剖析 Redis List 消息队列的三种消费线程模型
Redis 列表(List)是一种简单的字符串列表,它的底层实现是一个双向链表。
生产环境,很多公司都将 Redis 列表应用于轻量级消息队列 。这篇文章,我们聊聊如何使用 List 命令实现消息队列的功能以及剖析消费者线程模型 。
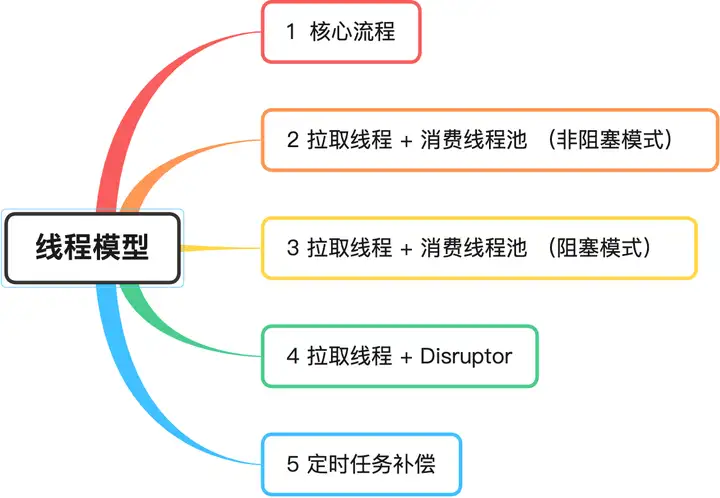
1 核心流程
生产者使用 LPUSH key element[element...] 将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息。
如下,生产者向队列 queue 先后插入了 「Java」「勇哥」「Go」,返回值表示消息插入队列后的个数。
> LPUSH queue Java 勇哥 Go
(integer) 3消费者使用 RPOP key 依次读取队列的消息,先进先出,所以 「Java」会先读取消费:
> RPOP queue
"Java"
> RPOP queue
"勇哥"
> RPOP queue
"Go"

接下来,我们可以通过 spring-data-redis API 演示生产消费流程:
- 生产者
redisTemplate.opsForList().leftPush("queue" , "Java");
redisTemplate.opsForList().leftPush("queue" , "勇哥");
redisTemplate.opsForList().leftPush("queue" , "Go");
- 消费者
我们启动一个独立的线程从队列中读取消息(RPOP 命令),读取成功之后,消费消息,若没有消息,则休眠一会,下一次循环再继续。
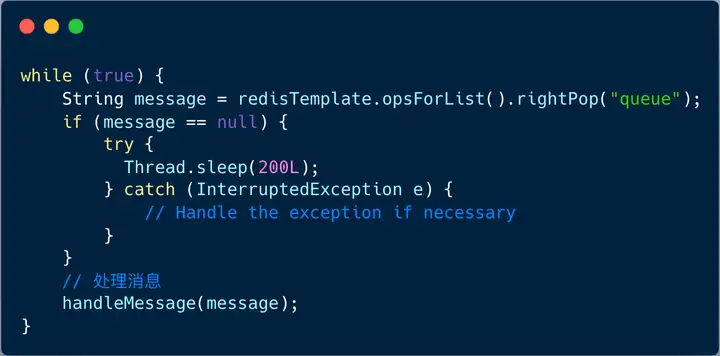
上图的伪代码中, while(true) 循环内不停地调用 RPOP 指令,当有消息时,可以及时处理,但假如没有读取到消息,则需要休眠一会。
这里要加休眠,主要是为了减少空读的频率,避免 CPU 无意义的消耗。
有什么更优化的方式吗? 有,那就是使用 Redis 阻塞读取 List 的命令。
Redis 提供了 BLPOP、BRPOP 阻塞读取的命令,消费者在在读取队列没有数据的时自动阻塞,直到有新的消息写入队列,才会继续读取新消息执行业务逻辑。
BRPOP queue 0参数 0 表示阻塞等待时间无限制 。
如图,我们启动一个消费线程永动机,消费线程拉取消息后,执行消费逻辑。
这种消费者线程模型非常容易理解,同时也非常适合顺序消费的模式。同时,假如我们在消费消息时,服务器宕机或者断电,可能丢失一条消息。
接下来,我们想一想,有没有消费速度更高的消费模型吗? 笔者根据过往的经历,列举三种模式:
- 拉取线程 + 消费线程池(非阻塞模式)
- 拉取线程 + 消费线程池 (阻塞模式)
- 拉取线程 + Disruptor(阻塞模式)
2 拉取线程 + 消费线程池(非阻塞模式)
为了提升消费速度,我们可以将拉取和消费拆分成两种动作,分别通过不同的线程池来处理。拉取线程池负责拉取消息,消费线程池负责消费消息。
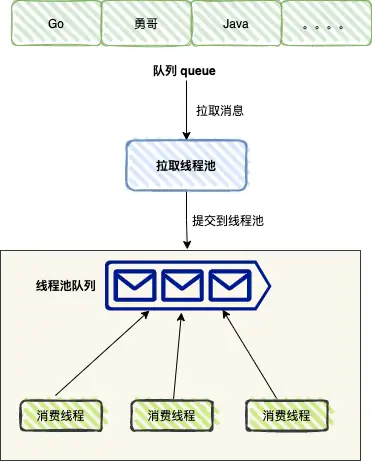
伪代码类似:
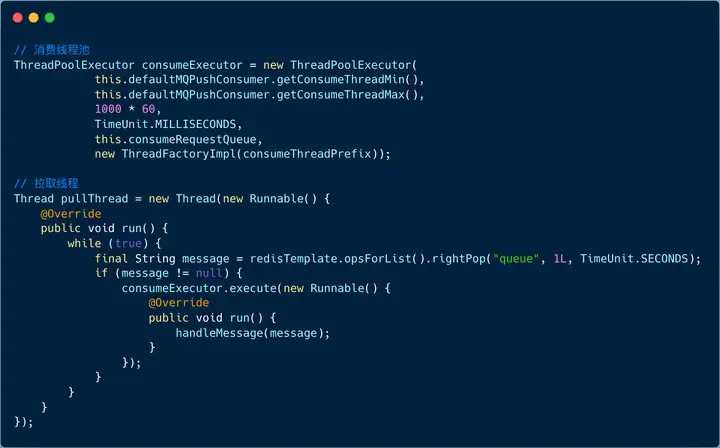
如图,在拉取线程内部,我们拉取完消息后,将消息提交到消费线程 consumeExecutor 。
这样方式可以通过多线程执行大幅度提升消费速度 ,但是这里还是有一个问题:
假如消费速度很慢,生产者速度很高,那么就会在线程池内容易产生消息堆积,这里面会产生两个隐形风险:
- 线程池队列无限堆积,则可能有 OOM 的风险 ;
- 假如消费者服务器宕机或者断电,那么会丢失大量的消息。
那么如何优化这种模式呢 ?
答案是:拉取线程提交消息到线程池时,当队列中消息数量到达一定数量时,提交消息到线程池会阻塞。
3 拉取线程 + 消费线程池(阻塞模式)
我们将消息包装为 Runnable ,然后通过消费线程池执行 execute ,拉取线程会不会阻塞呢 ?
下图是执行的源码:
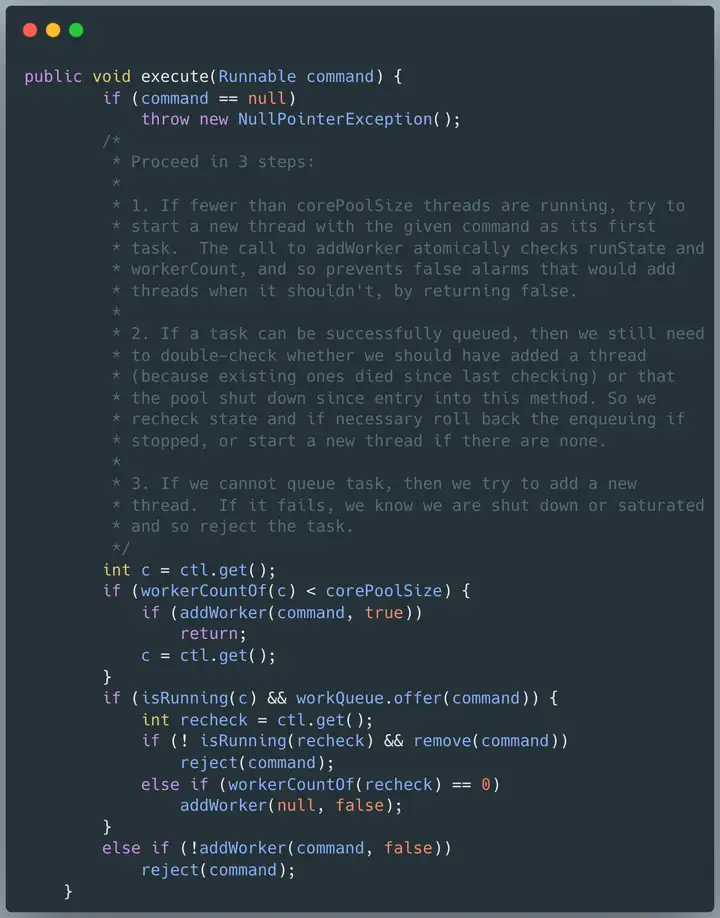
可以看到,第 30 行调用的是 workQueue 的非阻塞的 offer 方法。
如果队列已满,新提交的任务并不会被 block 住,反而会调用后续的 reject 流程。
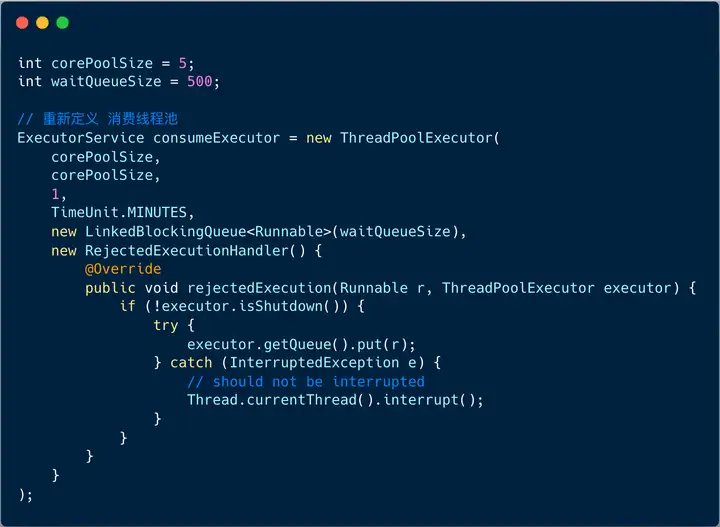
如果我们想要达到阻塞生产者的目的的话,可以采取如下的两种方案:
- 信号量限制同时进入线程池等待队列的任务数 。

- 使用线程池的拒绝机制,把新加入的任务 put 到等待队列里,这样也可以阻塞住生产者。
4 拉取线程 + Disruptor
下图展示了 Disruptor 的流程图 。
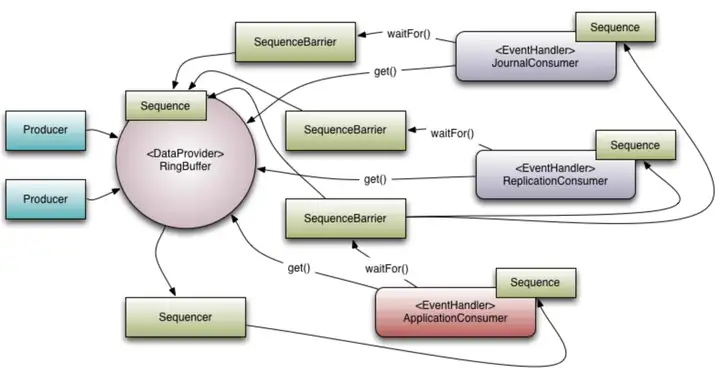
和线程池机制非常类似, Disruptor 也是非常典型的生产者/消费者模式。线程池存储提交任务的容器是阻塞队列,而 Disruptor 使用的是环形缓冲区 RingBuffer。
环形缓冲区的设计相比阻塞队列有如下优点:
- 环形数组结构
为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好。
- 元素位置定位
数组长度 2^n,通过位运算,加快定位的速度。下标采取递增的形式,不用担心 index 溢出的问题。index 是 long 类型,即使100万QPS的处理速度,也需要30万年才能用完。
- 无锁设计
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
此刻大家并不需要理解环形缓冲区的读写机制,只需要明白 环形缓冲区 RingBuffer 是 Disruptor 的精髓即可。
将消费线程池替换成 Disruptor 有两个明显的优点:
- 无锁队列,写入读取性能非常好
- 当拉取线程提交消息到 Disruptor 时,若环形缓冲区 RingBuffer 已经满了,则拉取线程会阻塞,这样天然的可以避免无限拉取,同时避免 OOM 的问题。
伪代码类似:
1、定义 Disruptor
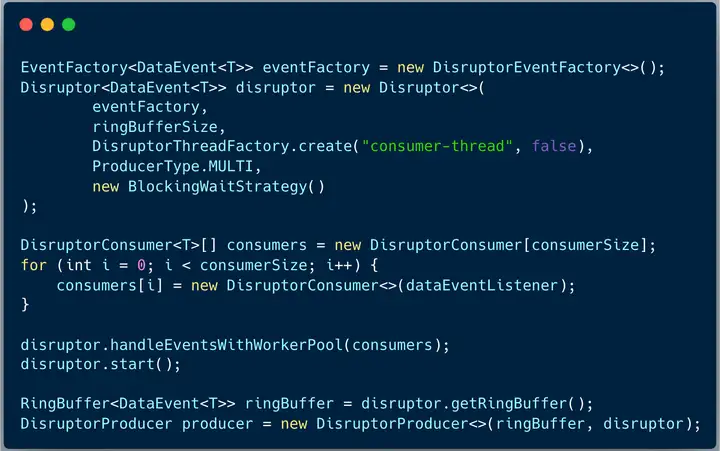
2、拉取线程将消息发送到 Disruptor Ringbuffer
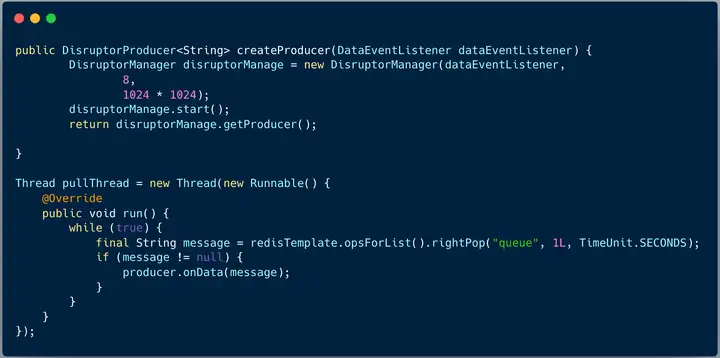
3、消费消息
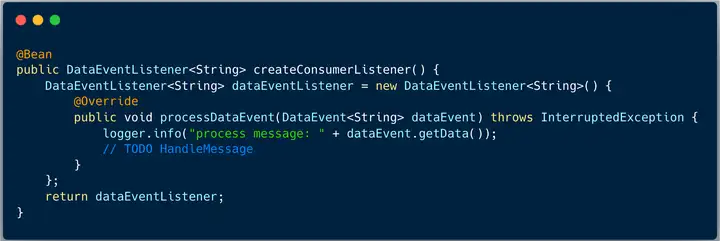
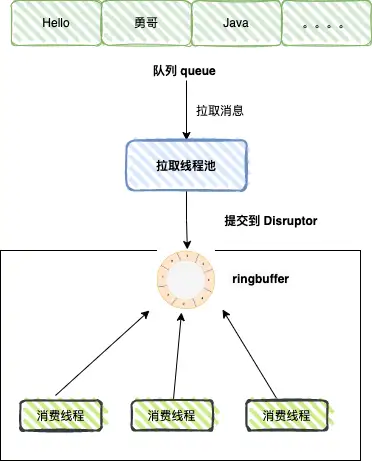
整体的消费者线程模型如下图:
5 平滑停服 + 定时任务补偿
当我们分析消费者线程模型时,无论我们使用哪种方式,假如服务器突然宕机、或者物理机断电,则会丢失消息。
笔者推荐两种方式:
1、平滑停服
平滑停服是指在停止应用程序时,尽量避免中断正在进行的请求或任务,尽量让正在进行的任务处理完成,并且不再接收新的任务,等所有任务执行完成后关闭应用。
在 Unix/Linux 系统中,可以使用 kill 命令发送信号给运行中的进程。
常见的信号有:
SIGTERM(15):请求进程终止,可以被捕捉和处理,用于优雅地停止进程。SIGKILL(9):强制终止进程,不能被捕捉或忽略。SIGQUIT(3):进程退出并生成核心转储(core dump)。
为了实现平滑停服,可以使用 Java 的 Runtime.getRuntime().addShutdownHook 方法注册一个关闭钩子(shutdown hook)。当 JVM 接收到SIGTERM信号时,关闭钩子会被执行,从而可以在应用程序停止前执行一些清理工作。
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
System.out.println("Shutdown hook triggered. Performing cleanup...");
// 在这里执行清理工作,如关闭资源、保存状态等
}));
我们可以在钩子里,关闭拉取线程池 ,优雅关闭消费线程池等 ,这样可以尽量避免丢失消息。
2、定时任务补偿
使用 List 做消息队列,不可避免的会有消息丢失,所以我们需要用定时任务做补偿,每隔一段时间去业务表里查询业务状态机,若状态机不符合条件,则触发补偿策略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号