【大数据作业五】理解爬虫原理
作业要求来自: https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2851
1. 简单说明爬虫原理
向网站发起请求,获取资源后分析并提取有用数据的程序。
流程:

2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
浏览器渲染过程:
- 解析html 为DOM 树
- 渲染树结构
- 布局渲染树
- 绘制渲染树
解析html 为DOM 树 :
1)HTML字节流解码变为字符流。根据不同编码方式,如UTF-8 GBK来解码
2)词法分析:将字符流解析为一个个词语
3)语法分析:通过不同标签,生成node节点
4)构建DOM树:将node节点组织成DOM树
CSS解析器读取CSS文件,得到元素最匹配的样式
1)经过词法分析和语法分析,生成一个个CSS规则。规则由选择器和一个key:value对组成的属性集合构成
2)进行规则匹配:根据元素信息,如id class 标签,通过不同优先级得到元素最匹配的CSS规则
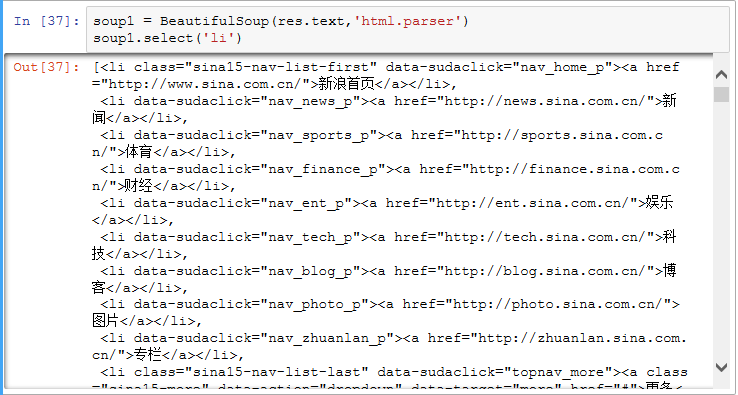
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
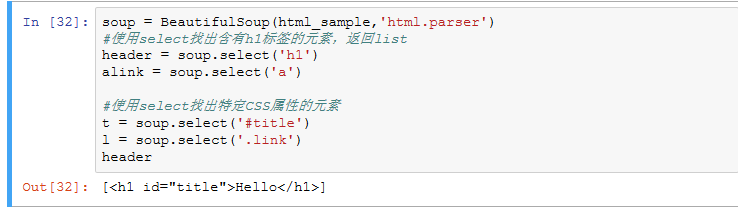
3).了解网页
写一个简单的html文件,包含多个标签,类,id
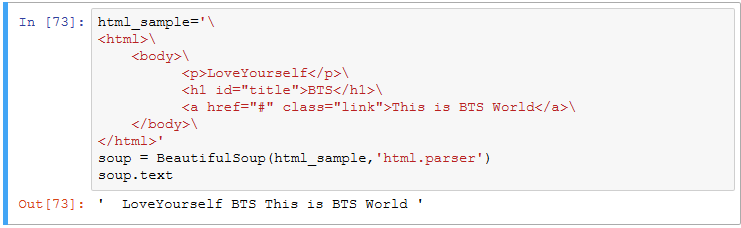
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
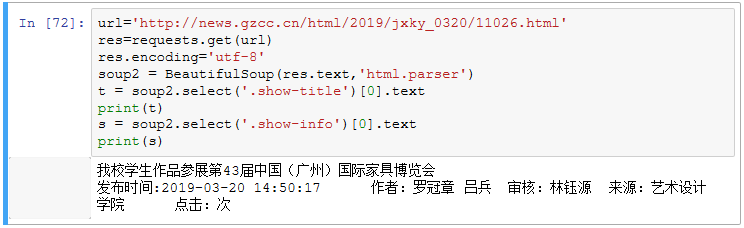
3.提取一篇校园新闻的标题、发布时间、发布单位
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'