理由是某些编译器对于函数作为STL的参数支持的并不好。
第三个理由是有助于避免一些微妙的、语言本身的缺陷。比如说实例化一个函数模板,可能会与其他已经预定义的函数产生冲突。
条款47:避免产生“直写型”(write-only)的代码
“只写代码”指的是容易写,但很难读和理解的代码。举例:
假设有一个vector<int>,要去掉vector中值小于x而出现在至少和y一样大的最后一个元素之后的所有元素。下面代码立刻出现在你脑中吗?
v.erase(remove_if(find_if(v.rbegin(),v.rend(),bind2nd(greater_equaql<int>(),y)).base()),v.end(),bind2nd(less<int>(),x));
比较易读的写法最好是这样的
// 初始化range_begin,使它指向v中大于等于y的最后一个元素之后的那个元素 // 如果不存在这样的元素,则rangeBegin被初始化为v.begin() // 如果这个元素恰好是v的最后一个元素,则range_begin将被初始化为v.end() VecIt rangeBegin = find_if(v.rbegin(),v.rend(),bind2nd(greater_equal<int>(),y)).base(); // 从rangeBegin到v.end()的区间中,删除所有小于x的值 v.erase(remove_if(rangeBegin,v.end(),bind2nd(less<int>(),x)),v.end());
条款48:总是include正确的头文件
与STL头文件相关的一些总结
- 几乎所有的STL容器都被声明在与之同名的头文件之中
- 除了accumulate、inner_product、adjacent_difference和partial_sum被声明在<numeric>中之外,其他都所有算法都声明在<algorithm>中
- 特殊类型的迭代器,例如isteam_iterator和istreambuf_iterator,都被声明在<iterator>中
- 标准的函数子,比如less<T>,和函数子配接器,比如not1、bind2nd都被声明在<functional>中。
条款49:学会分析与STL相关的编译器诊断信息
STL的编译错误信息往往冗长而且难以阅读,通过文本替换将复杂的容器名称替换为简单的代号,可以使得错误信息得到简化。
例如,将std::basic_string<char, std::char_traits<char>, std::allocator<char>>替换为可读性更强的string。
下面列举一些常见的STL错误,以及可能的出错原因
- Vector和string的迭代器通常就是指针,当错误的使用iterator的时候,编译器的错误信息中可能会包含指针类型的错误。
- 如果诊断信息提到了back_insert_iterator, front_insert_iterator和insert_iterator,则几乎意味着程序中直接或间接地调用了back_inserter, front_inserter或者是inserter。
- 输出迭代器以及inserter函数返回的迭代器在赋值操作符内部完成输入或者插入操作,如果有赋值操作符有关的错误信息,可以关注这些迭代器。
- 如果错误信息来自于算法的内部实现,往往意味着传递给算法的对象使用了错误的类型。
- 如果在使用一个常见的STL组件,但编译器却不认知,可能是没有包含合适的头文件。
条款50:熟悉与STL相关的Web站点
SGI STL http://www.sgi.com/tech/stl
STLport http://www.stlport.org
Boost http://www.boost.org

 浙公网安备 33010602011771号
浙公网安备 33010602011771号