读书笔记三:TCP/IP详解之IP网际协议
IP协议
IP协议是TCP/IP协议的核心,IP提供的是不可靠,无连接的数据报传递服务。
不可靠是说它不能保证IP数据报能成功地到达目的地,它仅提供最好的传输服务。可靠性必须由上层来提供。
无连接则是说IP并不维护任何关于后续数据报的状态信息,每个数据报都是独立的。所以IP数据报可以不按序接收,每个数据报独立地进行路由。
所有的TCP,UDP,IMCP,IGCP的数据都以IP数据格式传输。要注意的是,IP不是可靠的协议,这是说,IP协议没有提供一种数据未传达以后的处理机制--这被认为是上层协议--TCP或UDP要做的事情。所以这也就出现了TCP是一个可靠的协议,而UDP就没有那么可靠的区别。这是后话,暂且不提。
IP首部
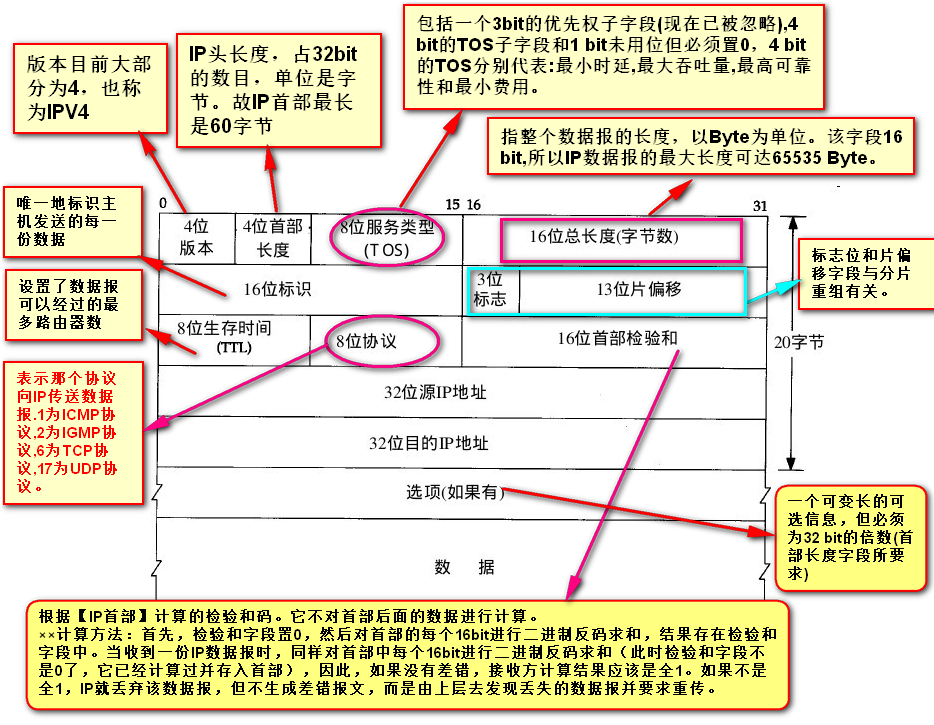
普通的IP首部为20字节。除非包含选项字段。
网络字节序? TCP/IP 首部中的所有二进制整数在网络中传输都要求这种字节序。
——4个字节的32bit值的传输顺序:0~7bit,8~15bit,16~23bit,24~31bit。
详细介绍IP头字段
版本
目前大部分为4,也称为IPV4。标识目前采用的IP协议的版本号。一般的值为0100(IPv4),0110(IPv6)
IP包头长度
指长度4比特。这个字段的作用是为了描述IP包头的长度,因为在IP包头中有变长的可选部分。该部分占4个bit位,单位为32bit(4个字节),即本区域值= IP头部长度(单位为bit)/(8*4),因此,一个IP包头的长度最长为“1111”,即15*4=60个字节。IP包头最小长度为20字节。
服务类型(TOS)字段
包括一个3bit的优先权子字段(现在已被忽略),4 bit的TOS子字段和1 bit未用位但必须置0,4 bit的TOS分别代表:最小时延,最大吞吐量,最高可靠性和最小费用。
长度8比特。8位 按位被如下定义 PPP DTRC0
PPP:定义包的优先级,取值越大数据越重要
000 普通 (Routine)
001 优先的 (Priority)
010 立即的发送 (Immediate)
011 闪电式的 (Flash)
100 比闪电还闪电式的 (Flash Override)
101 CRI/TIC/ECP(找不到这个词的翻译)
110 网间控制 (Internetwork Control)
111 网络控制 (Network Control)
D 时延: 0:普通 1:延迟尽量小
T 吞吐量: 0:普通 1:流量尽量大
R 可靠性: 0:普通 1:可靠性尽量大
M 传输成本: 0:普通 1:成本尽量小
0 最后一位被保留,恒定为0
16位总长度字段
指整个数据报的长度,以Byte为单位。该字段16 bit,所以IP数据报的最大长度可达65535 Byte。
标识字段
唯一地标识主机发送的每一份数据,标识数据报的序号,由发送者设置,接收者可以根据此标识重组数据报。长度16比特。该字段和Flags和Fragment Offest字段联合使用,对较大的上层数据包进行分段(fragment)操作。路由器将一个包拆分后,所有拆分开的小包被标记相同的值,以便目的端设备能够区分哪个包属于被拆分开的包的一部分。
标志位
长度3比特。该字段第一位不使用。第二位是DF(Don't Fragment)位,DF位设为1时表明路由器不能对该上层数据包分段。如果一个上层数据包无法在不分段的情况下进行转发,则路由器会丢弃该上层数据包并返回一个错误信息。第三位是MF(More Fragments)位,当路由器对一个上层数据包分段,则路由器会在除了最后一个分段的IP包的包头中将MF位设为1。
片偏移字段
长度13比特。表示该IP包在该组分片包中位置,接收端靠此来组装还原IP包。
TTL(time-to-live)生存时间
字段设置了数据报可以经过的最多路由器数。长度8比特。当IP包进行传送时,先会对该字段赋予某个特定的值。当IP包经过每一个沿途的路由器的时候,每个沿途的路由器会将IP包的TTL值减少1。如果TTL减少为0,则该IP包会被丢弃。这个字段可以防止由于路由环路而导致IP包在网络中不停被转发。
协议字段
表示那个协议向IP传送数据报协议(Protocol):长度8比特。标识了上层所使用的协议。
以下是比较常用的协议号:
1 ICMP
2 IGMP
6 TCP
17 UDP
88 IGRP
89 OSPF
首部检验和字段
是长度16位。用来做IP头部的正确性检测,但不包含数据部分。 因为每个路由器要改变TTL的值,所以路由器会为每个通过的数据包重新计算这个值。
××计算方法:首先,检验和字段置0,然后对首部的每个16bit进行二进制反码求和,结果存在检验和字段中。当收到一份IP数据报时,同样对首部中每个16bit进行二进制反码求和(此时检验和字段不是0了,它已经计算过并存入首部),因此,如果没有差错,接收方计算结果应该是全1。如果不是全1,IP就丢弃该数据报,但不生成差错报文,而是由上层去发现丢失的数据报并要求重传。
选项字段
是一个可变长的可选信息,但必须为32 bit的倍数(首部长度字段所要求)。
IP地址为32 bit。
起源和目标地址(Source and Destination Addresses)
这两个地段都是32比特。标识了这个IP包的起源和目标地址。要注意除非使用NAT,否则整个传输的过程中,这两个地址不会改变。
可选项(Options)
这是一个可变长的字段。该字段属于可选项,主要用于测试,由起源设备根据需要改写。可选项目包含以下内容:
松散源路由(Loose source routing):给出一连串路由器接口的IP地址。IP包必须沿着这些IP地址传送,但是允许在相继的两个IP地址之间跳过多个路由器。
严格源路由(Strict source routing):给出一连串路由器接口的IP地址。IP包必须沿着这些IP地址传送,如果下一跳不在IP地址表中则表示发生错误。
路由记录(Record route):当IP包离开每个路由器的时候记录路由器的出站接口的IP地址。
时间戳(Timestamps):当IP包离开每个路由器的时候记录时间。
填充(Padding):因为IP包头长度(Header Length)部分的单位为32bit,所以IP包头的长度必须为32bit的整数倍。因此,在可选项后面,IP协议会填充若干个0,以达到32bit的整数倍。
typedef struct _iphdr //定义IP首部 { unsigned char h_lenver; //4位首部长度+4位IP版本号 unsigned char tos; //8位服务类型TOS unsigned short total_len; //16位总长度(字节) unsigned short ident; //16位标识 unsigned short frag_and_flags; //3位标志位 unsigned char ttl; //8位生存时间 TTL unsigned char proto; //8位协议 (TCP, UDP 或其他) unsigned short checksum; //16位IP首部校验和 unsigned int sourceIP; //32位源IP地址 unsigned int destIP; //32位目的IP地址 }IP_HEADER;
IP路由选择
当一个IP数据包准备好了的时候,IP数据包(或者说是路由器)是如何将数据包送到目的地的呢?它是怎么选择一个合适的路径来"送货"的呢?
最特殊的情况是目的主机和主机直连,那么主机根本不用寻找路由,直接把数据传递过去就可以了。至于是怎么直接传递的,这就要靠ARP协议了,后面会讲到。
稍微一般一点的情况是,主机通过若干个路由器(router)和目的主机连接。那么路由器就要通过ip包的信息来为ip包寻找到一个合适的目标来进行传递,比如合适的主机,或者合适的路由。路由器或者主机将会用如下的方式来处理某一个IP数据包
- 如果IP数据包的TTL(生命周期)以到,则该IP数据包就被抛弃。
- 搜索路由表,优先搜索匹配主机,如果能找到和IP地址完全一致的目标主机,则将该包发向目标主机
- 搜索路由表,如果匹配主机失败,则匹配同子网的路由器,这需要“子网掩码(1.3.)”的协助。如果找到路由器,则将该包发向路由器。
- 搜索路由表,如果匹配同子网路由器失败,则匹配同网号(第一章有讲解)路由器,如果找到路由器,则将该包发向路由器。
- 搜索路由表,如果以上都失败了,就搜索默认路由,如果默认路由存在,则发包
- 如果都失败了,就丢掉这个包。
这再一次证明了,ip包是不可靠的。因为它不保证送达。
子网寻址
IP地址的定义是网络号+主机号。但是现在所有的主机都要求子网编址,也就是说,把主机号在细分成子网号+主机号。最终一个IP地址就成为 网络号码+子网号+主机号。
子网掩码
子网掩码是一个32bit的值,其中值为1的比特留给网络号和子网号,为0的比特留给主机号。子网的划分,实际上就是设计子网掩码的过程。子网掩码主要是用来区分IP地址中的网络ID和主机ID,它用来屏蔽IP地址的一部分,从IP地址中分离出网络ID和主机ID。
通过将IP地址与子网掩码进行”与”逻辑操作,得出网络号。
通过将子网掩码的二进制取反后再与IP地址进行相与运算,得到的结果即为主机部分。
假如,假设IP地址为192.160.4.1,子网掩码为255.255.255.0,则网络ID为192.160.4.0,主机ID为0.0.0.1。计算机网络ID的不同,则说明他们不在同一个物理子网内,需通过路由器转发才能进行数据交换。
如何通过子网掩码判断两个IP地址是否在同一网段?
要判断两个IP地址是不是在同一个网段,就将它们的IP地址分别与子网掩码做与运算,得到的结果一网络号,如果网络号相同,就在同一子网,否则,不在同一子网。
例:假定选择了子网掩码255.255.254.0,现在分别将上述两个IP地址分别与掩码做与运算,如下图所示:
211.95.165.24 11010011 01011111 10100101 00011000
255.255.254.0 11111111 11111111 111111110 00000000
与的结果是: 11010011 01011111 10100100 00000000
211.95.164.78 11010011 01011111 10100100 01001110
255.255.254.0 11111111 11111111 111111110 00000000
与的结果是: 11010011 01011111 10100100 00000000
可以看出,得到的结果(这个结果就是网络地址)都是一样的,因此可以判断这两个IP地址在同一个子网。
在知道ip地址的情况下,求合适的子网掩码
IPv4的规定,对IP地址强行定义了一些保留地址,即:“网络地址”和“广播地址”。所谓“网络地址”就是指“主机号”全为“0”的IP地址,如:125.0.0.0(A类地址);而“广播地址”就是指“主机号”全为“255”时的IP地址,如:125.255.255.255(A类地址)。而子网掩码,则是用来标识两个IP地址是否同属于一个子网。它也是一组32位长的二进制数值,其每一位上的数值代表不同含义:为“1”则代表该位是网络位;若为“0”则代表该位是主机位。和IP地址一样,人们同样使用“点式十进制”来表示子网掩码,如:255.255.0.0。
如果两个IP地址分别与同一个子网掩码进行按位“与”计算后得到相同的结果,即表明这两个IP地址处于同一个子网中。也就是说,使用这两个IP 地址的两台计算机就像同一单位中的不同部门,虽然它们的作用、功能、乃至地理位置都可能不尽相同,但是它们都处于同一个网络中。


自从各种类型的网络投入各种应用以来,网络就以不可思议的速度进行大规模的扩张,目前正在使用的IPv4也逐渐暴露出了它的弊端,即:网络号占位太多,而主机号位太少。目前最常用的一种解决办法是对一个较高类别的IP地址进行细划,划分成多个子网,然后再将不同的子网提供给不同规模大小的用户群使用。使用这种方法时,为了能有效地提高IP地址的利用率,主要是通过对IP地址中的“主机号”的高位部分取出作为子网号,从通常的“网络号”界限中扩展或压缩子网掩码,用来创建一定数目的某类IP地址的子网。当然,创建的子网数越多,在每个子网上的可用主机地址的数目也就会相应减少。
要计算某一个IP地址的子网掩码,可以分以下两种情况来分别考虑。
- 无须划分成子网的IP地址。
一般来说,此时计算该IP地址的子网掩码非常地简单,可按照其定义就可写出。例如:某个IP地址为12.26.43.0,无须再分割子网,按照定义我们可以知道它是一个A类地址,其子网掩码应该是255.0.0.0;若此IP地址是一个B类地址,则其子网掩码应该为255.255.0.0;如果它是C类地址,则其子网掩码为255.255.255.0。其它类推。
- 要划分成子网的IP地址。
当然,在求子网掩码之前必须先清楚要划分的子网数目,以及每个子网内的所需主机数目。
方法一:利用子网数来计算。
- 首先,将子网数目从十进制数转化为二进制数;
- 接着,统计由“1”得到的二进制数的位数,设为N;
- 最后,先求出此IP地址对应的地址类别的子网掩码。再将求出的子网掩码的主机地址部分(也就是“主机号”)的前N位全部置1,这样即可得出该IP地址划分子网的子网掩码。
- 例如:需将B类IP地址167.194.0.0划分成28个子网:
1)(28)10=(11100)2;
2)此二进制的位数是5,则N=5;
3)此IP地址为B类地址,而B类地址的子网掩码是255.255.0.0,且B类地址的主机地址是后2位(即0-255.1-254)。于是将子网掩码255.255.0.0中的主 机地址前5位全部置1,就可得到255.255.248.0,而这组数值就是划分成 28个子网的B类IP地址 167.194.0.0的子网掩码。
方法二:利用主机数来计算。
- 首先,将主机数目从十进制数转化为二进制数;
- 接着,如果主机数小于或等于254(注意:应去掉保留的两个IP地址),则统计由“1”中得到的二进制数的位数,设为N;如果主机数大于 254,则 N>8,也就是说主机地址将超过8位;
- 最后,使用255.255.255.255将此类IP地址的主机地址位数全部置为1,然后按照“从后向前”的顺序将N位全部置为0,所得到的数值即为所求的子网掩码值。
- 例如:需将B类IP地址167.194.0.0划分成若干个子网,每个子网内有主机500台:
1)(500)10=(111110100)2;
2)此二进制的位数是9,则N=9;
3)将该B类地址的子网掩码255. 255.0.0的主机地址全部置 1,得到255.255.255.255。然后再从后向前将后9位置0,可得:11111111. 11111111.11111110.00000000即255.255.254.0。这组数值就是划分成主机为500台的B类IP地址 167.194.0.0的子网掩码。
子网掩码的表示方法 除了使用上述的表示方法之外,还有使用子网掩码中”1”的位数来表示的,在默认情况下,A类地址为8位,B类地址为16位,C类地址为24位。例如,A类的某个地址为 12.10.10.3/8,这里的最后一个”8”说明该地址的子网掩码中的”1”有8位,即255.0.0.0,而199.42.26.0/28表示网络199.42.26.0的子网掩码中“1”的位数有28位。
给定IP地址和子网掩码,我们就可以确定IP数据报的目的是:
1.本子网上的主机;
2.本网络中其他子网的主机;
3.其他网络上的主机。
(从IP地址的高位,我们可以知道网络号和子网号的分界,从子网掩码,我们可以知道子网号和主机号的分界)
子网划分的好处: 1.广播只能在子网中传播,而常常接受者只有一台主机,如果网络太大,消耗很大,而子网划分可以减少这个消耗。 2.虽然划分子网后,可用ip减少了(因为对于每个子网,都要占用本机地址和广播地址),但是对于小型网络来说,划分子网后可节省大量IP地址资源。因为几个小网络可以共用一个大的网络地址范围,而且同样可以取到隔离的作用。如果没有子网划分的功能,那么可能我们需要取几个C类的网段,但是每个网段却只用了及其少一部分,从而造成浪费。 3.不同子网间是不能直接通信的,这提高了安全性,便于管理。
ARP协议
还记得数据链路层的以太网的协议中,每一个数据包都有一个MAC地址头么?我们知道每一块以太网卡都有一个MAC地址,这个地址是唯一的,那么IP包是如何知道这个MAC地址的?这就是ARP协议的工作。
ARP(地址解析)协议是一种解析协议,本来主机是完全不知道这个IP对应的是哪个主机的哪个接口,当主机要发送一个IP包的时候,会首先查一下自己的ARP高速缓存(就是一个IP-MAC地址对应表缓存),如果查询的IP-MAC值对不存在,那么主机就向网络发送一个ARP协议广播包,这个广播包里面就有待查询的IP地址,而直接收到这份广播的包的所有主机都会查询自己的IP地址,如果收到广播包的某一个主机发现自己符合条件,那么就准备好一个包含自己的MAC地址的ARP包传送给发送ARP广播的主机,而广播主机拿到ARP包后会更新自己的ARP缓存(就是存放IP-MAC对应表的地方)。发送广播的主机就会用新的ARP缓存数据准备好数据链路层的的数据包发送工作。
一个典型的arp缓存信息如下,在任意一个系统里面用“arp -a”命令:
Internet Address Physical Address Type
192.168.11.1 00-0d-0b-43-a0-2f dynamic
192.168.11.2 00-01-4a-03-5b-ea dynamic
其他知识点
ifconfig命令
这个命令可以查询主机上的每个接口,包含了大量的信息,比如inet地址,硬件地址,掩码,MTU等等。
netstat命令
netstat命令也提供系统上的接口信息,-i参数将打印出接口信息,-n参数则打印出IP地址而不是主机名字。
A类 1.0.0.0 到126.0.0.0 0.0.0.0 和127.0.0.0保留 B类 128.1.0.0到191.254.0.0 128.0.0.0和191.255.0.0保留 C类 192.0.1.0 到223.255.254.0 192.0.0.0和223.255.255.0保留 D类 224.0.0.0到239.255.255.255用于多点广播 E类 240.0.0.0到255.255.255.254保留 255.255.255.255用于广播
CIDR(Classless Interdomain Routing)
CIDR为无类别的域间路由选择,是一种为解决地址耗尽而提出的一种措施。基本思想:适当分配多个合适的IP地址,使得这些地址能够进行聚合,减少这些地址在路由表中的表项数。如,给某个网络分配16个C类地址,采用适当的方法分配这些地址,使得16个地址能够聚合成一个地址。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号