Bagging,stacking,blending
Bagging
Bagging的代表算法是随机森林,简单说下随机森林的步骤:
(1) 对训练样本进行bootstrap采样,即有放回的采样,获得M个采样集合;
(2) 在这M个采样集合上训练处M个弱决策树。注意到,在决策树生成中还用到了列采样的技巧,原本决策树中节点分裂时,是选择当前节点中所有属性的最优属性进行划分的,但是列采样的技巧是在所有属性中的子集中选最优属性进行划分。这样做可以进一步降低过拟合的可能性;
(3) 对这M个训练出来的弱决策树进行集成。
Stacking
Stacking还没有代表性的算法,我姑且把它理解成一个集成的思想吧。具体做法是:
(1) 先将训练集D拆成k个大小相似但互不相交的子集D1,D2,…,Dk;
(2) 令Dj’= D - Dj,在Dj’上训练一个弱学习器Lj。将Dj作为测试集,获得Lj在Dj上的输出Dj’’;
(3) 步骤2可以得到k个弱学习器以及k个相应的输出Dj’’,这个k个输出加上原本的类标构成新的训练集Dn;
(4) 在Dn训练次学习器L,L即为最后的学习器。
Stacking是用新的模型(次学习器)去学习怎么组合那些基学习器,它的思想源自于Stacked Generalization这篇论文。如果把Bagging看作是多个基分类器的线性组合,那么Stacking就是多个基分类器的非线性组合。Stacking可以很灵活,它可以将学习器一层一层地堆砌起来。
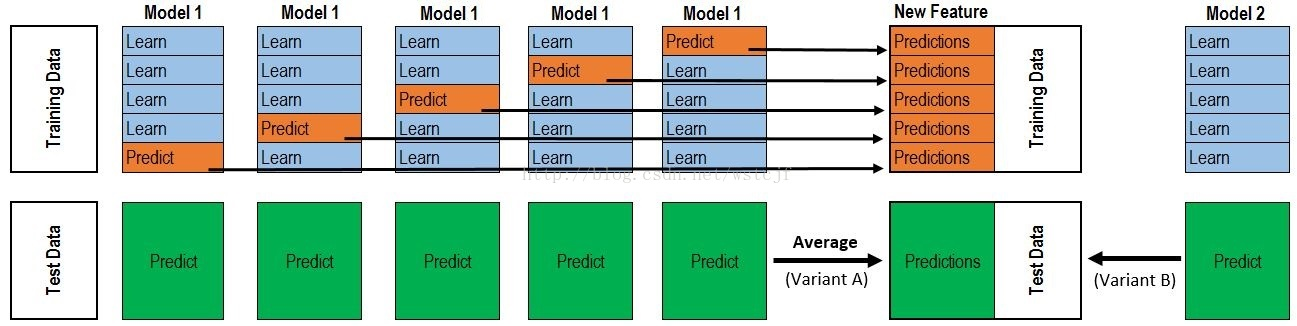
根据上图分析一下stacking具体步骤:
1)TrainingData进行5-fold分割,正好生成5个model,每个model预测训练数据的1/5部分,最后合起来正好是一个完整的训练集Predictions,行数与TrainingData一致。
2)TestData数据,model1-model5每次都对TestData进行预测,形成5份完整的Predict(绿色部分),最后对这个5个Predict取平均值,得到测试集Predictions。
3)上面的1)与2)步骤只是用了一种算法,如果用三种算法,就是三份“训练集Predictions与测试集Predictions”,可以认为就是形成了三列新的特征,训练集Predictions与测试集Predictions各三列。其实三种特征有点少,容易overfitting,尽量多用一些算法。
4)3列训练集Predictions+TrainingData的y值,就形成了新的训练样本数据;测试集Predictions的三列就是新的测试数据。
5)利用meta model(模型上的模型),其实就是再找一种算法对上述新数据进行建模预测,预测出来的数据就是提交的最终数据。
Blending
Blending是一种模型融合方法,对于一般的blending,主要思路是把原始的训练集先分成两部分,比如70%的数据作为训练集,剩下30%的数据作为测试集。第一轮训练: 我们在这70%的数据上训练多个模型,然后去预测那30%测试数据的label。第二轮训练,我们就直接用第一轮训练的模型在这30%数据上的预测结果做为新特征继续训练。
Linear Blending(线性融合)
一般而言, 在个体学习器性能相近时适合使用均匀融合(每个模型g的作用相同),个体学习器性能相差较大时,使用加权平均给每个g都一个不同的权重,效果可能会更好,这就是线性融合(Linear Blending):
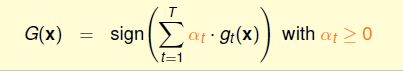
假设我们已经得到了T个 \(g_t\) ,那么应该如何确定 \(α_t\) 呢,思路就是最小化错误 (如使用均方误差):

因此 \(α_t\) 可以通过线性回归/逻辑回归等得到. 因此 Linear Blending 是通过基学习器训练次学习器, 是简化版本的Stacking.
Blending与stacking相比优点在于:
- 比stacking简单(因为不用进行k次的交叉验证来获得新特征)。
- 由于两层训练使用的数据不同,所以避免了一个信息泄露的问题。
- 在团队建模过程中,不需要给队友分享自己的随机种子。
而缺点在于:
- 由于blending对数据集这种划分形式,第二轮的数据量比较少。
- 由于第二轮数据量比较少所以可能会过拟合。
- stacking使用多次的CV会比较稳健。
对于实践中的结果而言,stacking和blending的效果是差不多的,所以使用哪种方法都没什么所谓,完全取决于个人爱好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
