
【大数据作业二】字符串操作,英文词频统计预处理
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2646
1.字符串操作:
- 解析身份证号:生日、性别、出生地等。
- 凯撒密码编码与解码
- 网址观察与批量生成
解析身份证号:


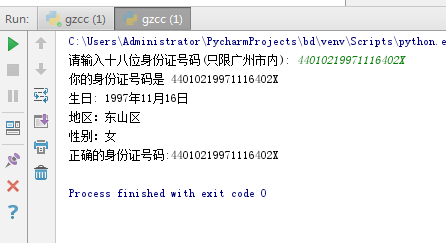
1 ID = input('请输入十八位身份证号码(只限广州市内): ') 2 if len(ID) == 18: 3 print("你的身份证号码是 " + ID) 4 else: 5 print("错误的身份证号码") 6 7 ID_add = ID[0:4] 8 ID_area=ID[4:6] 9 ID_birth = ID[6:14] 10 ID_sex = ID[14:17] 11 ID_check = ID[17] 12 13 # ID_add是身份证中的区域代码,如果有一个行政区划代码字典,就可以用获取大致地址# 14 15 year = ID_birth[0:4] 16 moon = ID_birth[4:6] 17 day = ID_birth[6:8] 18 print("生日: " + year + '年' + moon + '月' + day + '日') 19 20 if ID_area == 16: 21 print('地区:萝岗区') 22 if ID_area == '06': 23 print('地区:天河区') 24 if ID_area == '03': 25 print('地区:荔湾区') 26 if ID_area == '04': 27 print('地区:越秀区') 28 if ID_area == '05': 29 print('地区:海珠区') 30 if ID_area == '07': 31 print('地区:芳村区') 32 if ID_area == 11: 33 print('地区:白云区') 34 if ID_area == 12: 35 print('地区:黄埔区') 36 if ID_area == 13: 37 print('地区:番禺区') 38 if ID_area == 14: 39 print('地区:花都区') 40 if ID_area == 15: 41 print('地区:南沙区') 42 if ID_area == '02': 43 print("地区:东山区") 44 45 46 if int(ID_sex) % 2 == 0: 47 print('性别:女') 48 else: 49 print('性别:男') 50 51 # 此部分应为错误判断,如果错误就不应有上面的输出,如何实现?# 52 W = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2] 53 ID_num = [18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2] 54 ID_CHECK = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2'] 55 ID_aXw = 0 56 for i in range(len(W)): 57 ID_aXw = ID_aXw + int(ID[i]) * W[i] 58 59 ID_Check = ID_aXw % 11 60 if ID_check == ID_CHECK[ID_Check]: 61 print('正确的身份证号码:{}'.format(ID)) 62 else: 63 print('错误的身份证号码')
显示结果:
凯撒密码编码与解码:
1 plaincode=input('') 2 for i in plaincode: 3 print(chr(ord(i)+3),end='') 4 plaincode=input('') 5 s=ord('a') 6 t=ord('z') 7 for i in plaincode: 8 if s<= ord(i)<=t: 9 print(chr(s+(ord(i)-s+3)%26), end='') 10 else: 11 print(i,end='')
显示结果:

网址观察:
1 #引入第三方库,并用as取别名 2 import webbrowser as web 3 url='http://news.gzcc.cn/html/xiaoyuanxinwen/' 4 web.open_new_tab(url) 5 for i in range(2,4): 6 web.open_new_tab('http://news.gzcc.cn/html/xiaoyuanxinwen/'+str(i)+'.html')
显示结果:
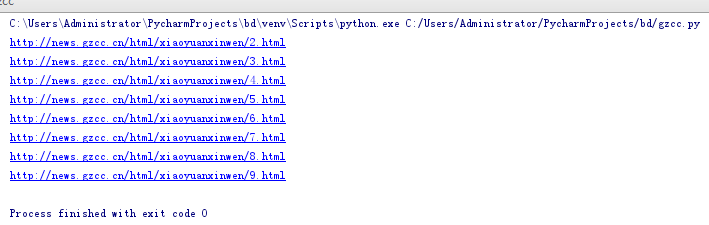
网址批量生成:
1 for i in range(2,10): 2 url='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) 3 print(url)
显示结果:
2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
英文词频统计:
1 text='''When the bundle was 2 nestled in her 3 arms and she moved 4 the fold of cloth to look 5 upon his tiny face, she gasped. 6 The doctor turned quickly 7 and looked out the tall 8 hospital window. The baby 9 had been born without ears.''' 10 print(text.split()) 11 print(text.count('the'),text.count('The'))
显示结果:
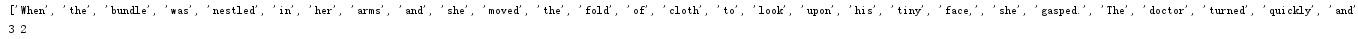
大小写转换及统计:
1 text='''When the bundle was 2 nestled in her 3 arms and she moved 4 the fold of cloth to look 5 upon his tiny face, she gasped. 6 The doctor turned quickly 7 and looked out the tall 8 hospital window. The baby 9 had been born without ears.''' 10 text=text.lower() 11 sep='.,' 12 for s in sep: 13 text=text.replace(s,' ') 14 print(text.split()) 15 print(text.count('the'),text.count('The'))
显示结果:

将文章改成txt模式打开:
1 f = open(r'F:\python\thee.txt','r') 2 text=f.read() 3 print(text) 4 f.close()
显示结果:


