Web爬虫|入门实战之猫眼电影
 运用正则表达式爬取猫眼电影Top100数据
运用正则表达式爬取猫眼电影Top100数据
版权声明:原创不易,本文禁止抄袭、转载,侵权必究!
一、爬虫任务
任务背景:爬取猫眼电影Top100数据
任务目标:运用正则表达式去解析网页源码并获得所需数据
二、解析
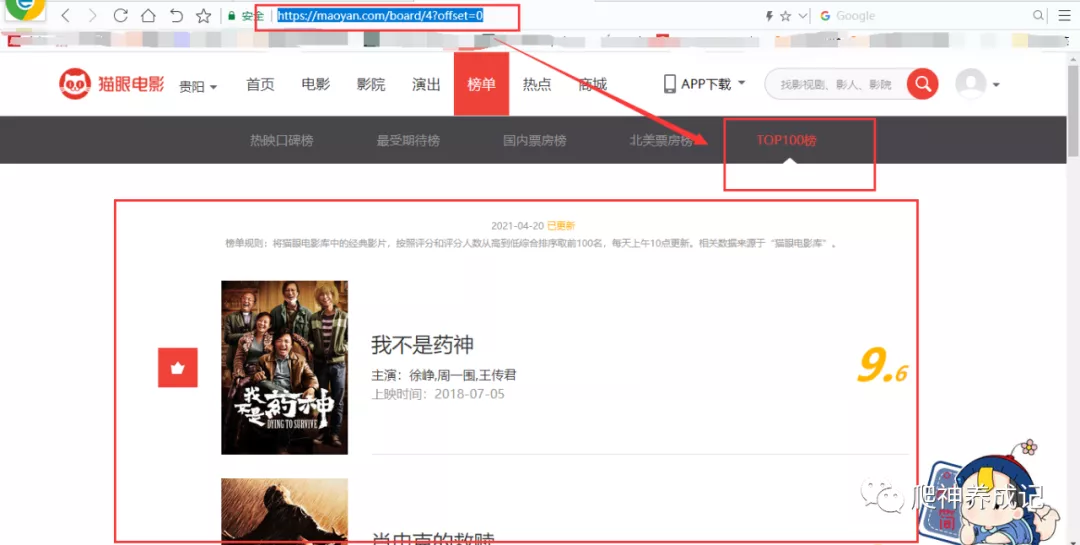
任务URL:https://maoyan.com/board/4?offset=0
下图为猫眼电影的第一页:
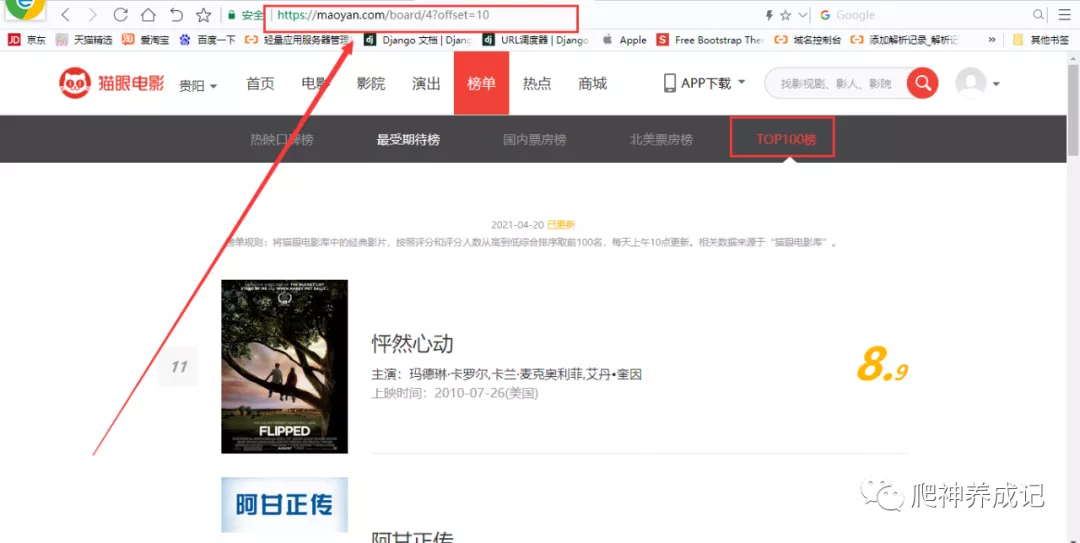
再看看第二页:
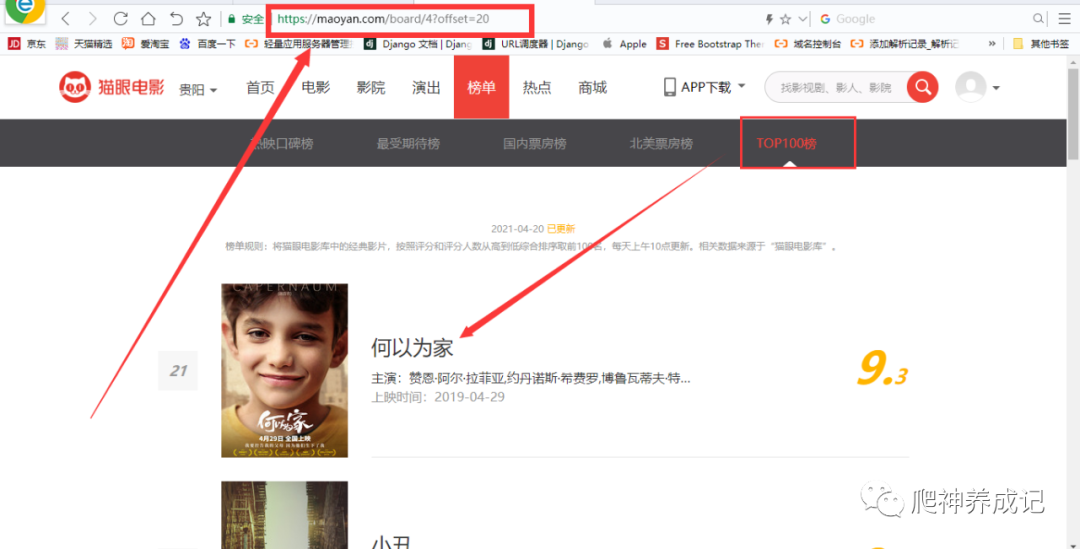
最后看看第三页:
我们把这三页的URL复制下来,看一下URL规律:
1 https://maoyan.com/board/4?offset=0 2 https://maoyan.com/board/4?offset=10 3 https://maoyan.com/board/4?offset=20
从上面的URL可以看出,只有offset变化,offset意为偏移量,从中可以看出每一页的偏移量为10,可以把该参数定义为自变量,然后用循环爬取前10页的数据,也就是top100的数据
爬取任务
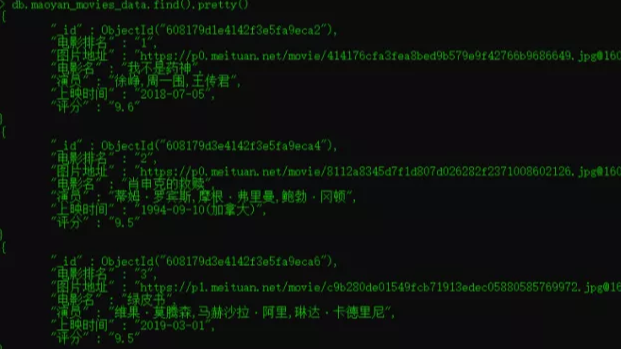
爬取猫眼电影top100电影的电影排名,图片地址,演员,电影名,上映时间以及电影评分
解析网页源代码
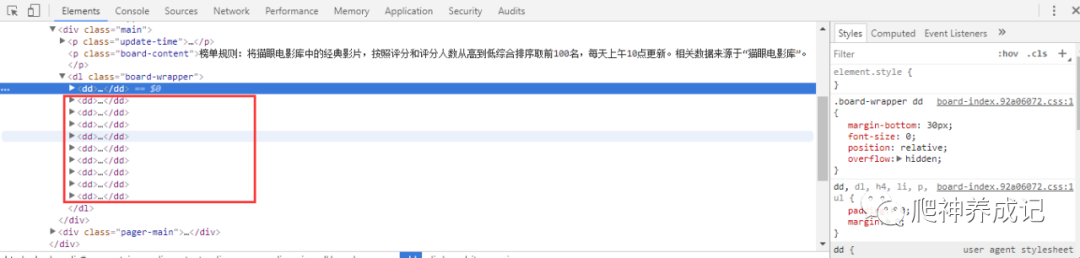
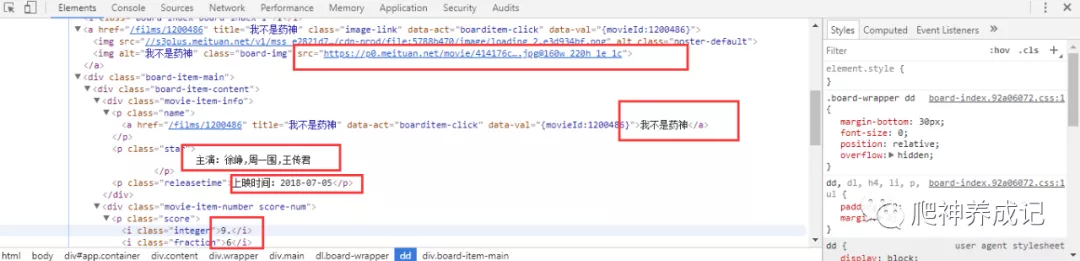
点击箭头打开dd标签块,看看具体的信息:
再看看network中的真实数据:
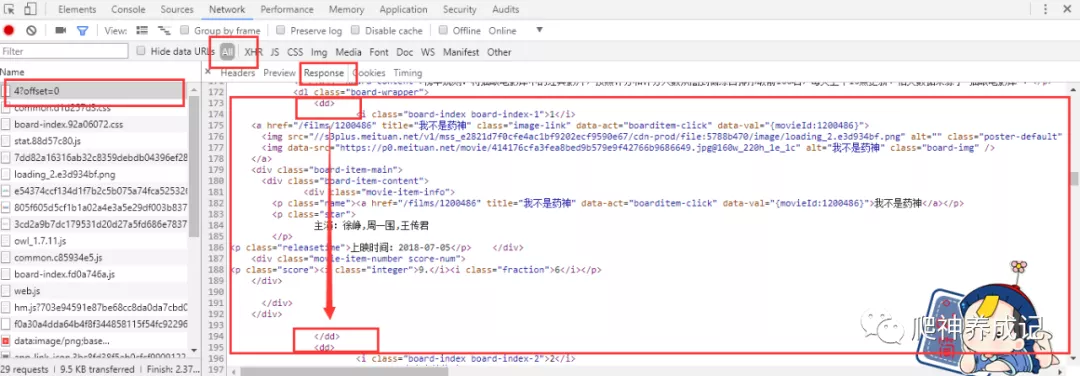
从以上的图中可以看出猫眼电影的数据都保存在dd标签块中,接下来就要用正则表达式去匹配所需的数据,再把这些数据以json格式保存到文本文件中以及MongoDB数据库中
三、编码
获取网页源码
定义一个去获取HTML源码的方法
1 import requests 2 from requests import exceptions 3 4 def get_one_page(url): 5 ''' 6 headers表示要传递的头信息,'User-Agent'表示伪装浏览器 7 ''' 8 try: 9 headers = {'User-Agent':'Mozilla/5.0'} 10 response = requests.get(url,headers=headers) 11 if response.status_code == 200: 12 return response.text 13 else: 14 return None 15 except exceptions.RequestException: 16 return None
解析源码并获得数据
1 import re 2 3 def parse_one_page(html): 4 ''' 5 re.compile()方法会将正则表达式字符串转换为正则表达式对象,方便以后的复用 6 re.S表示修饰符,可以忽略换行符 7 re.findall()方法会将所有符合匹配模式的数据返回,并且以列表形式返回 8 yield是Python中的关键字,表示生成器,类似于return 9 strip()方法可以把空的部分去掉,包括空格,换行符等,但它的操作对象必须是字符串 10 ''' 11 pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' 12 + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' 13 + '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S) 14 movies_information = re.findall(pattern,html) 15 for movie_information in movies_information: 16 yield { 17 '电影排名':movie_information[0], 18 '图片地址':movie_information[1], 19 '电影名':movie_information[2].strip(), 20 '演员':movie_information[3].strip()[3:] if len(movie_information) > 3 else '', 21 '上映时间':movie_information[4].strip()[5:] if len(movie_information) > 5 else '', 22 '评分':movie_information[5].strip() + movie_information[6].strip() 23 }
保存数据到文本文件
1 import json 2 3 def write_movies_data_to_file(movie_information): 4 ''' 5 'a'表示以追加方式把数据写入文件中,这样就不会覆盖之前写入的数据 6 json.dumps()方法可将json文本字符串序列化为json对象 7 ensure_ascii=False表示忽略ASCII码,默认也为False 8 indent表示json格式的缩进 9 ''' 10 with open('../txt_file/maoyan_movies_information.txt','a',encoding='utf-8') as f: 11 f.write(json.dumps(movie_information,indent=2,ensure_ascii=False) + '\n')
保存数据到MongoDB数据库
1 import pymongo 2 3 def insert_to_mongodb(content): 4 ''' 5 client表示操作MongoDB数据库的对象 6 db表示数据库对象 7 collection表示集合对象,类似于MySQL中的table 8 ''' 9 client = pymongo.MongoClient(host='localhost',port=27017) 10 db = client['spiders'] 11 collection = db['maoyan_movies_data'] 12 try: 13 if content: 14 collection.insert(content) 15 print('Success to insert!') 16 except: 17 print('Failed to insert!')
定义main()方法控制程序的运行
1 def main(offset): 2 ''' 3 offset={offset}表示页数偏移量,这里用f-string函数把它设置为自变量,从而可以循环爬取 4 ''' 5 url = f'https://maoyan.com/board/4?offset={offset}' 6 html = get_one_page(url) 7 for movie_information in parse_one_page(html): 8 print(movie_information) 9 write_movies_data_to_file(movie_information) 10 insert_to_mongodb(movie_information)
主程序运行
1 import time 2 3 if __name__ == '__main__': 4 ''' 5 time模块延迟爬取时间,猫眼已经加了反爬 6 ''' 7 for i in range(10): 8 main(offset=i*10) 9 time.sleep(1)
完整源码如下
1 import requests 2 import re 3 import time 4 from requests import exceptions 5 import json 6 import pymongo 7 8 def get_one_page(url): 9 try: 10 headers = {'User-Agent':'Mozilla/5.0'} 11 response = requests.get(url,headers=headers) 12 if response.status_code == 200: 13 return response.text 14 else: 15 return None 16 except exceptions.RequestException: 17 return None 18 19 def parse_one_page(html): 20 pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' 21 + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>' 22 + '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',re.S) 23 movies_information = re.findall(pattern,html) 24 for movie_information in movies_information: 25 yield { 26 '电影排名':movie_information[0], 27 '图片地址':movie_information[1], 28 '电影名':movie_information[2].strip(), 29 '演员':movie_information[3].strip()[3:] if len(movie_information) > 3 else '', 30 '上映时间':movie_information[4].strip()[5:] if len(movie_information) > 5 else '', 31 '评分':movie_information[5].strip() + movie_information[6].strip() 32 } 33 34 def write_movies_data_to_file(movie_information): 35 with open('../txt_file/maoyan_movies_information.txt','a',encoding='utf-8') as f: 36 f.write(json.dumps(movie_information,indent=2,ensure_ascii=False) + '\n') 37 38 def main(offset): 39 url = f'https://maoyan.com/board/4?offset={offset}' 40 html = get_one_page(url) 41 for movie_information in parse_one_page(html): 42 print(movie_information) 43 write_movies_data_to_file(movie_information) 44 insert_to_mongodb(movie_information) 45 46 def insert_to_mongodb(content): 47 client = pymongo.MongoClient(host='localhost',port=27017) 48 db = client['spiders'] 49 collection = db['maoyan_movies_data'] 50 try: 51 if content: 52 collection.insert(content) 53 print('Success to insert!') 54 except: 55 print('Failed to insert!') 56 57 if __name__ == '__main__': 58 for i in range(10): 59 main(offset=i*10) 60 time.sleep(1)
运行效果
控制台输出:
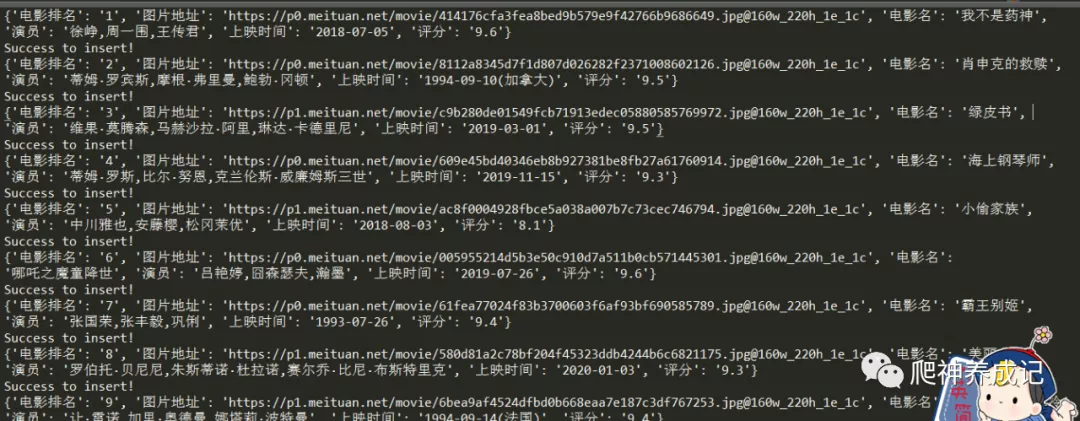
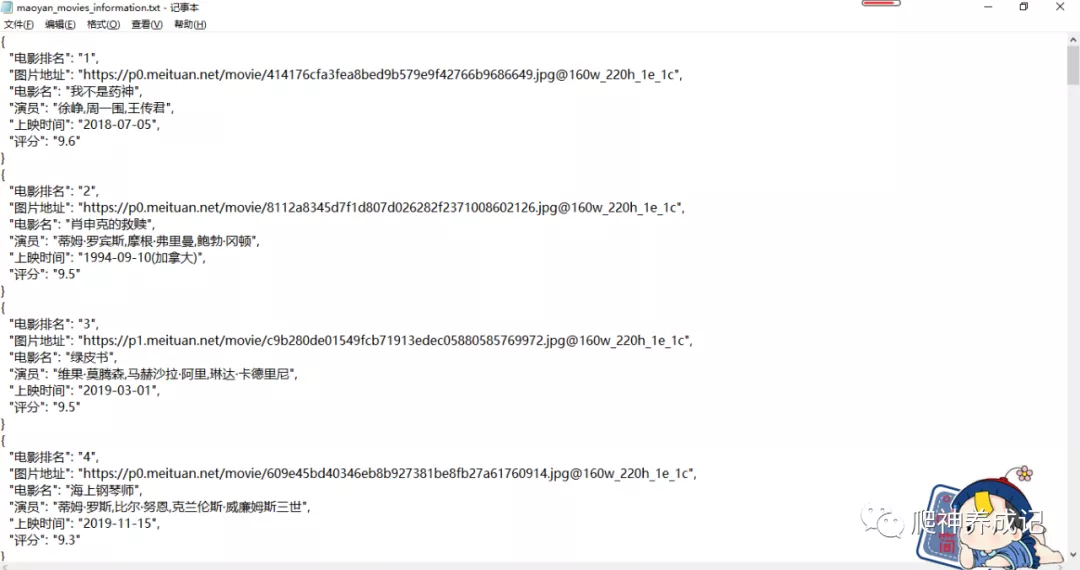
json格式的txt文本结果:
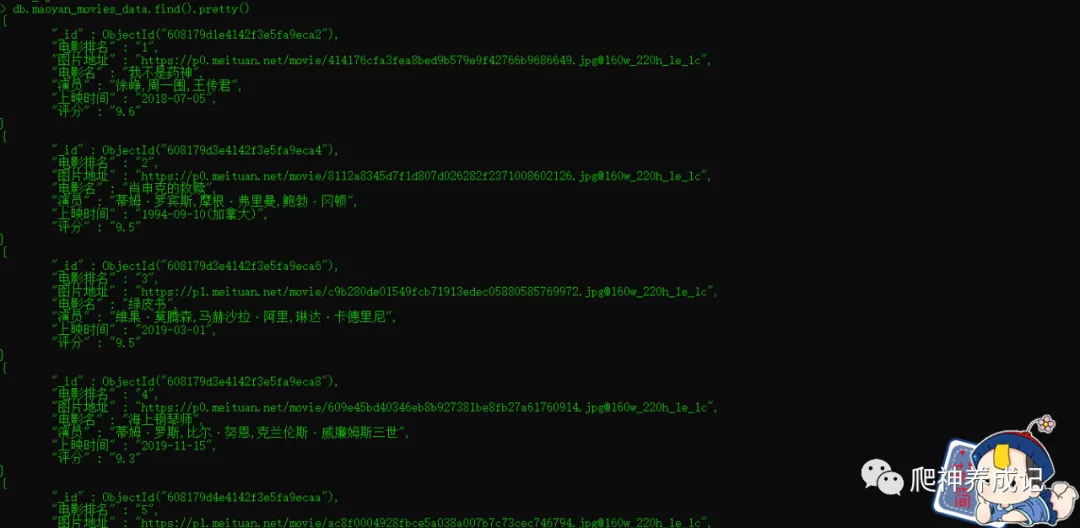
MongoDB输出结果:
四、总结
请求库requests及exceptions模块
标准库re
time模块
json模块
Python与MongoDB数据库对接的pymongo库
原创不易,如果觉得有点用,希望可以随手点个赞,拜谢各位老铁!
五、作者Info
作者:南柯树下,Goal:让编程更有趣!
原创微信公众号:『小鸿星空科技』,专注于算法、爬虫,网站,游戏开发,数据分析、自然语言处理,AI等,期待你的关注,让我们一起成长、一起Coding!
转载说明:本文禁止抄袭、转载 ,侵权必究!
更多独家精彩内容 请扫码关注个人公众号,我们一起成长,一起Coding,让编程更有趣!
—— —— —— —— — END —— —— —— —— ————
欢迎扫码关注我的公众号
小鸿星空科技


 浙公网安备 33010602011771号
浙公网安备 33010602011771号