Effective STL 第一部分
条款1:仔细选择你的容器
C++提供了很多可供程序员使用的容器:
- 标准STL序列容器:vector,string,deque和list
- 标准STL关联容器:set,multiset,map和multimap
- 非标准序列容器slist(单链表)和rope(重型字符串)
- 非标准关联容器hash_set,hash_multiset,hash_map和hash_multimap
- vector<char>可以作为string的替代品
- vector作为标准关联容器的替代品
- 几种标准非STL容器,包括数组、bitset、valarray、stack、queue和priority_queue
建议:vector是一种可以默认使用的序列类型,当很频繁地对序列中部进行插入和删除时应该用list,当大部分插入和删除发生在序列的头或尾时可以选择deque这种数据结构。
如何选择合适的STL容器
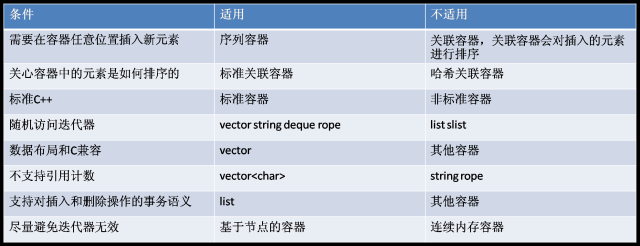
不要编写试图独立于容器的代码
- 数组被泛化为以其所包含对象的类型为参数的容器
- 函数被泛化为以其使用的迭代器的类型为参数的算法
- 指针被泛化为以其所指向的对象的类型为参数的迭代器
有人想编写这样的程序,刚开始时使用vector存储,之后由于需求的变化,将vector改为deque或者list,其他代码不变。实际上,这基本上是做不到的。这是因为:不同的序列容器所对应了不同的迭代器、指针和引用的失效规则,此外,不同的容器支持的操作也不相同,如:vector支持reserve()和capacity(),而deque和list不支持;即使是相同的操作,复杂度也不一样(如:insert),这会让你的系统产生意想不到的瓶颈。
typedef 的好处:
class Widget {}; template<typename T> SpecilAllocator { ... }; typedef vector<Widget, SpecilAllocator<Widget>> WidgetContainer; WidgetContainer cw;
条款2:确保容器里对象的拷贝操作轻量而正确
STL的工作方式是Copy In, Copy Out,也就是说在STL容器中的插入对象和读取对象,使用的都是对象的拷贝。在存放基类对象的容器中存放子类的对象,当容器内的对象发生拷贝时,会发生截断(剥离 slicing)。
容器容纳了对象,但不是你给他们的那个对象。当你像容器中插入一个对象时,你插入的对象时该对象的拷贝而不是它本身,当你从容器获取一个对象时,你获取的是容器中对象的拷贝。
拷贝是STL的基本工作方式。当你删除或者插入某个对象时,现有容器中的元素会移动(拷贝);当你使用了排序算法,remove、uniquer或者他们的同类,rotate或者reverse,对象会移动(拷贝)。
一个使拷贝更高效、正确的方式是建立指针的容器而不是对象的容器,即保存对象的指针而不是对象,然而,指针的容器有它们自己STL相关的头疼问题,改进的方法是采用智能指针。
vector<Widget> vw; class SpecialWidget : public Widget { ... }; SpecialWidget sw; vw.push_back(sw);
正确的方法是使容器包含指针而非对象
vector<Widget*> vw; class SpecialWidget : public Widget { ... }; SpecialWidget sw; vw.push_back(&sw);
容器与数组在数据拷贝方面的对比:
当创建一个包含某类型对象的一个数组的时候,总是调用了次数等于数组长度的该类型的构造函数。尽管这个初始值之后会被覆盖掉
Widget w[maxNumWidgets]; //maxNumWidgets 次的Widget构造函数
如果使用vecor,效率会有所提升。
vector<widget> w; //既不调用构造函数也不调用拷贝构造函数 vector<widget> w(5); //1次构造 5次拷贝构造 vector<widget> w; //既不调用构造函数也不调用拷贝构造函数 w.reserve(5); //既不调用构造函数也不调用拷贝构造函数 vector<widget> w(5); //1次构造 5次拷贝构造 w.reserve(6); //需要移动位置,调用5次拷贝构造
条款3:调用empty()而不是检查size()是否为0
empty()对于所有标准容器都是常数时间,而对list操作,size()耗费线性时间。list具有常数时间的Splice操作,如果在两个list之间做链接的时候需要记录被链接到当前list的节点的个数,那么Splice操作将会变成线性时间。对于list而言,用户对Splice效率的要求高于取得list长度的要求,所以list的size()需要耗费线性的时间去遍历整个list。所以,调用empty()是判断list是否为空的最高效方法。
对于任意容器c,写下 if (c.size() == 0)… 本质上等价于写下 if (c.empty())…
但是为什么第一种方式没有第二种优呢?理由很简单:对于所有的标准容器,
empty是一个常数时间的操作,但对于一些list实现,size花费线性时间。
为什么不能也提供一个常数时间的size呢?答案是对于list特有的splice有很多要处理
的东西。考虑这段代码:
list<int> list1; list<int> list2; ... list1.splice( // 把list2中 list1.end(), list2, // 从第一次出现5到 find(list2.begin(), list2.end(), 5), // 最后一次出现10 find(list2.rbegin(), list2.rend(), 10).base() // 的所有节点移到list1的结尾。 ); // 关于调用的 // "base()"的信息,请参见 条款28
关注
于这个问题:接合后list1有多少元素?很明显,接合后list1的元素个数等于接合之前list1的元素
个数加上接合进去的元素个数。但是有多少元素接合进去了?那等于由find(list2.begin(),
list2.end(), 5)和find(list2.rbegin(),list2.rend(), 10).base()
所定义的区间的元素个数。


如果size是一个常数时间操作,当操作时每个list成员函数必须更新list的大小。也包括了
splice。但让区间版本的splice更新它所更改的list大小的唯一的方法是算出接合进来的元素的个数,但那么做就会使它不可能有你所希望的常数时间的性能。如果你去掉了splice的区间形式要更新它所修改的list的大小的需求,splice就可以是常数时间,但size就变成线性时间的操作。一般来说,它必须遍历它的整个数据结构来才知道它包含多少元素。不管你如何看待它,有的东西——size或splice的区间形式——必须让步。一个或者另一个可以是常数时间操作,但不能都是。
条款4:尽量使用区间成员函数代替单元素操作
给定两个vector,v1和v2,怎样使v1的内容和v2的后半部分一样?
可行的解决方案有:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 |
(1) 使用区间函数assign:
v1.assign(v2.begin() + v2.size() / 2, v2.end()); (2) 使用单元素操作: vector<Widget>::const_iterator ci = v2.begin() + v2.size() / 2; while(ci != v2.end()) { v1.push_back(*ci); ++ci; } (3)使用copy区间函数 v1.clear(); copy(v2.begin() + v2.size() / 2, v2.end(), back_inserter(v1)); (4) 使用insert区间函数 v1.insert(v1.end(), v2.begin() + v2.size() / 2, v2.end()); |
最优的方案是assign方案,理由如下:
首先,使用区间函数的好处是:
● 一般来说使用区间成员函数可以输入更少的代码。
● 区间成员函数会导致代码更清晰更直接了当。
使用copy区间函数存在的问题是:
【1】 需要编写更多的代码,比如:v1.clear(),这个与insert区间函数类似
【2】 copy没有表现出循环,但是在copy中的确存在一个循环,这会降低性能
使用insert单元素版本的代码对你征收了三种不同的性能税,分别为:
【1】 没有必要的函数调用;
【2】 无效率地把v中的现有元素移动到它们最终插入后的位置的开销;--避免频繁地元素移动;
【3】 重复使用单元素插入而不是一个区间插入必须处理内存分配---避免多次进行内存分配
下面进行总结:
说明:参数类型iterator表示容器的迭代器类型,也就是container::iterator,参数类型InputIterator表示可以接受任何输入迭代器。
【1】 区间构造
所有标准容器都提供这种形式的构造函数:
1 container::container(InputIterator begin, // 区间的起点 2 3 InputIterator end); // 区间的终点
【2】 区间插入
所有标准序列容器都提供这种形式的insert:
1 void container::insert(iterator position, // 区间插入的位置 2 3 InputIterator begin, // 插入区间的起点 4 5 InputIterator end); // 插入区间的终点
关联容器使用它们的比较函数来决定元素要放在哪里,所以它们了省略position参数。
void container::insert(lnputIterator begin, InputIterator end);
【3】 区间删除
每个标准容器都提供了一个区间形式的erase,但是序列和关联容器的返回类型不同。序列容器提供了这个:
iterator container::erase(iterator begin, iterator end);
而关联容器提供这个:
void container::erase(iterator begin, iterator end);
为什么不同?解释是如果erase的关联容器版本返回一个迭代器(被删除的那个元素的下一个)会招致一个无法接受的性能下降.
【4】 区间赋值
所有标准列容器都提供了区间形式的assign:
void container::assign(InputIterator begin, InputIterator end);
条款6:警惕C++最令人恼怒的解析
假设你有一个int的文件,你想要把那些int拷贝到一个list中。这看起来像是一个合理的方式:
ifstream dataFile("ints.dat"); list<int> data(istream_iterator<int>(dataFile), istream_iterator<int>()); //此处有歧义-详解请点击
// 编译器会做出这样的解释:声明了一个返回值为list<int>的函数data,该函数有两个参数,
一个是istream_iterator<int>类型的变量,另一个是返回值为istream_iterator<int>类型的无参函数指针。
//这段代码可以编译通过,但运行时不会产生任何结果。仔细分析后,会发现,你这段代码实际上是声明了一个data函数,
它的返回值是list<int>,两个参数均为istream_iterator<int>类型
最好的方式是使用命名的迭代器。尽管这与通常的STL风格相违背,但是消除了编译器的二义性而且增强了程序的可读性。
1 ifstream dataFile("ints.dat"); 3 istream_iterator<int> dataBegin(dataFile); 5 istream_iterator<int> dataEnd; 7 list<int> data(dataBegin, dataEnd);
条款7:当使用new得指针的容器时,记得在销毁容器前delete那些指针
STL容器在析构之前,会将其所包含的对象进行析构。
class widget { ... }; doSth() { widget w; //一次构造函数 vector<widget> v; v.push_back(w); //一次拷贝构造函数 } // 两次析构函数
但如果容器中包含的是指针的话,一旦没有特别将指针delete掉将会发生内存泄漏
class widget { ... }; doSth() { widget* w = new widget(); vector<widget*> v; v.push_back(w); } // memory leak!!!
最为方便并且能够保证异常安全的做法是将容器所保存的对象定义为带有引用计数的智能指针
class widget { ... }; doSth() { shared_ptr<widget> w(new widget()); //构造函数一次 vector<shared_ptr<widget>> v; v.push_back(w); } //析构函数一次 没有内存泄漏
第八条:切勿创建包含auto_ptr对象的容器
由于auto_ptr对于其"裸指针"必须具有独占性,当将一个auto_ptr的指针赋给另一个auto_ptr时,其值将被置空。
1 auto_ptr<int> p1(new int(1)); // p1 = 1 2 auto_ptr<int> p2(new int(2)); // p2 = 2 3 4 p2 = p1; // p2 = 1 p1 = emtpy;
第三条提到STL容器中的插入对象和读取对象,使用的都是对象的拷贝,并且基于STL容器的算法也通常需要进行对象的copy,所以,创建包含auto_ptr的容器是不明智的。
第九条:慎重选择删除元素的方法
(1)假定你有一个标准STL容器,c,容纳int,
Container<int> c;
而你想把c中所有值为1963的对象都去,则不同的容器类型采用的方法不同:没有一种是通用的.
[1] 如果采用连续内存容器(vector、queue和string),最好的方法是erase-remove惯用法:
1 c.erase(remove(c.begin(), c.end(), 1963),c.end());
//当c是vector、string 或deque时,erase-remove惯用法是去除特定值的元素的最佳方法
[2] 对于list,最有效的方法是直接使用remove函数:
c.remove(1963);
[3] 对于关联容器,解决问题的适当方法是调用erase:
c.erase(1963); // 当c是标准关联容器时,erase成员函数是去除特定值的元素的最佳方法
(2)让我们换一下问题:不是从c中除去每个有特定值的元素,而是消除下面判断式返回真的每个对象:
bool badValue(int x); // 返回x是否是“bad”
[1] 对于序列容器(vector、list、deque和string),只需要将remove换成remove_if即可:
c.erase(remove_if(c.begin(), c.end(), badValue), c.end());
c.remove_if(badValue);
// 当c是vector、string或deque时这是去掉badValue返回真的对象的最佳方法,
//当c是list时这是去掉badValue返回真的对象的最佳方法
[2] 对于关联容器,有两种方法处理该问题,一个更容易编码,另一个更高效。“更容易但效率较低”的解决方案用remove_copy_if把我们需要的值拷贝到一个新容器中,然后把原容器的内容和新的交换:
AssocContainer<int> c; // c现在是一种标准关联容器 AssocContainer<int> goodValues; // 用于容纳不删除的值的临时容器 remove_copy_if(c.begin(), c.end(), inserter(goodValues,goodValues.end()), badValue);
//从c拷贝不删除的值到goodValues c.swap(goodValues); // 交换c和goodValues的内容
“更高效”的解决方案是直接从原容器删除元素。不过,因为关联容器没有提供类似remove_if的成员函数,所以我们必须写一个循环来迭代c中的元素,和原来一样删除元素:
AssocContainer<int> c; ... for (AssocContainer<int>::iterator i = c.begin(); i != c.end(); ) //for循环的第三部分是空的;i现在在下面/*nothing*/ { // 自增 if (badValue(*i))
c.erase(i++); // 对于坏的值,把当前的i传给erase,然后作为副作用增加i;对于好的值,只增加i else
++i; // }
(3)进一步丰富该问题:不仅删除badValue返回真的每个元素,而且每当一个元素被删掉时,我们也想把一条消息写到日志文件中。
[1] 对于关联容器,只需要对我们刚才开发的循环做一个微不足道的修改就行了:
ofstream logFile; // 要写入的日志文件 AssocContainer<int> c; ... for (AssocContainer<int>::iterator i = c.begin(); i !=c.end();)// 循环条件和前面一样 { if (badValue(*i)) { logFile << "Erasing " << *i <<'\n'; // 写日志文件 c.erase(i++); // 删除元素 } else ++i; }
[2] 对于vector、string、list和deque,必须利用erase的返回值。那个返回值正是我们需要的:一旦删除完成,它就是指向紧接在被删元素之后的元素的有效迭代器。换句话说,我们这么写:
for (SeqContainer<int>::iterator i = c.begin();i != c.end();) { if (badValue(*i)) { logFile << "Erasing " << *i << '\n'; i = c.erase(i); // 通过把erase的返回值赋给i来保持i有效 } else ++i; }
条款10:注意分配器的协定和约束
如果需要编写自定义的分配子,有以下几点需要注意
- 当分配子是一个模板,模板参数T代表你为其分配内存的对象的类型
- 提供类型定义pointer和reference,始终让pointer为T*而reference为T&
- 不要让分配子拥有随对象而不同的状态,通常,分配子不应该有非静态数据成员
- 传递给allocator的是要创建元素的个数而不是申请的字节数,该函数返回T*,尽管此时还没有T对象构造出来
- 必须提供rebind模板,因为标准容器依赖于该模板
条款11:理解自定义分配子的合理用法
如果需要在共享的内存空间中手动的管理内存分配,下列代码提供了一定的参考
//用户自定义的管理共享内存的malloc和free void* mallocShared(size_t bytesNeeded); void* freeShared(void* ptr); template<typename T> class sharedMemoryAllocator { public: ... point allocator(size_type numObjects, const void* localityHint=0) { return static_cast<pointer>(mallocShared(numObjects*sizeof(T))); } void deallocate(pointer ptrMemory, size_type numObjects) { freeShared(ptrMemory); } ... }
如果不仅仅是将容器的元素放在共享内存,而且要将容器对象本身也放在共享内存中,参考如下代码
void* ptrVecMemory = mallocShared(sizeof(SharedDoubleVec)); SharedDoubleVec* sharedVec = new(ptrVecMemory) SharedDoubleVec; ... sharedVec->~SharedDoubleVec(); freeShared(sharedVec);
条款12:切勿对STL容器的线程安全性有不切实际的依赖
当设计线程安全和STL容器时,你可以确定库实现了“允许”在一个容器上的多读者“(在读取时不能有任何写入者操作这个容器)
和”不同容器上多个写者“--即多个线程可以写不同的容器。
- 对于STL容器的多线程读时安全的。
- 多余多个不同的STL容器
采用面向对象的方式对STL容器进行加锁和解锁
template<typename Container> class lock { public: Lock(const Container& container):c(container) { getMutexFor(c); } ~Lock() { releaseMutex(c); } private: Container& c; },
vector<int> v; ... { Lock<vector<int>> lock(v); //构造lock,加锁v doSthSync(v); //对v进行多线程的操作 } //析构lock,解锁v

 浙公网安备 33010602011771号
浙公网安备 33010602011771号