


【大数据作业三】复合数据类型,英文词频统计
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
1.列表,元组,字典,集合分别如何增删改查及遍历。
列表:


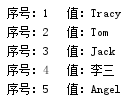
1 #列表的增 2 cm=['Tracy','Tom','Jack','李三','Angel'] 3 cm.insert(1,'Baby') 4 print(cm) 5 #列表的删 6 cm=['Tracy','Tom','Jack','李三','Angel'] 7 cm.pop(3) 8 print(cm) 9 #列表的改 10 cm=['Tracy','Tom','Jack','李三','Angel'] 11 cm[2]='Baby' 12 print(cm) 13 #列表的查 14 cm=['Tracy','Tom','Jack','李三','Angel'] 15 if 'Jack' in cm: 16 index = cm.index('Jack') # 查找元素下标 17 print(index) 18 #列表的遍历 19 cm=['Tracy','Tom','Jack','李三','Angel'] 20 for i in cm: 21 print("序号:%s 值:%s" % (cm.index(i) + 1, i))
结果图:
(列表的增)

(列表的删)

(列表的改)

(列表的查)

(列表的遍历)
元组:
1 #元组的增 2 tup1=(1,2,3) 3 tup2=(4,5,6) 4 tup=tup1+tup2 5 print(tup) 6 #元组的删 7 tup=(1, 2, 3, 4, 5, 6) 8 del(tup) 9 print(tup) 10 #元组的改 11 tup=('a','b','c','d','e') 12 tup=tup[1],tup[2],tup[4] 13 print(tup) 14 #元组的查 15 tup=(1,2,3,4) 16 print(tup[2]) 17 # 元组的遍历 18 tuple = (("apple", "banana"), ("grape", "orange"), ("watermelon",), ("grapefruit",)) 19 for i in range(len(tuple)): 20 for j in range(len(tuple[i])): 21 print("tuple[%d][%d]" % (i, j)) 22 print(tuple[i][j], "")
结果图:
(元组的增)

(元组的删)
(元组的改)
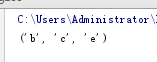
(元组的查)
(元组的遍历)

字典:
1 # 字典的增 2 dict={'name':'li','age':1} 3 dict['class']='first' 4 print(dict) 5 # 字典的删 6 dict={'name': 'li', 'age': 1, 'class': 'first'} 7 del dict['class'] 8 print(dict) 9 # 字典的改 10 dict={'name': 'pang', 'age': 1, 'class': 'first'} 11 dict['name']='li' 12 print(dict) 13 # 字典的查 14 dict={'name': 'pang', 'age': 1, 'class': 'first', 'school': 'wawo'} 15 print(dict.get('age')) 16 # 字典的遍历 17 dict={'a': '1', 'b': '2', 'c': '3'} 18 for key in dict: 19 print(key+':'+dict[key])
结果图:
(字典的增)

(字典的删)

(字典的改)
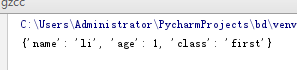
(字典的查)

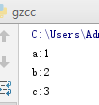
(字典的遍历)
集合:
1 # 集合的增 2 s = {1,2,3,4} 3 s.add(7) 4 print(s) 5 # 集合的删 6 s = {'a','hello', 'redhat', 'b', 18, 33, 4, 1, 2, 7, 6, 5} 7 print(s) 8 print(s.pop()) 9 # 集合的查 10 s1 = {1, 2, 3, 4} 11 s2 = {1, 2, 3, 5} 12 # 交集 13 print(s1 & s2) 14 # 集合的遍历 15 s = [1234, 5677, 8899] 16 for id in s: 17 print (id)
结果图:
(集合的增)
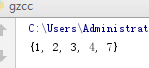
(集合的删)

(集合的查)

(集合的遍历)

2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
| 列表 | 元组 | 字典 | 集合 | |
| 括号 | [1,'a'] |
('a', 1) |
{'a':1,'b':2} |
set([1,2]) 或 {1,2} |
| 是否有序 | 有序 | 有序 | 无序,自动正序 | 无序 |
| 是否可变 | 是 | 否 | 是 | 是 |
| 是否可重复 | 是 | 是 | 是 | 否 |
| 存储与查找方式 | 值 | 值 | 键值对(键不能重复) | 键(不能重复) |
3.词频统计
统计每个单词出现的次数,并按次数进行排序
1 exclude={'a','the','and','i','you','in','but','not','it'} 2 def gettxt(): 3 sep=".,;:?!-_'" 4 txt=open(r'F:\aaa.txt').read().lower() 5 for ch in sep: 6 txt =txt.replace(ch,' ') 7 return txt 8 9 bigList=gettxt().split() 10 print(bigList) 11 print('father:',bigList.count('father')) 12 bigSet =set(bigList) 13 14 bigSet=bigSet-exclude 15 print(bigSet) 16 bigDict={} 17 for word in bigSet: 18 bigDict[word]=bigList.count(word) 19 print(bigDict) 20 21 print(bigDict.items()) 22 word=list(bigDict.items()) 23 word.sort(key=lambda x:x[1],reverse=True) 24 print(word) 25 26 for w in bigSet: 27 bigDict[w]=bigList.count(w) 28 sortWord=sorted(bigDict.items(),key=lambda e:e[1],reverse=True) 29 save=open(r'F:\aaa.txt','w',encoding='UTF-8') 30 for w in range(20): 31 save.write(str(sortWord[w])+"\n") 32 save.close()
结果如图:

生成的云图如下:


