Effective STL 第三部分
条款26:尽量用iterator代替const_iterator,reverse_iterator和const_reverse_iterator
每个标准容器类都提供四种迭代器类型。对于container<T>而言,iterator的作用相当于T*,而const_iterator则相当于const T*;增加一个iterator或者const_iterator可以在一个从容器开头趋向尾部的遍历中让你移动到容器的下一个元素。reverse_iterator与const_reverse_iterator同样相当于对应的T*和const T*,所不同的是,增加reverse_iterator或者const_reverse_iterator会在从尾到头的遍历中让你移动到容器的下一个元素。
迭代器使用的一个重要指导方针是:尽量使用iterator代替其他三种迭代器,原因有:
- insert和erase的一些版本要求iterator。如果你需要调用这些函数,你就必须产生iterator,而不能用const或reverse iterators。
- 不能把const_iteraotor隐式转换为iterator。
它们之间相互转换

从iterator到const_iterator和reverse_iterator存在隐式转换,从reverse_iterator到const_iterator也存在隐式转换。
通过base()可以将reverse_iterator转换为iterator,同样可以将const_reversse_iterator转换为const_iterator,但是转换后的结果并不指向同一元素(有一个偏移量)
条款27:用distance和advance把const_iterator转化成iterator
对于大多数的容器,const_cast并不能将const_iterator转换为iterator。即使在某些编译器上可以将vector和string的const_iterator转换为iterator,但存在移植性的问题
以下操作是不可以的
1 typedef deque<int> IntDeque; // 方便的typedef 2 3 typedef IntDeque::iterator Iter; 4 5 typedef IntDeque::const_iterator ConstIter; 6 7 ConstIter ci; // ci是const_iterator 8 9 ... 10 11 Iter i(ci); // 错误!没有从const_iterator 到iterator隐式转换的途径 12 13 Iter i(const_cast<Iter>(ci));
// 仍是个错误!不能从const_iterator映射为iterator!
正确的做法如下:
通过distance和advance将const_iterator转换为iterator的方法
typedef deque<int> IntDeque; // 和以前一样 typedef IntDeque::iterator Iter; typedef IntDeque::const_iterator ConstIter; IntDeque d; ConstIter ci; ... // 让ci指向d Iter i(d.begin()); // 初始化i为d.begin() advance(i, distance <ConstIter> (i, ci)); // 把i移到指向ci位置
注:distance返回两个指向同一个容器的iterator之间的距离;advance则用于将一个iterator移动指定的距离。如果i和ci指向同一个容器,那么表达式advance(i, distance(i, ci))会将i移动到与ci相同的位置上。
条款28:了解如何通过reverse_iterator的base得到iterator
使用reverse_iterator的base()成员函数所产生的iterator和原来的reverse_iterator之间有一个元素的偏移量。

容器的插入、删除和修改操作都是基于iterator的,所以对于reverse_iterator,必须通过base()成员函数转换为iterator之后才能进行增删改的操作。
- 对于插入操作而言,新插入的元素都在3和4之间,所以可以直接使用insert(ri.base(),xxx)
- 对于修改和删除操作,由于ri和ri.base()并不指向同一元素,所以在修改和删除前,必须修正偏移量
set<Widget> s; typedef set<Widget>::reverse_iterator RIter; RIter ri; ... //使ri指向v中的元素 s.erase(--ri.base());
//直接修改函数返回的指针不能被直接修改。 如果iterator是基于指针实现的,代码将不具有可以执行。 s.erase((++ri).base()); //具备可移植行的代码
条款29:对于逐个字符的输入请考虑使用istreambuf_iterator
常用的istream_iterator内部使用的operator>>实际上执行了格式化的输入,每一次的operator>>操作都有很多的附加操作
- 一个内部sentry对象的构造和析构(设置和清理行为的对象)
- 检查可能影响行为的流标志(比如skipws)
- 检查可能发生的读取错误
- 出现错误时检查流的异常屏蔽标志以决定是否抛出异常
对于istreambuf_iterator,它直接从流的缓冲区中读取下一个字符,不存在任何的格式化,所以效率相对istream_iterator要高得多。
对于非格式化的输出,也可以考虑使用ostreambuf_iterator代替ostream_iterator。(损失了格式化输出的灵活性)
条款30:确保目标区间足够大
注意:可以通过back_inserter或者front_inserter来实现在头尾插入另一个容器中的元素。因为front_inserter的实现是基于push_front操作(vector和string不支持push_front),所以通过front_inserter插入的元素与他们在原来容器中的顺序正好相反,这个时候可以使用reverse_iterator。
把transform的结果放入叫做results容器的结尾”的正确方法是调用back_inserter来产生指定目标区间起点的迭代器:
int transformogrify(int x);//将x值做一些处理,返回一个新的值
vector<int> values;
vector<int> results; transform(values.begin(), values.end(), back_inserter(results), transmogrify);
////把transmogrify应用于values中的每个对象, 在results的结尾插入返回的values 同样,将结果插到results容器的前面采用的方法是: ... // 同上 list<int> results; transform(values.begin(), values.end(), front_inserter(results),transmogrify);
//// results现在是list在results前端 以反序插入transform的结果
另外可以使用insert 在results的任意位置插入位置
int transformogrify(int x); //将x值做一些处理,返回一个新的值 vector<int> values; vector<int> results; ... //初始化values transform(values.begin(),values.end(),inserter(results,results.begin()+results.size()/2),transformogrify); //插入中间
如果插入操作的目标容器是Vector 或者string, 可以通过reserve操作来避免不必要的容器内存重新分配。
int transformogrify(int x); //将x值做一些处理,返回一个新的值 vector<int> values; vector<int> results; //... //初始化values results.reserve(values.size()+results.size()); //预留results和values的空间 transform(values.begin(),values.end(),back_inserter(results),transformogrify);
更高效的方法是:
vector<int> values; // 同上 vector<int> results; results.reserve(results.size() + values.size()); // 同上 transform(values.begin(), values.end(), back_inserter(results), transmogrify); // 把transmogrify的结果 写入results的结尾,处理时避免了重新分配
条款31:了解你的排序选择
(1) 如果你需要在vector、string、deque或数组上进行完全排序,你可以使用sort或stable_sort。
vector<int> values; values.push_back(4); values.push_back(1); values.push_back(2); values.push_back(5); values.push_back(3); sort(values.begin(),values.end()); // 1,2,3,4,5
对vector、string、deque或数组中的元素选出前n个进行并对这n个元素进行排序,可以使用partial_sort
partial_sort(values.begin(),values.begin()+2,values.end());
// 1,2,4,5,3 注意第二个参数是一个开区间
对vector、string、deque或数组中的元素,要求找到按顺序排在第n个位置上的元素,或者找到排名前n的数据,但并不需要对这n个数据进行排序,这时可以使用nth_element
nth_element(values.begin(),values.begin()+1,values.end());
// 1,2,3,4,5 注意第二个参数是一个闭区间
这个返回的结果跟我期望的有些差距,期望的返回值应该是1,2,4,5,3。VC10编译器
(2) 如果你有一个vector、string、deque或数组,你只需要排序前n个元素,应该用partial_sort。
(3) 如果你有一个vector、string、deque或数组,你需要鉴别出第n个元素或你需要鉴别出最前的n个元素,而不用知道它们的顺序,nth_element是你应该注意和调用的。
(4) 如果你需要把标准序列容器的元素或数组分隔为满足和不满足某个标准,你大概就要找partition或stable_partition。
(5) 如果你的数据是在list中,你可以直接使用partition和stable_partition,你可以使用list的sort来代替sort和stable_sort。如果你需要partial_sort或nth_element提供的效果,你就必须间接完成这个任务,主要有三种方法:
vector<int>::iterator firstIteratorNotLessThan3 = partition(values.begin(),values.end(),lessThan3);
//返回值为 2,1,4,5,3 vector<int>::iterator firstIteratorNotLessThan3 = stable_partition(values.begin(),values.end(),lessThan3);
//返回值为 1,2,4,5,3
[1] 把元素拷贝到一个支持随机访问迭代器的容器中,然后对它应用需要的算法。
[2] 另一个方法是建立一个list::iterator的容器,对那个容器使用算法,然后通过迭代器访问list元素。
[3]使用有序的迭代器容器的信息来迭代地把list的元素接合到你想让它们所处的位置
条款32:如果你真的想删除东西的话就在类似remove的算法后接上erase
先看一个错误的实例:vector<int> v; // 建立一个vector<int> 用1-10填充它 v.reserve(10); for (int i = 1; i <= 10; ++i)
{ v.push_back(i); } cout << v.size(); // 打印10 v[3] = v[5] = v[9] = 99; // 设置3个元素为99 remove(v.begin(), v.end(), 99); // 删除所有等于99的元素 cout << v.size(); // 仍然是10!
从上面的代码可见,remove并没有删除所有值为99的元素,只不过是用后面元素的值覆盖了需要被remove的元素的值,并一一填补空下来的元素的空间,对于最后三个元素,并没有其他的元素去覆盖他们的值,所以仍然保留原值
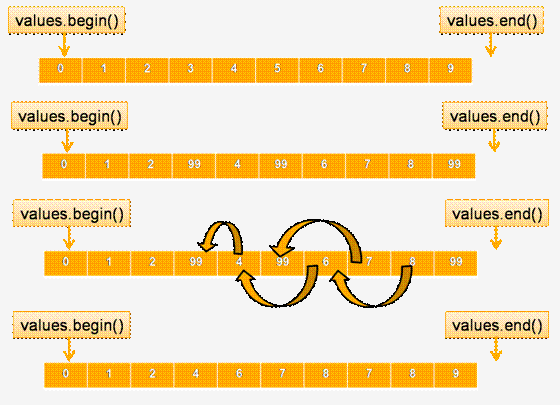
图可以看出,remove只不过是用后面的值填补了空缺的值,但并没有将容器中的元素删除,所以在remove之后,要调用erase将不需要的元素删除掉。
正确的删除元素的方法是:
vector<int> v; // 正如从前 v.erase(remove(v.begin(), v.end(), 99), v.end()); // 真的删除所有等于99的元素 cout << v.size(); // 现在返回7
需要注意的是remove和erase是亲密联盟,这两个整合到list成员函数remove中。这是STL中唯一名叫remove又能从容器中除去元素的函数:
类似于remove的算法还有remove_if和unique, 这些算法都没有真正的删除元素,习惯用法是将它们作为容器erase成员函数的第一个参数。
List是容器中的一个例外,它有remove和unique成员函数,而且可以从容器中直接删除不需要的元素。
list<int> li; // 建立一个list // 放一些值进去 li.remove(99); // 除去所有等于99的元素:真的删除元素,所以它的大小可能改变了 remove_if ,unique和remove类似,都需要跟erase连用才可以真正删除数据,同样,
对于list是个特殊。
条款33:提防在指针的容器上使用类似remove的算法
该条款是对条款32的补充,采用remove/erase方式删除指针容器中的数据会造成内存泄漏,如:
class Widget{ public: ... bool isCertified() const; // 这个Widget是否通过检验 ... }; vector<Widget*> v; // 建立一个vector然后用动态分配的Widget v.push_back(new Widget); // 的指针填充 v.erase(remove_if(v.begin(), v.end(), not1(mem_fun(&Widget::isCertified))),v.end());
// // 删除未通过检验的 Widget指针
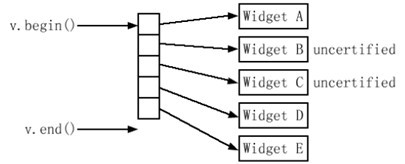
Widget C和Widget B的内存不会被释放,造成内存泄漏,正确的方法有两种:
(1)在应用erase-remove惯用法之前先删除指针并设置它们为空,然后除去容器中的所有空指针:
void delAndNullifyUncertified(Widget*& pWidget) // 如果*pWidget是一个 { // 未通过检验Widget, if (!pWidget->isCertified()) { // 删除指针 delete pWidget; // 并且设置它为空 pWidget = 0; } } for_each(v.begin(), v.end(), delAndNullifyUncertified);
// 把所有指向未通过检验Widget的指针删除并且设置为空 v.erase(remove(v.begin(), v.end(), static_cast<Widget*>(0)), v.end());
////// 从v中除去空指针 0必须映射到一个指针, 让C++可以正确地推出remove的第三个参数的类型
(2)采用智能指针,如boost库中的shared_ptr和scoped_ptr
条款34:注意哪个算法需要有序区间
STL中只能操作有序数据(升序)的算法有:
(1) binary_search:二分查找
(2) lower_bound:下界
(3) upper_bound:上街
(4) equal_range:所有等于某个值的元素
(5) set_union:集合并集
(6) set_intersection:集合交集
(7) set_difference :集合差集
(8) set_symmetric_difference:包含在第一个集合但是不包含在第二个集合中的元素,包含在第2个集合但是不包含在第1个集合中的元素
(9) merge:合并两个有序表
(10) inplace_merge:合并两个有序表
(11) includes:检测一个区间的所有对象是否在另一个区间中
另外,下面的算法一般用于有序区间,虽然它们不要求:
(12) unique:去重,相同的元素必须紧挨着,排序是个特例
(13) unique_copy:同上
条款35:通过mismatch或lexicographical比较实现简单的忽略大小写字符串比较
实现忽略大小写字符串比较有两种方法,
一种是使用mismatch函数:
第二种时使用lexicographical函数:
条款36:了解copy_if的正确实现
STL有很多有趣的地方,其中一个是虽然有11个名字带“copy”的算法:
(1) copy
(2) copy_backward
(3) replace_copy
(4) reverse_copy
(5) replace_copy_if
(6) unique_copy
(7) remove_copy
(8) rotate_copy
(9) remove_copy_if
(10) partial_sort_copy
(11) unintialized_copy
但没有一个是copy_if,这需要自己实现,非常经典的一个实现是:
template<typename InputIterator, typename OutputIterator, typename Predicate> OutputIterator copy_if(InputIterator begin,InputIterator end,OutputIterator destBegin,Predicate p) // // 一个copy_if的正确实现 { while (begin != end) { if (p(*begin)) *destBegin++ = *begin; ++begin; } return destBegin; }
条款37:用accumulate或for_each来统计区间
本条款总结了用自定义的方式统计(summarize)区间的方法,主要有两种(在头文件<numeric>中):
(1) accumulate存在两种形式:第一种是: 带有一对迭代器和初始值的形式,它可以返回初始值加由迭代器划分出的区间中值的和:
list<double> ld; // 建立一个list ... // 放一些double进去 double sum = accumulate(ld.begin(), Id.end(), 0.0); // 计算它们的和,从0.0开始
注意初始值指定为0.0,0.0的类型是double,所以accumulate内部使用了一个double类型的变量来存储计算的和。如果这么写这个调用:
double sum = accumulate(ld.begin(), Id.end(), 0); // 计算它们的和,从0开始;
初始值是int 0,所以accumulate内部就会使用一个int来保存它计算的值,这是不正确的,因为每次加法后会将结果转换为一个int,这造成小数点后面的数值丢失。
另一种形式带有一个初始和值与一个任意的统计函数,实例:
string::size_type // string::size_type的内容 stringLengthSum(string::size_type sumSoFar, const string& s)// 请看下文 { return sumSoFar + s.size(); } set<string> ss; // 建立字符串的容器, ... // 进行一些操作 string::size_type lengthSum = accumulate(ss.begin(), ss.end(), 0, stringLengthSum);
// // // 把lengthSum设为对ss中的每个元素调用stringLengthSum的结果,使用0作为初始统计值
(2) for_each,带有一个区间和一个函数(一般是一个函数对象)来调用区间中的每个元
素,但传给for_each的函数只接收一个实参(当前的区间元素),而且当完成时for_each返回它的函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号