kNN 及 K-D Tree
懒惰学习
基于近邻方法的分类算法被认为是懒惰学习算法,因为没有抽象化的步骤。懒惰学习并不是在学习什么,而是在存储训练数据,这样构建阶段就进行得很快,但进行预测的过程变得相对较慢。由于高度依赖于训练实例,所以懒惰学习又称为基于实例的学习或者机械学习。由于基于实例的学习算法并不会建立一个模型,所以该方法被归类为非参数学习方法,即没有需要学习的参数。
预测过程
对某样本进行分类:
- 计算该样本与每个训练样本的距离.
- 选出与该样本距离最近的K个样本.
- K个近邻投票作为该样本的结果.
距离度量
距离函数:常使用的有欧式距离(Euclidean distance),是比较直观的“直线距离”;曼哈顿距离(街区距离).
标准化:在计算距离之前需要对每个特征值进行标准化使得每种特征具备相等的权重(贡献)。传统方法是min-max normalization:Xnew=( X-min(X) ) / ( max(X)-min(X) )
还有z-score standardization: Xnew=( X-Mean(X) ) / StdDev(X) 。
标准化欧氏距离
样本集的标准化过程为\(X^*={ X-m \over s}\),可推出标准化欧氏距离公式为
如果将方差的倒数看成是一个权重,那么这个公式就可以看成是一种加权欧式距离。
其它距离度量方式
- 夹角余弦
- 汉明距离
- Pearson相关距离\(D_{XY}=1-\rho_{XY}\)
k值选择
- k较小时,使用较小的领域中的训练实例进行预测,“学习”的近似误差会减小,估计误差会增大。k值减小,整体模型变得复杂,容易发生过拟合。
- k较大时正好相反。
实际应用中,K值一般选一个较小的值(不超过训练样本数的平方根),一般采用交叉验证法来选择最优的K值。
缺点
- 样本类别不均衡时分类效果不好.
- 计算量随样本数量的增加而增大.
改进方法
针对KNN计算复杂度高的问题,几种改进办法被提出,Approximate Nearest Neighbor (ANN) 可以加速近邻的查找速度(如FLANN).这些算法通常依赖于预处理/构建索引等步骤(涉及构建kd-tree,或运行k-means等).
K-D Tree 算法原理
KD树是一种查询索引结构,广泛应用于数据库索引中。从概念的角度讲,它是一种高纬数据的快速查询结构。
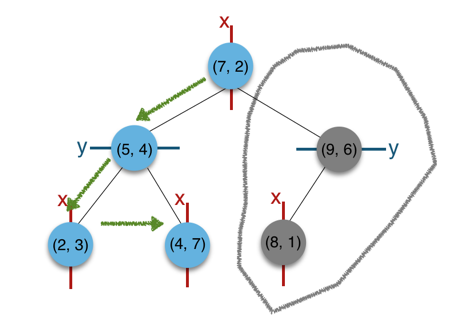
树的构建:
常规的 k-d tree 的构建过程为:循环依序取数据点的各维度来作为切分维度,取数据点在该维度的中值作为切分超平面,将中值左侧的数据点挂在其左子树,将中值右侧的数据点挂在其右子树。递归处理其子树,直至所有数据点挂载完毕。
切分维度选择优化
构建开始前,对比数据点在各维度的分布情况,数据点在某一维度坐标值的方差越大分布越分散,方差越小分布越集中。从方差大的维度开始切分可以取得很好的切分效果及平衡性。
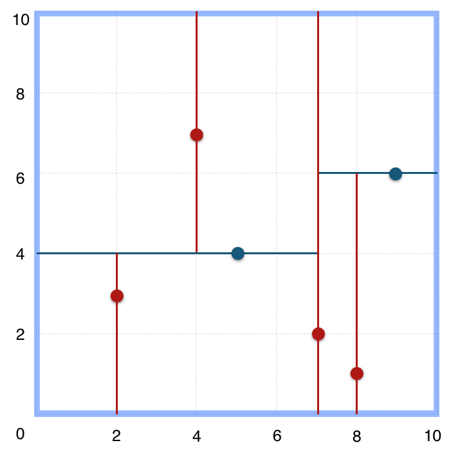

最近邻搜索
给定点p,查询数据集中与其距离最近点的过程即为最近邻搜索。
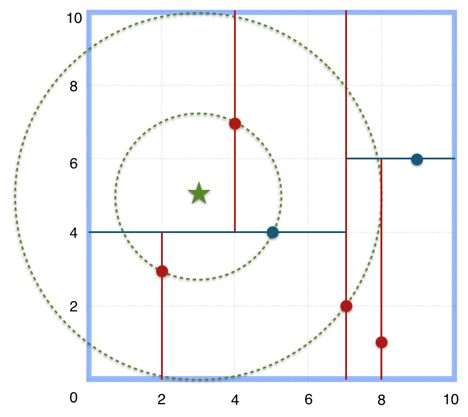
如在上文构建好的 k-d tree 上搜索(3,5)的最近邻时,本文结合如下左右两图对二维空间的最近邻搜索过程作分析。
a)首先从根节点(7,2)出发,将当前最近邻设为(7,2),对该k-d tree作深度优先遍历。以(3,5)为圆心,其到(7,2)的距离为半径画圆(多维空间为超球面),可以看出(8,1)右侧的区域与该圆不相交,所以(8,1)的右子树全部忽略。
b)接着走到(7,2)左子树根节点(5,4),与原最近邻对比距离后,更新当前最近邻为(5,4)。以(3,5)为圆心,其到(5,4)的距离为半径画圆,发现(7,2)右侧的区域与该圆不相交,忽略该侧所有节点,这样(7,2)的整个右子树被标记为已忽略。
c)遍历完(5,4)的左右叶子节点,发现与当前最优距离相等,不更新最近邻。所以(3,5)的最近邻为(5,4)。
scikit-learn 代码示例
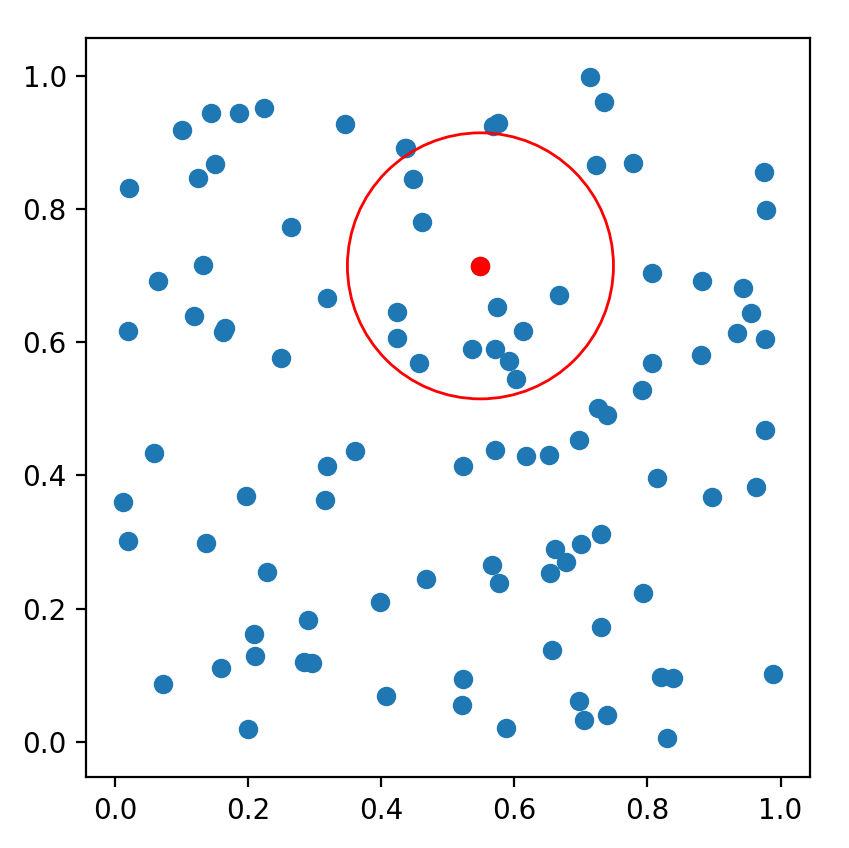
scikit-learn是一个实用的机器学习类库,其有KDTree的实现。如下例子为直观展示,仅构建了一个二维空间的k-d tree,然后对其作k近邻搜索及指定半径的范围搜索。多维空间的检索,调用方式与此例相差无多。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.patches import Circle
from sklearn.neighbors import KDTree
np.random.seed(0)
points = np.random.random((100, 2))
tree = KDTree(points)
point = points[0]
# kNN
dists, indices = tree.query([point], k=3)
print(dists, indices)
# query radius
indices = tree.query_radius([point], r=0.2)
print(indices)
fig = plt.figure()
ax = fig.add_subplot(111, aspect='equal')
ax.add_patch(Circle(point, 0.2, color='r', fill=False))
X, Y = [p[0] for p in points], [p[1] for p in points]
plt.scatter(X, Y)
plt.scatter([point[0]], [point[1]], c='r')
plt.show()
运行示意图如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
