4.Hive安装
1.系统版本信息
OS:Debian-8.2 Jdk:1.8.0_181 Hadoop:2.8.4 Zookeeper:3.9.10 Hbase:1.4.6 Hive:2.3.3
主机信息
192.168.74.131 master 192.168.74.133 slave1 192.168.74.134 slave2 192.168.74.135 slave3
2.只需在master上安装hive
A:下载Hive-2.3.3
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz, 镜像地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/
B:解压,移动到指定文件夹
tar zxvf apache-hive-2.3.3-bin.tar.gz mv apache-hive-2.3.3-bin /home/hadoop/opt/ cd /home/hadoop/opt/ mv apache-hive-2.3.3-bin hive-2.3.3
C:添加环境变量
sudo vim /etc/profile #Set Hive Path export HIVE_HOME=/home/hadoop/opt/hive-2.3.3 export PATH=$PATH:$HIVE_HOME/bin #立即生效 source /etc/profile
D:修改配置文件
cd /home/hadoop/opt/hive-2.3.3/conf cp hive-default.xml.template hive-site.xml cp hive-env.sh.template hive-env.sh
#hive-env.sh
HADOOP_HOME=/home/hadoop/opt/hadoop-2.8.4 export HIVE_CONF_DIR=/home/hadoop/opt/hive-2.3.3/conf
#hive-site.xml
<!-- HDFS路径hive表的存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://master:9000/hive/warehouse</value>
</property>
<!--HDFS路径,用于存储不同 map/reduce 阶段的执行计划和这些阶段的中间输出结果。 -->
<property>
<name>hive.exec.scratchdir</name>
<value>hdfs://master:9000/tmp/hive</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/opt/hive-2.3.3/tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/opt/hive-2.3.3/tmp/${hive.session.id}_resources</value>
</property>
根据配置文件 ,在hadoop文件系统中创建相应的目录,一定记得修改文件权限
#hdfs 需要启动 hdfs dfs -mkdir -p /tmp/hive hdfs dfs -mkdir -p /hive/warehouse hdfs dfs -chmod 733 /tmp/hive hdfs dfs -chmod 733 /hive/warehouse
然后在hive的安装根目录下
mkdir tmp
E:启动Hive测试,需要注意的是需要在hive安装目录下的bin目录下执行hive命令,否则会报错
/home/hadoop/opt/hive-2.3.3/bin/hive show tables; create table smq (name string ,count int,status string) row format delimited fields terminated by '\t' stored as textfile ; LOAD DATA LOCAL INPATH ' /usr/local/hive1.2/test.txt' OVERWRITE INTO TABLE smq; select * from smq; exit;
测试2
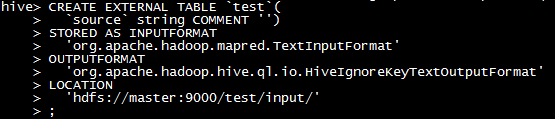
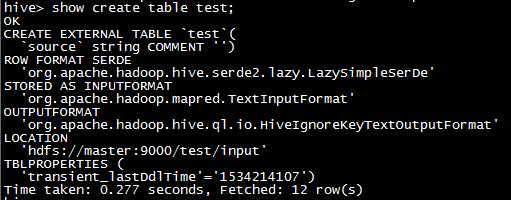
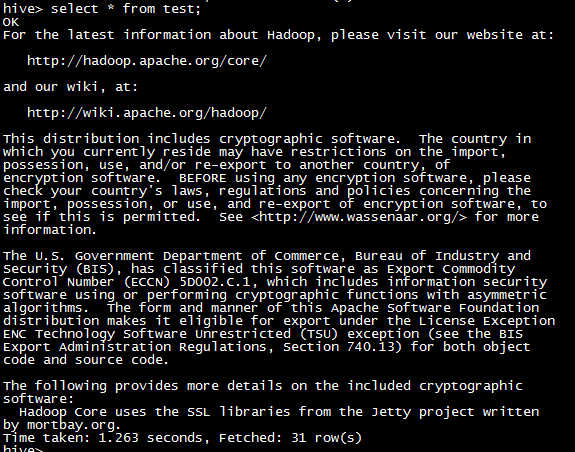
# 搭建hadoop时的world count例子中将README.txt上传到hdfs上/test/input/README.txt CREATE EXTERNAL TABLE `test`( `source` string COMMENT '') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://master:9000/test/input/' ; show create table test; select * from test;
3.可能出现的问题和解决方案
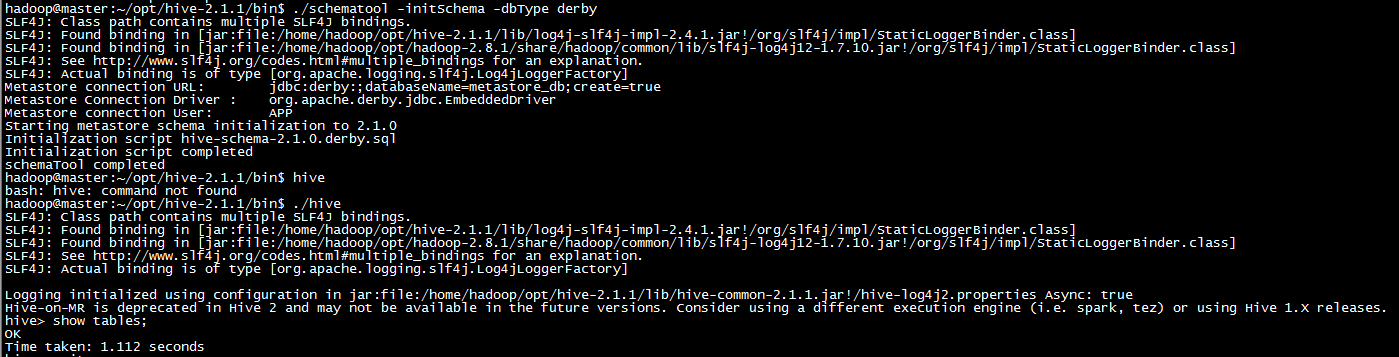
问题A:Exception in thread "main" java.lang.RuntimeException: Hive metastore database is not initialized. Please use schematool (e.g. ./schematool -initSchema -dbType ...) to create the schema. If needed, don't forget to include the option to auto-create the underlying database in your JDBC connection string (e.g. ?createDatabaseIfNotExist=true for mysql)
问题B:Error: FUNCTION 'NUCLEUS_ASCII' already exists. (state=X0Y68,code=30000)
解决方法如下:
cd /home/hadoop/opt/hive-2.3.3/bin #1. 将metastore_db更名为:metastore_db.tmp mv metastore_db metastore_db.tmp #2. schematool -initSchema -dbType derby schematool -initSchema -dbType derby #启动hive进行检测 /home/hadoop/opt/hive-2.3.3/bin/hive
http://www.cnblogs.com/makexu/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号