知识蒸馏
 知识蒸馏是一种模型压缩方法,通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的教师模型,在不改变学生模型结构的情况下提高其性能。
知识蒸馏是一种模型压缩方法,通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的教师模型,在不改变学生模型结构的情况下提高其性能。
Knowledge Distill
蒸馏思想
知识蒸馏是一种模型压缩方法,通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的的教学模型(教师模型),在不改变学生模型结构的情况下提高其性能。最早由Hinton在2015年提出,应用于分类任务。知识蒸馏的目的是将教师模型中的知识转移到学生模型中,从而提高学生模型的性能。这个过程类似于数据压缩,将重要的信息从复杂的的数据中提取出来,以便更好地传输和存储。在深度学习中,知识蒸馏通常用于训练轻量级模型,以获得与更复杂的模型相似的性能。
知识蒸馏就是将已经训练好的模型包含的知识,蒸馏到另一个模型中去。具体来说,知识蒸馏,可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。一般是将一个复杂模型(或集成模型)蒸馏到一个轻量级模型中以提升运行速度,但也有以提升指标为目的的蒸馏。
蒸馏的常规做法是先训练一个 teacher 网络,然后使用这个 teacher 网络的输出和数据的真实标签去训练 student 网络。
在训练过程中,我们需要使用复杂的模型,大量的计算资源,以便从非常大、高度冗余的数据集中提取出信息。在实验中,效果最好的模型往往规模很大,甚至由多个模型集成得到。而大模型不方便部署到服务中去,常见的瓶颈如下:
- 推断速度慢
- 对部署资源要求高(内存,显存等),在部署时,我们对延迟以及计算资源都有着严格的限制。
因此,模型压缩(在保证性能的前提下减少模型的参数量)成为了一个重要的问题,而”模型蒸馏“属于模型压缩的一种方法。从模型压缩的角度来看,知识蒸馏像一种正则化的方法,student学习的是teacher的泛化能力,而非过拟合能力。
发展起源
KDD2006论文 Model Compression 中,Rich Caruana 等人提出大型集成模型所获得的知识可以转移到单个小型的模型中,属于蒸馏思想的先驱性的论文。
Geoffrey Hinton 等人在论文 Distilling the Knowledge in a Neural Network(NIPS 2014)中提出了可应用于神经网络模型的知识蒸馏技术。
方法分类
按照待迁移的知识类型,KD主要分为三个大类:
- Output Transfer——将网络的输出(Soft-target)作为知识,常用 Logit Distillation
- Feature Transfer——将网络学习的特征作为知识(特征蒸馏方法如TinyBERT等)
- Relation Transfer——将网络或者样本的关系作为知识
本文主要介绍前两个主流技术:Logits方法及特征蒸馏方法。
BERT 蒸馏
BERT蒸馏方式包括Logit Distillation、特征蒸馏,其它还有 Curriculum Distillation、Dynamic Early Exit: FastBert 等。
从teacher/student模型结构的相似程度来看,可分成两种:
第一种,异构,如从 transformer 到非 transformer 框架的知识蒸馏。
这种由于中间层参数的不可比性,导致从 teacher model 可学习的知识比较受限。但比较自由,可以把知识蒸馏到一个非常小的 model,但效果可能会差一些。
第二种,同构,如从 transformer 到 transformer 框架的知识蒸馏。还可细分为中间层同维度/不同维度。
由于中间层参数可利用,所以知识蒸馏的效果会好很多,甚至能够接近原始 bert 的效果。但 transformer 即使只有三层,参数量其实也不少,另外蒸馏过程的计算也无法忽视。
在业务中选用哪种蒸馏方法,还是要根据真实需求来取舍。
蒸馏方法
Logits蒸馏方法
一般的分类问题最终是通过softmax对logits进行归一化,在计算交叉熵损失时只有正类对应的logit参与损失的贡献,而负类标签被统一对待,但是负类标签对应的概率存在差异较大的情况,这些信息被忽略了。Logits蒸馏方法让student模型的logits(soft target)输出逼近teacher模型的logits以达到近似softmax预测hard target的目的,如最小化MSE: \(L_{student}={1\over 2}\|z_t-z_s\|^2\)。
在这里,Teacher的Logits就是传给Student的暗知识(Dark Knowledge)。
举一个容易理解的例子,MNIST手写数字识别任务中包含0~9的数字图片,通过CNN网络接softmax输出10个类别的概率。比如对于数字2,手写的形状有的像3,有的像7,那么不同的数字2的图片应当有不同的类别概率分布。因此如果只用hard target label去训练,会忽略掉这些细节信息。
既然Softmax抹除了不同负类之间的差异, 那么也可以对Softmax进行改造来弱化两极分化,保留更多的隐含知识。
Hinton在论文Distilling the Knowledge in a Neural Network中提出了称为Softmax Temperature的改进方法,继续采用交叉熵损失而非MSE,并第一次正式提出了“知识蒸馏”的叫法。Softmax Temperature改造了Softmax函数,加入温度系数:
其中超参数 T 是温度,这是从统计力学中的玻尔兹曼分布中借用的概念。如果将T设大,则Softmax之后的Logits数值,各个类别之间的概率分值差距会缩小,也即是强化那些非最大类别的存在感;反之,则会加大类别间概率的两极分化。当T趋向于0时,softmax输出将收敛为一个one-hot向量。当T趋向于无穷大时,softmax损失等价于MSE(当\(T\to \infty\),用 \(1+x/T \to e^{x/T}\)来近似,再加上logits是零均值的假设,可推导出该结论,具体见后文梯度公式推导),也就是拟合概率分布变成了拟合logits。
logits经过Temperature影响的softmax之后得到的输出相当于调节了logits的分布。采用调节后的logits取代one-hot标签,使得负标签对应的非零logits也能参与交叉熵损失的计算。
Hinton论文中让student去拟合调节后的归一化的logits,并同时采用了标准的交叉熵损失作为联合损失的一部分, λ 用于调节蒸馏Loss的影响程度。
注意,Softmax Temperature版的损失的数量级大约是原版的 \(1/T^2\)倍,因此如果想平衡两个损失,可设置 \(\lambda=T^2\)。
在训练新模型的时候,可以使用较高的 T 使得softmax产生的分布足够平缓,这时让新模型(同样温度下)的softmax输出近似原模型;在训练结束以后再使用正常的温度来预测。训练过程中可以设置teacher annealing(退火),逐渐减少teacher暗知识的权重,让student学习到一定程度之后不受teacher的限制。
化学意义
在化学中,蒸馏是一个有效的分离沸点不同的组分的方法,大致步骤是先升温使低沸点的组分汽化,然后降温冷凝,达到分离出目标物质的目的。在前面提到的这个过程中,我们先让温度升高,然后在测试阶段恢复低温,从而将原模型中的知识提取出来,因此将其称为是蒸馏。
适用范围
Logits蒸馏方法约束较少,同时适用于同构或异构的网络结构间的知识传递。异构网络如BERT与LSTM之间,参考 Distilled BiLSTM:Distilling Task-Specific Knowledge from BERT into Simple Neural Networks(2019),该论文提出了通过 BiLSTM 蒸馏BERT的方法,其思想与Hinton原始的logits蒸馏思想一致,蒸馏的结果弱于Bert但是比原始的双向LSTM效果好很多。
Q:为什么蒸馏需要提高温度?
如果T为1,即原始的softmax,当teacher的预测logits两级分化严重时softmax输出与标签接近,那么 student 从蒸馏损失中就学不到额外的信息了。而将T设置<1,则会使两极分化更严重,因此需要设置 T>1。但是T也不能设置地太高,因为logit分值越低越不置信,过高的T反而引入噪声。
Q:student只用soft target损失,不用hard target是否可以?
由于teacher模型一般不能达到完美的模型状态,soft target仅是参考答案,可能存在错误,在传授给student时会将student带偏,而hard target则是标准答案,用来纠错。
Q:如何解释学生网络可能出现比教师网络精度更好的情况?
在学生网络参数量远小于教师网络,并且学生网络不使用额外数据的前提下通常很难超过教师网络的精度,但是不尽然。
- 教师网络过拟合了,学生网络泛化更好(尤其在从多个教师网络学习的情况下,相当于专家系统投票平滑)
- 如果学生网络采用了新数据,那么学生网络学习的数据分布与教师网络不同,通过知识蒸馏,相当于用教师数据的分布对学生网络进行了正则化约束,提高泛化能力。
特征蒸馏方法
让Student学习Teacher网络结构中的中间层特征。最早采用这种模式的工作来自于自于论文:“FITNETS:Hints for Thin Deep Nets”,它强迫Student某些中间层的网络响应,要去逼近Teacher对应的中间层的网络响应。这种情况下,Teacher中间特征层的响应,就是传递给Student的暗知识。
特征蒸馏需要考虑的点包括:
- 中间层的特征选取问题,如一般的DNN隐层、Transformer的Attention矩阵等;还需要考虑从哪些隐层选择用于计算蒸馏损失。
- 损失函数的选择:MSE、交叉熵、KL散度等。
- 以及不同的蒸馏策略,包括同时蒸馏多层、先蒸馏中间层再蒸馏最后一层、逐层蒸馏等。
下面介绍几种典型的蒸馏方法。
BERT-PKD
BERT-PKD (Patient Knowledge Distillation for BERT Model Compression,EMNLP2019) 基于BERT-base蒸馏小型BERT,在中间的某些层上采用归一化的MSE,再结合logits蒸馏方法。关于中间层的选择,提出了两种策略,一种是skip,用BERT-base的第[2,4,6,8,10]层,另一种是last,采用最后第[7,8,9,10,11]层。两种策略实验结果相差不大,skip 策略略好一点(<0.01)。
DistillBERT
多数蒸馏模型是对下游任务进行蒸馏,而 HuggingFace 提出的 DistilBERT, 论文:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter(NIPS2019),则是在预训练阶段进行蒸馏。类似BERT-PKD,将层数减少了一半,基于12层的BERT-base,蒸馏6层的BERT student(用teacher模型参数初始化),同样采用基本的损失函数(输出层的logits softmax交叉熵损失,预训练任务原本的MLM损失),不同之处在于隐层特征蒸馏方式选用的cosine loss,用来调整教师和学生的隐层向量方向。
在该模型中,删除了 token-type embeddings 和 pooler,并保持体系架构其余部分不变,同时借鉴了 RoBERTa 论文中的一些训练技巧。DistilBERT 与 BERT 相比保留了 95%以上的性能,但参数却减少了 40%。
TinyBERT
TinyBERT: Distilling BERT for Natural Language Understanding: (华为诺亚方舟实验室,EMNLP2019)提出了一种两阶段学习框架,包括通用蒸馏和特定任务蒸馏。相当于结合了BERT-PKD和DistillBERT,同时在预训练和微调下游任务后做蒸馏,使得student达到了接近BERT-base的性能效果。TinyBERT对于隐层特征,采用MSE;增加了Attention矩阵logits的MSE损失;增加了输入embedding层的MSE。对于下游任务的微调,做了数据增广来进一步提升蒸馏的效果。
实验设置:预训练阶段只对中间层进行了蒸馏;下游任务微调阶段先对中间层蒸馏20个epoch,再对最后一层蒸馏3个epoch。
在 GLUE 数据集上相对于 BERT-base,其性能并没有下降多少,而推理参数小了 7.5 倍,推理时间快了 9.4 倍。
论文中比较重要的是Attention蒸馏方式,发现 BERT 学习的注意力权重可以捕获大量的语言知识,而在 BERT 的现有知识蒸馏的方法(如 Distilled BiLSTM_SOFT,BERT-PKD 和 DistilBERT)中却忽略了这一点。
为了灵活性,TinyBERT在计算隐层的特征蒸馏损失时采用了一个变换矩阵,旨在将student的特征变换到和teacher相同的空间中。这样TinyBERT支持设计较小特征维度的student网络,而BERT-PKD和DistillBERT的student都是和teacher具有相同的特征维度,只是层数不同。
输入embedding层的MSE同样采用了变换矩阵。
MobileBERT
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices(Google brain,ACL2020)
MobileBERT 首先是在预训练的模型结构上做压缩,借鉴ResNet深层网络中采用的bottleneck结构(即先降维再升维),减少模型的参数量。结构图和参数设置如下,其中图(b)的结构是inverted-bottleneck,思路源自论文Mobilenet-v2: Inverted residuals and linear bottlenecks(2018)。可以看出MobileBERT充分借鉴了之前CV模型中thin&deep的发展路径。
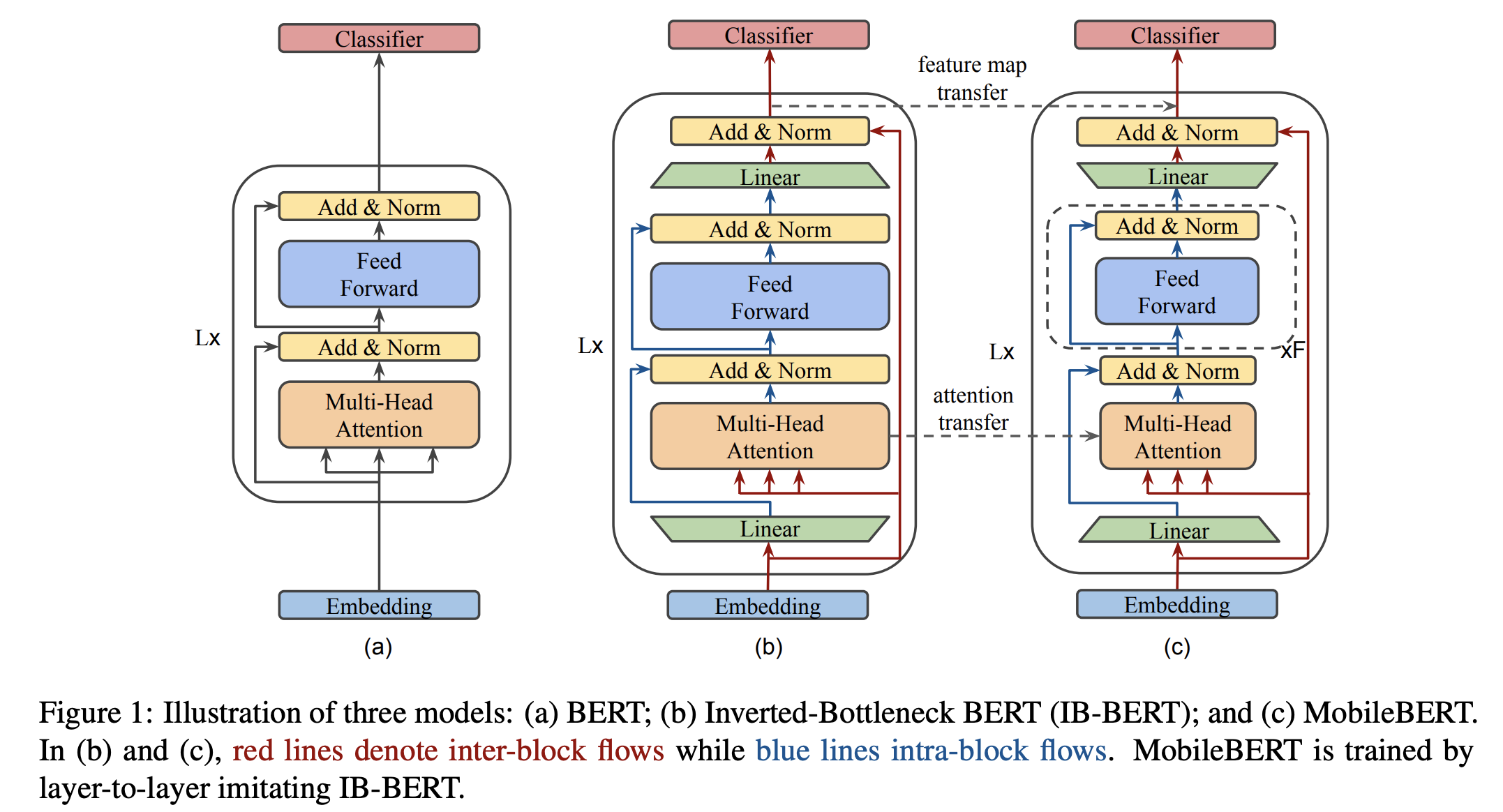
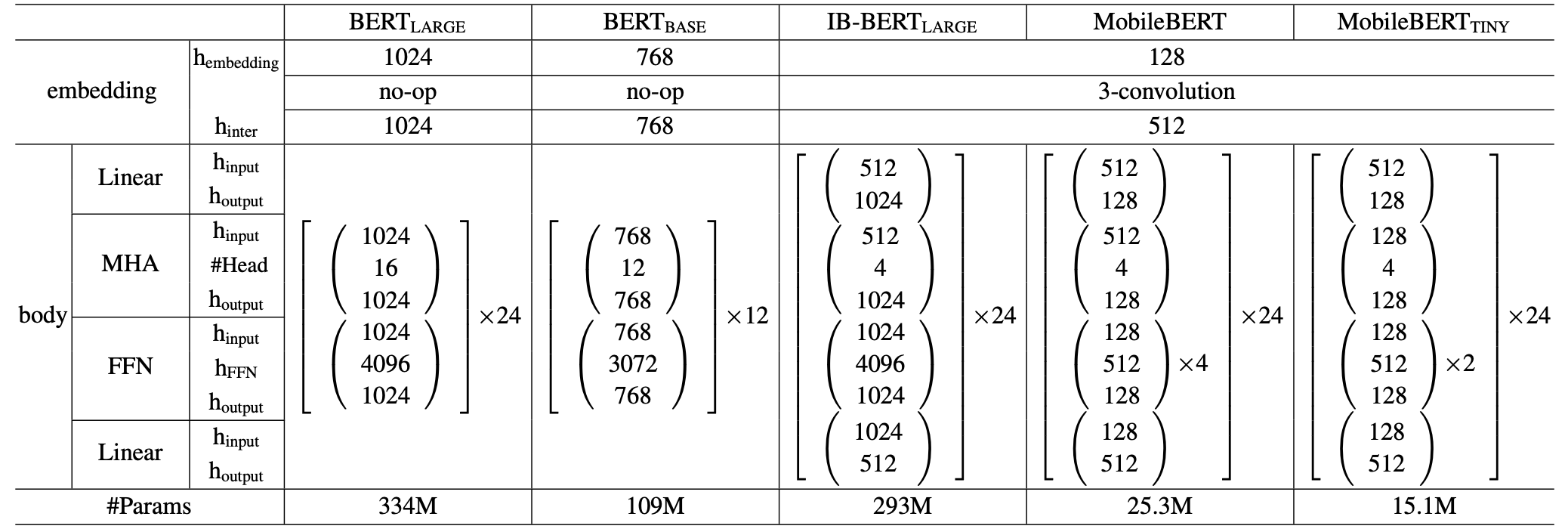
论文对Bottleneck的应用方式是在transformer block的输入输出各加入一个线性层,实现维度的缩放。采用加入inverted-bottleneck的BERT-large作为教师模型,加入bottleneck的相同层数但是维度数减少的BERT作为学生模型。在预训练阶段蒸馏之后,直接用蒸馏预训练模型在下游任务上微调,同DistillBERT。
在BERT中Attention模块之后紧跟FFN来增加非线性,并且每个block中层数比固定为1:2,但在引入bottleneck之后单层FFN的参数量大大减少,继续用2层的FFN非线性能力变弱,因此对FFN模块增加了层数,论文采用了固定值4。
损失函数:预训练任务(MLM+NSP)+中间层MSE+Attention Prob KL散度。
论文实验了不同的蒸馏策略,包括同时蒸馏多层、先蒸馏中间层再蒸馏最后一层、逐层蒸馏,发现逐层蒸馏略胜一筹。
此外,为了在嵌入式移动设备上提速,通过分析算子的执行耗时,选择了替换两个算子:
- LayerNorm -> NoNorm,取消LayerNorm中的normalization,保留线性变换的部分。
- gelu -> relu,减少了erf() 函数的计算。
整体模型的预测耗时对比如下:
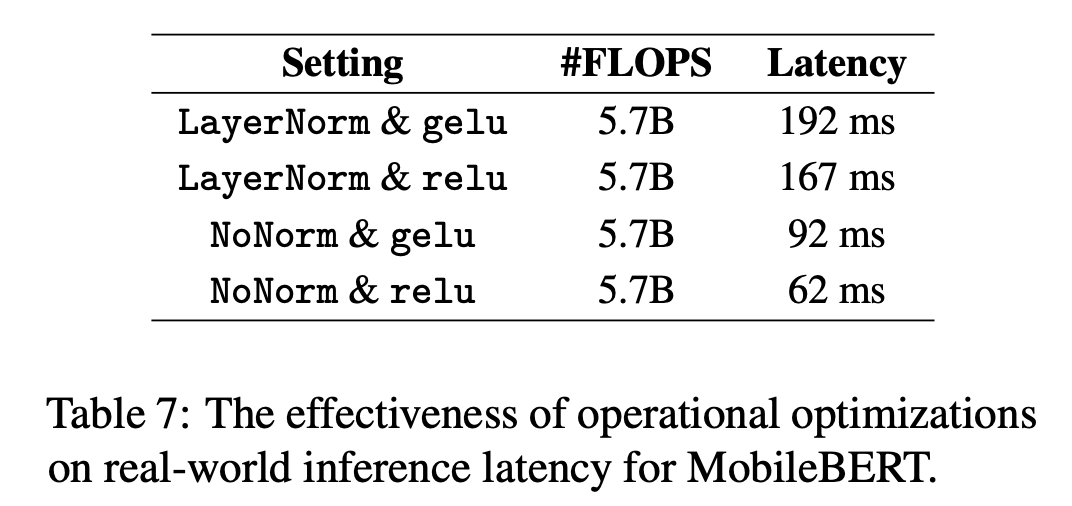
效果:MobileBERT在保留24层的情况下,相比BERT-base减少了4.3倍的参数,速度提升5.5倍,在GLUE上平均只比BERT-base低了0.6个点,在 Pixel 4 手机上运行耗时62ms。
MiniLM
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers(MSRA,2020)
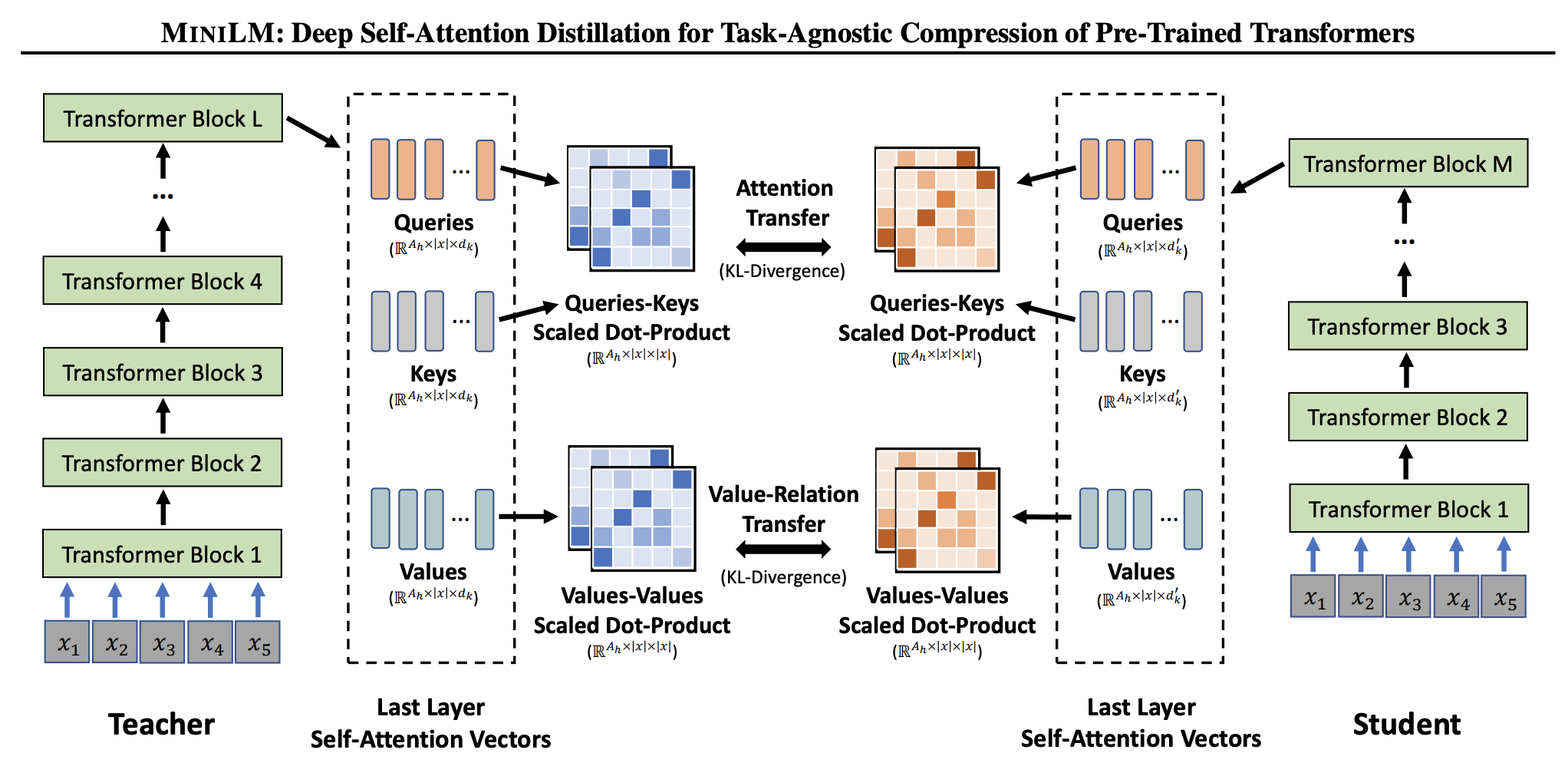
损失函数设计:
- MiniLM也采用了和TinyBERT相同的Attention Prob KL散度损失,但仅应用于最后一层,这样的简化给模型设计带来灵活性,不必在teacher-student layer映射的选择上下功夫。
- 新增一个Value-Relation map的KL散度,计算方式类似Attention的
softmax(Query*Key/sqrt(d)) -> softmax(Val*Val/sqrt(d)),在Transformer encoder中Query、Key、Val是对同一值采用了不同的变换矩阵映射到不同的值,Val-Relation能表示不同token之间的一些关系,用来补充Attention的关系。这里可能欠缺一个可解释性。
Attention和Value-Relation map都是与文本输入长度有关,但与特征维度无关的,因此student可以设置与teacher不同的维度。
MiniLM与UniLM属于同一团队,代码开源在UniLM仓库中。对于生成式任务,可以采用UniLM来做蒸馏。
总结前面介绍的几个模型:
| 任务 | 预训练 | . | . | . | . | 下游任务微调 | . | . | . |
|---|---|---|---|---|---|---|---|---|---|
| 蒸馏方法\layers | Embedding层 | Attention | Value-Relation | 隐层 | 输出预测层 | Embedding层 | Attention | 隐层 | 输出预测层 |
| Distilled BiLSTM | MSE | ||||||||
| BERT-PKD | MSE | CE | |||||||
| DistillBERT | cosine | CE | |||||||
| TinyBERT | MSE | MSE | MSE | MSE | MSE | MSE | CE | ||
| MobileBERT | KL | MSE | MSE | ||||||
| MiniLM | KL | KL |
联合训练方法
除了常规的两阶段分步骤训练的方式(先训练teacher再训练student),还可以像双塔结构一样联合训练。两个网络之间共享底层特征,如embedding lookup特征,相当于右侧网络使用了copy and freeze的特征迁移范式,这样知识蒸馏地可能更充分一些。
这种联合训练方法在论文 "Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net"(阿里妈妈) 中被提出,用于精排模型。
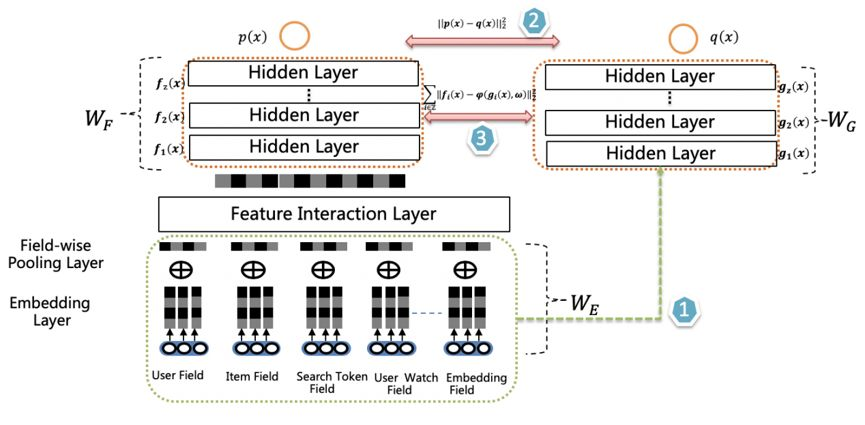
爱奇艺也提出了一种双塔蒸馏的排序模型,相比Rocket Launching,增加了特征蒸馏,即在损失中加入中间层的特征差异。为了增加teacher的复杂度,在输入层后添加了特征交互层(Feature Interaction Layer)。
双DNN排序模型结构如下,由两个DNN CTR Model组成,右侧是Student,Student 模型是最终用于上线推理的CTR 模型。相比 Teacher 模型推理速度提高5倍,模型大小缩小2倍。
参考:
- 知识蒸馏在推荐系统的应用
- 知识蒸馏是什么?一份入门随笔
- 双 DNN 排序模型:在线知识蒸馏在爱奇艺推荐的实践
- 【经典简读】知识蒸馏(Knowledge Distillation) 经典之作
- BERT模型蒸馏完全指南(原理/技巧/代码)
附
标签平滑(Label Smoothing)
标签平滑归一化:Label Smoothing Regularization (LSR)
LSR是一种通过在输出y中添加噪声,实现对模型进行约束,降低模型过拟合(overfitting)程度的一种约束方法(regularization methed)。
one hot存在的问题:
- 丢失了类内、类间关联
- 对于模棱两可的样本表征较差
- 使模型容易学的过于自信,容易过拟合
- 对噪声标签(错误标注数据)敏感
例如采用01标签的训练数据计算交叉熵损失时损失值只与非0项相关,
LSR的优化方式为对“硬目标”进行“软化”,标签平滑的定义为:
将one hot中的0改为 \(\alpha/K\) ,其中K为类别数,1改为\(1-\alpha+\alpha/K\), 总和仍然为1. 超参数α通常取0.1。
简单地说,标签平滑是将真实的one hot标签做一个标签平滑处理,使得标签变成soft label。
软化有什么好处?
从函数曲线来看,约往1靠近,函数值变化越慢,也越难优化(交叉熵损失中的log曲线与sigmoid类似,靠近1时到达饱和区)。通过降低预测目标(soft label),保证优化过程始终处于优化效率最高的中间区域,避免进入饱和区。
适用场景
hinton的这篇[when does label smoothing help? ]论文从另一个角度去解释了 label smoothing的作用:
多分类可能更有效果, 类别更紧密,不同类别分的更开;小类别可能效果弱一些。
注:在知识蒸馏中的teacher模型通常不使用标签平滑。而知识蒸馏方法中采用soft target的方式正好相当于标签平滑。hinton在论文中说了一些原因:标签平滑丢失了一些信息,泛化有利于教师网络的性能,但是它传递给学生网络的信息更少。但是 这篇 ICLR 2021论文 IS LABEL SMOOTHING TRULY INCOMPATIBLE WITH KNOWLEDGE DISTILLATION: AN EMPIRICAL STUDY 提出了不同的观点:标签平滑和知识蒸馏并不冲突,针对不同的场景和任务,需要的teacher类型也不尽相同,但大体上来说,精度越高的网络,通常可以蒸馏出更强的student。
knowledge distillation相比于label smoothing,最主要的差别在于,知识蒸馏的soft label是通过网络推理得到的,而label smoothing的soft label是人为设置的。
原始训练模型的做法是让模型的softmax分布与真实标签进行匹配,而知识蒸馏方法是让student模型与teacher模型的softmax分布进行匹配。直观来看,后者比前者具有这样一个优势:经过训练后的原模型,其softmax分布包含有一定的知识——真实标签只能告诉我们,某个图像样本是一辆宝马,不是一辆垃圾车,也不是一颗萝卜;而经过训练的softmax可能会告诉我们,它最可能是一辆宝马,不大可能是一辆垃圾车,但绝不可能是一颗萝卜。
知识蒸馏得到的soft label相当于对数据集的有效信息进行了统计,保留了类间的关联信息,剔除部分无效的冗余信息。 相比于label smoothing,模型在数据集上训练得到的soft label更加可靠。
参考:
- Google Brain最新论文:标签平滑何时才是有用的?https://www.jiqizhixin.com/articles/2019-07-09-7
- 从标签平滑和知识蒸馏理解Soft Label https://jishuin.proginn.com/p/763bfbd66830
- Müller R, Kornblith S, Hinton G. When Does Label Smoothing Help?[J]. arXiv preprint arXiv:1906.02629, 2019.
- https://cloud.tencent.com/developer/article/1853009
附-Softmax Temperature梯度推导
当\(T\to \infty\),用 \(1+x/T \to e^{x/T}\)来近似,假设logits均值为0,设teacher模型的logit为 \(v_i\),那么有 \(q_i\approx{1+z_i/T\over N}, p_i\approx{1+v_i/T\over N}, {\partial L \over \partial z_i}\approx {1\over NT^2}(z_i-v_i)\). 这等价于最小化MSE:\(1/2 (z_i-v_i)^2\),对\(z_i\)的梯度为 \(z_i-v_i\).
注意到 \({\partial L \over \partial z_i}\approx {1\over NT^2}(z_i-v_i)\)式中分母包含\(T^2\),这也是Softmax Temperature版的损失的数量级大约是原版的 \(1/T^2\)倍的由来。
附-KL散度、交叉熵损失关系
KL散度定义如下
这里的 \(p\) 是真实分布,\(q\) 是预测分布。衡量的是给定分布偏离真实分布的程度,取值范围 \([0, +\infty)\)。KL 散度越小,分布之间的匹配就越好。如果两个分布完全匹配,KL散度为0。
真实分布与预测分布的KL散度等价于两者的交叉熵减去真实分布的信息熵。
- 真实分布 \(p\) 确定的情况下熵 \(H(p)\) 是一个定值,对于模型来说是一个不可优化的常数项,对模型优化没有影响,因此优化交叉熵和优化KL散度(即预测标签的分布与真实标签分布的差异)是等价的,并且对于多分类的one hot标签来说:\(H(p)=0\)。但是当两个分布p、q相等时交叉熵 \(H(p,q)=H(p)\ne 0\),这样损失不为0,模型可能总是保持学习状态。
- 如果目标真实分布是有显著变化的,那么就不适合用交叉熵。比如mini-batch设置为1,那么 \(H(p)\) 会变化较大,而且交叉熵损失会随着mini-batch的变化而振荡。但通常mini-batch不会设太小,真实分布接近不变,不太影响模型的学习。
在蒸馏模型中用KL散度、交叉熵的都有,hinton的logits蒸馏方式正是交叉熵。
蒸馏工具
哈工大讯飞联合实验室的蒸馏工具TextBrewer:airaria/TextBrewer: A PyTorch-based knowledge distillation toolkit for natural language processing

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
