大数据SQL查询
本篇主要介绍几种大数据SQL查询引擎及SQL常用语法,包括 Hive、Presto、SparkSQL 的区别介绍,顺带回顾了一些数据库的理论知识。
查询引擎
主要介绍Hive、Presto、SparkSQL这三个大数据SQL引擎。
Hive
Apache Hive数据仓库软件支持使用SQL读取、写入和管理存放在分布式存储(如HDFS)中的大型数据集。能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive采用元数据记录管理HDFS上存储的底层数据,元数据存储在mysql等关系型数据库中。
官网:Apache Hive
早在2007年, FaceBook为了对海量日志数据进行分析而开发了Hive,随后贡献给Apache Foundation.
Apache Hive 版本众多1.x、2.x、3.x、4.x等,与依赖的Hadoop版本2.x、3.x有关。本文仅介绍一些通用的语法,不对版本的区别做过多介绍。
hive支持 MapReduce、Tez、Spark计算框架,但最常用的还是MapReduce。在Hive 2中使用MapReduce会给出如下提示:
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
SparkSQL
SparkSQL是基于Spark实现的SQL引擎,将SQL转换为 RDD,然后提交到Hadoop集群上运行。Spark RDD主要基于内存,因此执行效率比Hive on MapReduce明显要快。
Spark SQL的特点:
- 和Spark Core无缝集成,可以在写整个RDD应用的时候(例如用scala、python写的应用),配置Spark SQL来完成逻辑实现;
- 统一的数据访问方式(底层存储包括HDFS、Hive、HBase、MySQL等),Spark SQL提供标准化的SQL查询(SparkSQL+HQL);
- 兼容Hive,Spark SQL通过内嵌的hive或者连接外部已经部署好的hive案例,实现了对hive语法(HQL)的继承和操作;
- 标准化的连接方式,Spark SQL可以通过启动thrift Server来支持JDBC、ODBC的访问,将自己作为一个BI Server使用。因此方便被集成到各公司内的大数据SQL平台中。
SparkSQL与Hive on Spark,refer:浅谈Hive on Spark 与 Spark SQL的区别
Hive On Spark大体与Spark SQL结构类似,只是SQL解析引擎不同,但是计算引擎都是Spark。
Hive on Spark是由Cloudera发起,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。通过该项目,可以提高Hive查询的性能,同时为已经部署了Hive或者Spark的用户提供了更加灵活的选择,从而进一步提高Hive和Spark的普及率。Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。而Spark SQL的前身是Shark,是给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,其对Hive有太多依赖(如采用Hive的语法解析器、查询优化器等),2014年Spark团队停止对Shark的开发,将所有资源放Spark SQL项目上。Spark SQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive。
🔺Hive可以处理100PB级别的数据,而Spark不太适合超过这个上限的数据。
Presto
Presto 是一种开源分布式SQL 查询引擎,设计用于对HDFS 和其他源中的数据进行快速交互式查询。
Presto最初是由Facebook开源的分布式大数据SQL引擎,因为一些原因导致原团队分道扬镳,原团队的PrestoSQL改名为 trino,而Facebook通过linux基金会成立了presto基金会,命名为 prestodb。
两种引擎可能在实现上有些不同,但应该有统一的标准。支持多源数据查询,如Hive、Cassandra、关系型数据库的查询。
由于presto基于内存,相比Hive on MapReduce,有明显的速度优势,常用于即席查询。虽然速度快,但是容易遇到内存不足的情况,因此适用于处理的数据量级明显受限。这一点与Spark类似。
Presto vs Hive
语法规范
- Presto采用的ANSI SQL ,即标准的SQL语法。
- Hive 则为 HiveQL,会有一些不同和扩展的地方。
计算架构[1]
- 数据量级:Presto能处理的量较小,Hive则可以处理的量级较大。
- 架构:Hive 采用 map-reduce 架构,将数据写入磁盘,而 Presto 采用 HDFS ,并未采用 map-reduce,基于内存计算. 这与Spark SQL一致,仅能处理在分布式内存中能够放下的数据量,而hive更适合海量数据的处理。
- 跨源:Presto支持跨源查询(join不同来源的数据表,比如社区hive表与非社区hive表),而Hive则仅用于社区hive表查询。
语法差异
数组:
定义方式、数组大小、下标起始编号、越界处理。
hive 定义数组 array (1, 2)
presto 定义数组 array [1, 2] 但是在where语句中presto也可以写成 where val in (val1, val2) 的圆括号形式。
hive size函数:size(split(user_ids,','))
presto cardinality:cardinality(split(user_ids,','))
数组下标:hive的数组index从0开始 presto的数组index从1开始。
数组越界,Hive会当做null处理,而Presto会中断整个查询。在substr(string A, int start, int len)中同样需要注意数组下标从0/1开始的问题。
字符串数据类型:
- hive支持varchar, string. varchar在建表时需要指定最大长度大小,而string不需要。
- presto为varchar,不支持string这个关键字
- sparkSQL中只支持string,☞ https://spark.apache.org/docs/latest/sql-ref-datatypes.html
数字与字符串的比较:保险的做法是写成 var = '2', 不要写成 var = 2, 如果写成后者在presto中是先对变量转换类型为数字型再做比较,如果转换失败就会报错Cannot cast to INT。在hive中则不会报错。
整数除法问题:Presto 除法/运算结果为0的原因及解决方法:
在presto中:两个value相除,至少有一个为浮点数才能返回正确的浮点数结果,否则按照整数除法忽略小数。
而hive中则是按浮点数做的除法,结果没有问题。
解决办法:cast(var as double) 类型转换。cast(value AS type) 为显式转换。
一种trick:把分子乘1.00,结果就会自动保留两位小数,乘1.000就会保留3位。
取余:presto不支持%运算符,需改写为 mode(1, 2)
变量名、函数名的quoting方案:
SQL标准中采用单引号引用字符串常量,如果字符串中存在单引号时可以在字符串内使用转义符或者用两个单引号''来表示单引号。如'teacher''s student'. 数据库软件通常包含对 SQL 的扩展,比如在 MySQL 中允许对字符串使用单引号和双引号两种表示。
反引号:在表名和字段名中如果要想使用保留字,比如desc,需要用反引号来修饰作为普通字符串,如desc.
开启ANSI_QUOTES后,双引号将具有反引号类似的功能,不能再像单引号那样工作。
用一个sql语句来说明presto与hive的区别:
-- 方式一:
SELECT * FROM xx WHERE col='teacher''s student'
-- 方式二:
SELECT * FROM xx WHERE col="teacher's student"
- Presto:方式一可行,方式二会报错
- Hive:方式二可行,方式一不报错但是查询为空
- Mysql:方式一二皆可
常用的hive2presto的字符串改写方式:
改写前:
select `col`
改写后:
select "col"
Presto如果变量名以数字开头,也需要加双引号,如 "1col"
Presto如果函数名包含’.’则需要Quoting,如 "func_a.b"(1)
Presto的字符串常量不能用双引号,需改用单引号:select 'stringLiteral' as col
函数:
- presto的unnest 与hive的 lateral view [outer] explode 类似都是将行进行展开转换为列。
- hive支持cluster by、distribute by、sort by语法,而Presto不支持,其仅支持 order by。
配置
hive资源设置
运行日志中给了reducer的数量设置方式:
[2022-02-28 18:35:28]-hadoop version:2.8.5
[2022-02-28 18:35:28]-hive version:1.2.1.luna.v1
[2022-02-28 18:35:33]-Query ID = xxx_20220228183532_16a14358-a917-4907-a435-08c4a50bc4f1
[2022-02-28 18:35:33]-Total jobs = 2
[2022-02-28 18:35:34]-Launching Job 1 out of 2
[2022-02-28 18:35:34]-In order to change the average load for a reducer (in bytes):
[2022-02-28 18:35:34]- set hive.exec.reducers.bytes.per.reducer=<number>
[2022-02-28 18:35:34]-In order to limit the maximum number of reducers:
[2022-02-28 18:35:34]- set hive.exec.reducers.max=<number>
[2022-02-28 18:35:34]-In order to set a constant number of reducers:
[2022-02-28 18:35:34]- set mapreduce.job.reduces=<number>
livy spark参数设置
Apache Livy 是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。livy最初是由cloudera开发的通过REST来连接、管理spark的解决方案。
Spark SQL可以通过启动thrift Server来支持JDBC、ODBC的访问,将自己作为一个Server提供SQL计算服务。
由于livy也提供了thriftserver模块,所以可以通过livy来提交Spark SQL的计算任务。通过thrift接口创建livy session,将用户sql发送给 livy ,调用spark服务来执行。
可以通过在sql中透传spark sql的参数来设置spark sql引擎的选项。
set `livy.session.conf.spark.speculation`=true;
set `livy.session.conf.spark.sql.adaptive.enabled`=true;
set `livy.session.conf.spark.sql.adaptive.coalescePartitions.enabled`=true;
set `livy.session.conf.spark.dynamicAllocation.enabled`=true;
set `livy.session.conf.spark.dynamicAllocation.initialExecutors`=150;
set `livy.session.conf.spark.dynamicAllocation.minExecutors`=150;
set `livy.session.conf.spark.dynamicAllocation.maxExecutors`=750;
set `livy.session.conf.spark.dynamicAllocation.executorAllocationRatio`=1;
Spark SQL配置参考:https://spark.apache.org/docs/latest/configuration.html
SQL语法
定义与执行顺序
SQL 语句的定义与执行顺序
定义顺序:
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
执行顺序:
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number>
SQL92标准的SQL语句:select foo,count(foo) from pokes where foo>10 group by foo having count(*)>5 order by foo
其执行顺序:FROM ->WHERE ->GROUP BY ->HAVING ->SELECT ->ORDER BY
- from子句来计算关系;
- where子句基于指定的条件对记录行进行筛选;
- group by子句将数据划分为多个分组;
- 使用having子句筛选分组;
- select子句产生查询结果;
- 使用order by对结果集进行排序。
select 语法
参考presto select语法文档 https://prestodb.io/docs/current/sql/select.html
注意,select字段时不要在最后一个字段末尾添加多余的逗号, 否则会报错。
固定列值:
SELECT 'RECOMM_QUERY_BROWSER_FEEDS_BACK' as entry
还可以用类似if else的语法,参考后文对case when then的介绍:
case when col1='xxx' then col2 else NULL end
技巧:select已有的所有列,并添加某些列。注意不同的数据库可能会有不同的写法。
select *, rownum from table (MySQL执行成功,select rownum, * 则会报错)
select rownum, t.* from table t
select rownum, table.* from table (Oracle 11g会报错)
HAVING与WHERE区别
where是在返回结果之前进行过滤,而having是在查询到结果之后进行过滤。having可以使用select as定义的变量名。
过滤条件放在on和where中的区别
join过程可以这样理解:首先两个表做一个笛卡尔积,on后面的条件是对这个笛卡尔积做一个过滤形成一张临时表,如果没有where就直接返回结果,如果有where就对上一步的临时表再进行过滤。
如果是inner join, 那么过滤条件放在on和where中结果没有区别。
如果是左/右连接,则会有区别了,因为on中的条件仅仅用于关联数据表,不会过滤完全,而where是放在最后的,一定会过滤。
参考 https://pigfly88.github.io/mysql/2020/06/30/mysql-on-vs-where.html
SQL 正则、模糊匹配、替换
SQL的模糊匹配区别---like,rlike,regexp
like关键字是通配符匹配有两个模式:_和%
_:表示单个字符,用来查询定长的数据
%:表示0个或多个任意字符
rlike的内容可以是正则,regexp == rlike 同义词,支持 ^、$、| 等,也支持like的%.
rlike用法有两种:
where var rlike '[0-9]'
where rlike(var, '[0-9]')
hive 中没有not like 而是用 not col_name like '%a%' 或者not col_name rlike 'a' 这种写法。
注:在presto中没有rlike这个名称的函数,而是regexp_like(var, pattern),并且转义方案不同,如hive写法:
RLIKE( '1 2', '\S'),在presto中写法:regexp_like( '1 2', '\S')
presto也支持like,用法相同。
正则模式参考 https://www.runoob.com/mysql/mysql-regexp.html
| 模式 | 描述 |
|---|---|
^ |
匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| ` | 模式 |
| ----- | ----- |
^ |
匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
|匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
|
. |
匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像 '[.\n]' 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
p1│p2│p3 |
匹配 p1 或 p2 或 p3。 |
* |
匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 | |
| m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
正则替换
regexp_replace(string, pattern, replacement)
presto、hive、spark sql通用。例如,删除字符串s中的大括号:regexp_replace(s, '\\{|\\}', '')
参考 presto正则
子查询
子查询(sub-query)是这种嵌套格式的:
SELECT ... FROM (SELECT ... FROM <table_name> WHERE <conds>) WHERE ...
然而这样写可读性极差,可用视图(VIEW)解决,也可用 WITH ... AS ... 子句来解决。
WITH <temprary_table_name> AS (SELECT ... FROM <table_name> WHERE <conds>)
WITH ... AS ... 可以同时创建多个临时表:
WITH t1 AS (
SELECT foo, bar
FROM tb1
WHERE <conds>
),
t2 AS (
SELECT baz
FROM tb2
WHERE <conds>
)
SELECT
t1.foo,
t2.bar,
t3.baz
FROM
t1 INNER JOIN t2 ON <conds>
WHERE
<conds>;
SQL View 和 with 子句非常相似。这里有一些区别。
View 在数据库中创建了一个实际对象,具有相关的元数据和安全功能。 With 语句只是单个查询的一部分。
在标准的数据库中,如hive,Oracle,DB2,SQL SERVER,PostgreSQL都是支持WITH AS 语句进行递归查询。只有MySQL是不支持的。
在hive sql 中使用子查询时,需要在每个子查询后面加别名,否则报错。
在子查询中也可以使用with..as, 即可以嵌套定义。
join
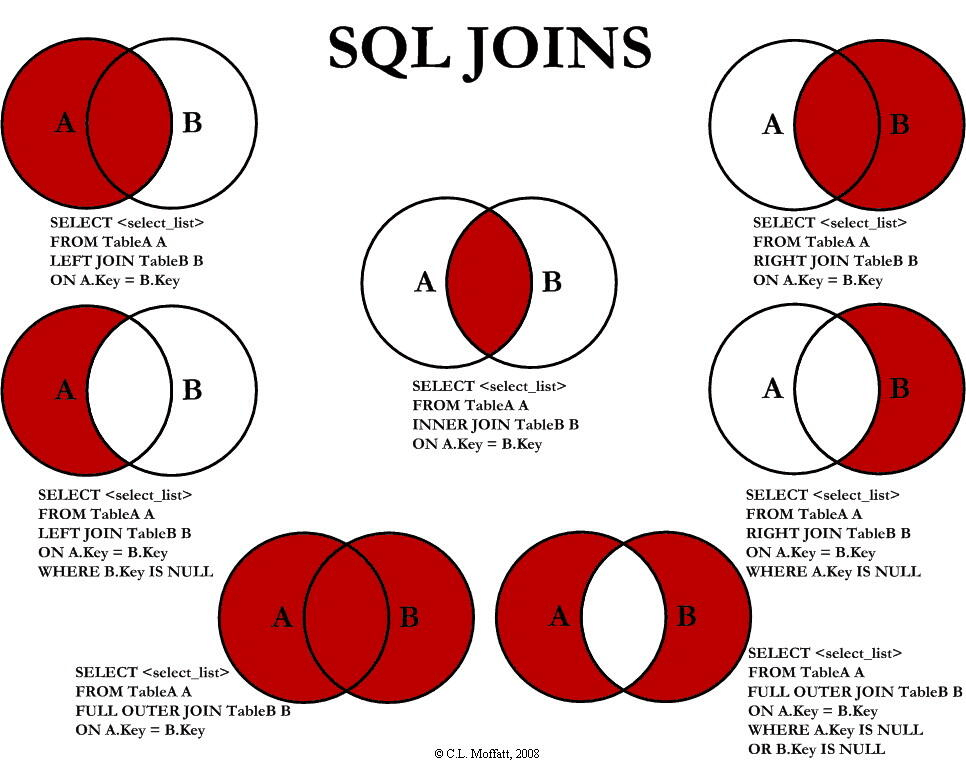
join的类型如上图所示,不写join的类型的话默认是inner,内连接。
CROSS JOIN 又称为笛卡尔乘积,实际上是把两个表乘起来,n x m的组合。
两种写法:
SELECT *
FROM [TABLE 1]
CROSS JOIN [TABLE 2];
SELECT *
FROM [TABLE 1], [TABLE 2];
实际是一种完全组合,返回结果是TABLE 1的每行依次跟TABLE2的每行拼接输出,比如TABLE 1有n行,TABLE 2有m行,输出有nm行。
参考:
- https://www.runoob.com/sql/sql-join.html
- https://www.cnblogs.com/chenxizhang/archive/2008/11/10/1330325.html
union
union和union all关键字都是将两个查询结果并为一个,但这两者从使用和效率上来说都有所不同。
使用 union 组合查询的结果集有两个最基本的规则:
- 所有查询中的列数和列的顺序必须相同。
- 数据类型必须兼容
union在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。如:
select * from test_union1
union
select * from test_union2
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
而union all只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
从效率上说,union all要比union快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用union all。
group by
可以用逗号组合多个列名来分组。分组后可以使用max、sum等统计函数。
注意group by后select出来的数据不能保证有序,SQL specs中并未对是否保证有序做限制。而MySQL、Microsoft SQL Server的结果是有序的,其它数据库软件则不能保证。
因此如果想保证有序,最好和order by一起使用。
在group by的时候要注意数据倾斜的问题,比如某个字段有大量数据是null或者'', 在采用hive执行sql的时候map reduce由于数据倾斜,某些worker耗时会很久。最好在where中过滤掉WHERE xx IS NOT NULL AND xx <> ''
还有join语句也是,最好在select时用where过滤掉任何不相干的计算,减少耗时。
order by
ORDER BY 也支持逗号组合多个列名,按照顺序进行排序,
如ORDER BY column1 DESC, column2
二次排序:主按column1降序排序,其次按column2升序排。
窗口函数
窗口函数有以下功能:
1)同时具有分组和排序的功能
2)不减少原表的行数
语法如下:
<窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名>)
SQL中通过调用over()函数,我们可以生成一个窗口(基于SQL查询的全部结果)。over函数内部支持如下参数:
- partition by <分区列名>;
- order by <列名 [asc|desc] ,用于指定分区内的数据的排列先后顺序>;
- <range|rows> between <滑动窗口的上边界> and <滑动窗口的下边界> 用于指定滑动窗口的大小。
语法解释
<窗口函数>的位置,可以放以下两种函数:
1) 专用窗口函数,如rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum, avg, count, max, min等
- 当over函数内的参数为空时,整个结果集就是一个分区(不指定partition by)。滑动窗口的大小也是整个结果集。
- 当order by不指定的时候,记录行(rows)使用默认的顺序,也就是从数据库查询出来的顺序。因为窗口函数在order by语句之前执行,所以顺序只能是默认的顺序。在此我强烈建议窗口函数都带上order by从句,否则结果列可能会是不确定的值。MySQL可以支持不带order by,但在Oracle和SQL Server上,指定滑动窗口时,必须带上order by,否则就会报错。
- 当没有指定滑动窗口大小的参数时,即没有指定range或者rows从句,滑动窗口的默认大小为:上边界=分区的第一条记录,下边界=当前记录。
窗口函数具备了我们之前学过的group by子句分组的功能和order by子句排序的功能。那么,为什么还要用窗口函数呢?
这是因为,group by分组汇总后改变了表的行数,一行只有一个类别。而partition by和rank函数不会减少原表中的行数。
窗口函数只能用在select语句中,用于在查询列表里新增一个列,多个窗口函数之间互不影响。
执行阶段:晚于from、where、group by、having的执行,早于order by、limit、select distinct的执行。
滑动窗口语法
滑动窗口(Frame)是基于当前行的,它有一个上边界和一个下边界,滑动窗口不能脱离partition独立存在。当指定了partition by和order by,而不指定滑动窗口时,滑动窗口默认的上边界为partition内第一条记录,下边界为当前记录。每一行记录都有一个滑动窗口。
指定滑动窗口的时候,必须是已经有了partition by从句,否则SQL会报错。虽然MySQL8支持,但是不建议你这样使用。当over函数里面没有partition by从句和滑动窗口从句时,默认的滑动窗口就是整个结果集。
滑动窗口大小支持两种模式,range模式和rows模式。
- rows模式
rows between N preceding and M following, 滑动窗口的构成以当前逻辑行为基准点,向上指定N行(逻辑行)为上边界,向下指定M行(逻辑行)为下边界。 - range模式(注意:range 模式必须指定order by从句)
range between N preceding and M following,滑动窗口的构成以当前逻辑行为基准点,值是order by从句中使用的列的值。
上边界 :当前逻辑行之前 值 >= 当前逻辑行的值 - N 的所有逻辑行
下边界 :当前逻辑行之后 值 <= 当前逻辑行的值 + M 的所有逻辑行
边界常量
- unbounded preceding:表示分区内第一条记录(逻辑行),不管是否指定order by从句。
- unbounded following:表示分区内最后一条记录(逻辑行),不管是否指定order by从句。
- current row:字面意思是当前行,在rows模式下,表示当前逻辑行。在range模式下,表示在当前逻辑行前后,值和当前逻辑行的值相等的所有逻辑行(range模式下指定了order by,值都是有序的)。
- N preceding和N following:参考range和rows模式里面的解释,分别表示往前N行的数据和往后N行的数据。
操作函数
当over函数指定了窗口之后,需要操作函数对分区内(partition)或者滑动窗口内(Frame)的数据进行操作。
窗口函数分为聚合函数和非聚合函数。聚合函数处理数据大部分都是基于滑动窗口的。非聚合函数处理数据有基于滑动窗口的,也有基于分区的。下表是常用的操作函数,另外不同的数据库还会实现自身特有的操作函数。
窗口函数列表:
| 函数名称 | 功能 | 类别 | 操作范围 | 备注 |
|---|---|---|---|---|
| AVG | 求平均数 | 聚合函数 | 滑动窗口 | 求滑动窗口内的所有值的平均值 |
| COUNT | 统计记录 数 | 聚合函数 | 滑动窗口 | 统计滑动窗口内的记录数, 参数 null值会忽略掉 |
| MAX | 找最大值 | 聚合函数 | 滑动窗口 | 找出滑动窗口内的最大值 |
| MIN | 找最小值 | 聚合函数 | 滑动窗口 | 找出滑动窗口内的最小值 |
| SUM | 计算累加和 | 聚合函数 | 滑动窗口 | 计算滑动窗口内所有值的累加和 |
| FIRST_VALUE、 LAST_VALUE |
当前滑动窗口内第一条/最后一条记录的值 | 非聚合函数 | 滑动窗口 | 当前滑动窗口内第一条/最后一条记录的值 |
| DENSE_RANK | 当前行在分区内的排名 | 非聚合函数 | 分区 | 计算当前行在分区内的排名,排名之间没有间隔 |
| RANK | 当前行在分区内的排名/后数n行对应行的值 | 非聚合函数 | 分区 | 计算当前行在分区内的排名,排名之间有间隔 |
| LAG/LEAD | 当前行往前/后数n行对应行的值 | 非聚合函数 | 分区 | 计算当前逻辑行的前面/后面第N逻辑行的值, 如果当前行之前/之后没有 N 行, 返回null, N默认值为1 |
| ROW_NUMBER | 当前记录在分区内的行号 | 非聚合函数 | 分区 | 值从1开始,order by指定排序方式 |
示例:
SELECT name,val,
row_number() over(partition by name order by val desc) num,
val - first_value(val) over(partition by name order by val desc) diff,
dense_rank() over(partition by name order by val desc) rnk
FROM names
row_number() 在每个window partition上按照指定方法排序后分配一个id(从1开始),不同partition之间编号会重复;如果不指定partition by的方式,则进行全局编号(全局唯一)。
窗口函数在多数SQL引擎中均支持,但具体到语法要求可能不同,如在Spark SQL中row_number()要求必须在over()中指定order by语句,而PostgreSQL、hive则不要求(但是hive似乎仍然会只在一个executor上执行,速度依然很慢)。
Window function row_number() requires window to be ordered, please add ORDER BY clause.
For example SELECT row_number()(value_expr) OVER (PARTITION BY window_partition ORDER BY window_ordering) from table;'
窗口函数如果不指定partition by方式,都会放在一个节点上执行,在spark中会给出提示:
WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
简洁教程:通俗易懂的学会:SQL窗口函数
INSERT OVERWRITE TABLE
insert overwrite是删除原有数据然后在新增数据,如果有分区那么只会删除指定分区数据,其他分区数据不受影响。
分区相当于分库分表的概念,不过是在一个表内的存储分区的概念。
在venus上建的表都有分区,因此insert时也需要指定分区:
INSERT OVERWRITE TABLE table PARTITION(ds=%YYYYMMDDHH%)
二者的区别是:
insert into:直接向表或静态分区中插入数据。您可以在insert语句中直接指定分区值,将数据插入指定的分区。insert overwrite:先清空表中的原有数据,再向表或静态分区中插入数据。
字段名与类型
insert的时候注意数据字段字段名称要对应,类型要对应,如果是整数,则可能出现 int 与 bigint 不匹配的问题。
Presto 函数
UNNEST
Presto引擎包含UNNEST 函数,而hive中不含,hive、sparkSQL中等价的函数是 lateral view [outer] explode, 都会创建别名虚表, 将一行数据拆分成多行数据。
比如一行数据是逗号分隔的多个字符串,用split(str, ',')可转换为ARRAY。
UNNEST 将 ARRAY 或 MAP 转换为relation关系,通常与JOIN一起使用。
例子参考:https://prestodb.io/docs/current/sql/select.html
-- presto
SELECT student, score
FROM tests
CROSS JOIN UNNEST(scores) AS t (score);
-- hive
SELECT student, score
FROM tests
lateral view explode(scores) t as score
posexplode相比explode给出了下标,这在同时explode两个字段并需要一一对应时可以用到。
在presto中等价的写法是 CROSS JOIN UNNEST(array/map) WITH ORDINALITY AS b (item, n)
如果是map,则后边可以是(key,value)
可以在UNNEST(arr1, arr2)中写两个array,展开成(arr1_item, arr2_item)
-- 例子,两列col_as,col_bs均为逗号分隔的字符串(a_1,a_2,...),希望转换为多行数据:a_i, b_i
SELECT
pos_a.a_val,
pos_b.b_val
FROM
table_name
lateral view posexplode(split(col_as, ',')) pos_a as a_idx,a_val
lateral view posexplode(split(col_bs, ',')) pos_b as b_idx,b_val
WHERE
a_idx=b_idx
参考:
- https://stackoverflow.com/questions/51839233/what-is-the-equivalent-of-presto-unnest-function-in-hive
- https://theleftjoin.com/how-to-explode-arrays-with-presto/
其它函数
String Functions:https://prestodb.io/docs/current/functions/string.html
Binary Functions:https://prestodb.io/docs/current/functions/binary.html
from_utf8(binary) → varchar#
Decodes a UTF-8 encoded string from binary. Invalid UTF-8 sequences are replaced with the Unicode replacement character U+FFFD.
from_base64(string) → varbinary#
Decodes binary data from the base64 encoded string.
在hive中对应unbase64()
presto常用用法:from_utf8(from_base64(var)),hive或者SparkSQL则直接写unbase64(var)
随机采样
presto
在presto中可以使用 TABLESAMPLE BERNOULLI 独立二项分布采样一定的比例: 扫描全表,对每条数据以指定概率选择是否被select。
参考代码:from blog
WITH dataset AS (
SELECT *
FROM (
VALUES
(1, 'A'), (2, 'B'), (3, 'C'), (4, 'D'),
(5, 'A'), (6, 'B'), (7, 'C'), (8, 'D'),
(9, 'A'), (10, 'B'),(11, 'C'),
(13, 'A'),(14, 'B'),(15, 'C'),
(17, 'A'),(18, 'B'),(19, 'C'),
(21, 'A'),(22, 'B'),
(25, 'A'),(26, 'B')
) AS t(number, letter)
)
SELECT *
-- assuming we want to sample 25% of records
FROM dataset TABLESAMPLE BERNOULLI(25)
hive
hive的对应写法:SELECT * FROM source TABLESAMPLE(BUCKET 3 OUT OF 4 ON rand()) s
TABLESAMPLE 将数据打散到(out of) N个桶中,对桶编号1~N,指定select 第i个桶中的数据返回,ON指定按哪个字段来分桶,这里用rand()是对整行随机分桶。这个代码中选择第3个桶的数据,同样是抽取了25%的数据。
从Hive 0.8开始引入了TABLESAMPLE (n PERCENT)支持对HDFS的 block 进行采样,百分比指的是数据大小size的百分比,而非行数的百分比。由于HDFS有最小块大小的要求,比如256MB,那如果实际数据小于256MB,按这个方式采样会多采样。尚不清楚什么情况下会用这个block采样。
QA
为什么这些采样都是指定比例或者只能在每个partition上指定数量,而不能指定最后的总量?
猜测因为无法提前知道总数量(需要遍历一遍才能知道),但是可以自己加LIMIT来限制最后的总量。
rand大法
随机选取数据,可以用RAND()函数。在hive中存在 cluster by、distribute by、sort by 可以按随机数来划分、排序数据。
- ORDER BY RAND(),注意如果不是仅在主键上随机选取,速度会相对比较慢,因为ORDER BY是全局排序,在hive查询引擎中会放在一个reducer上执行(而spark的全局排序有优化,在每个计算节点对部分数据排序后最终再放在一个reducer上执行全局的排序,效率应该比hive的高一些)。注:order by中不支持聚合函数,如COUNT(col),但支持引用select语句的别名(如select col as alias_name)。标准SQL语句。
- SORT BY RAND(),与 order by 的区别是将全部数据划分到多个reducer后在每个reducer内排序,属于局部排序。数据划分的过程不是全局随机的。非标准SQL语句。
- DISTRIBUTE BY RAND() 表示全局shuffle数据,分给reducer。在每个reducer上可以继续使用 SORT BY RAND() 来做排序,得到真正随机的采样数据。再次使用sort by是因为如果原始数据有序,在distribute之后每个reducer上仍然保持有序。非标准SQL语句。
- cluster by = distribute by + sort by. 当distribute by 和 sort by 所指定的字段相同时,即可以使用cluster by。
注意:presto不支持 cluster by、distribute by、sort by 语法, 支持order by。
随机采样万分之一并限制1w条:
select * from my_table
where rand() <= 0.0001
distribute by rand()
sort by rand()
-- cluster by rand()
limit 10000;
这与TABLESAMPLE BUCKET 比较像,都有分桶。
参考:
- https://hadoopsters.com/2018/02/04/how-random-sampling-in-hive-works-and-how-to-use-it/
- RANDOM SAMPLING IN HIVE http://www.joefkelley.com/736/
- https://www.quora.com/How-do-I-randomly-sample-data-in-Hive
类型转换
CAST(from_datatype as to_datatype)
对于数字,可以对字符串、整数、浮点数互相转换
浮点数 float, double。
整数 int, decimal (会四舍五入)
NVL函数
NVL函数是一个空值转换函数NVL(表达式1,表达式2)
如果表达式1为空值(NULL),NVL返回值为表达式2的值,否则返回表达式1的值。
例子:nvl(col1, '') 即当col1列对应的值为NULL时替换为空字符串。
substr
字符串取子串
substr(s, start, end), 取下标[start, end]的子串。
用法示例:GROUP BY substr(cast(ds as varchar), 1, 8)
log
LN( double n ) 自然对数
log10(double a)
log2(double a)
log(double base, double a)
pow(double a, double p)
between and
合并一天的所有小时数据:
WHERE ds between %YYYYMMDD%00 and %YYYYMMDD%23
语句中%YYYYMMDD%需要替换为真正的值。
case when then
类似C语言的switch case的用法:
需要注意的是从上往下遇到第一个满足条件的when语句则会返回,不再查找后续结果。
--简单case函数
case gender
when '1' then '男'
when '2' then '女’
else '其他' end
--case搜索函数
case when gender = '1' then '男'
when gender = '2' then '女'
else '其他' end
常见问题
报错1:ParseException line ... cannot recognize input near '' '' '' in ...
有几种可能:
- 在hive sql 中使用子查询时,需要在每个子查询后面加别名,否则报错。
- 报错的行周围存在特殊字符,比如引号写成了中文,单引号写成了双引号之类的。比较重要的一点,分号
;是sql的结束符,在hive进行解析时会出错,比如split(str, ';')即便用引号引起来也会报错,需要用分号的二进制\073来表示,改为split(str, '\073')。注意在presto引擎中没有遇到这个分号解析错误的问题,估计是解析器做了处理。还见过一种hive中的写法:'\;' 可能也是可行的,不太确定。
注意:在 SparkSQL 中执行sql语句时不能在末尾添加分号;否则会有对应的报错提示。
报错2:Expression not in GROUP BY key
在hive的 Group by 子句中,Select 查询的列,要么需要是 Group by 中的列,要么得是用聚合函数(比如 sum、count 等)加工过的列。不支持直接引用非 Group by 的列。这一点和 MySQL 有所区别。
一种解决办法:使用collect_set(...)[0]包围非group by字段后,问题解决。collect_set函数收集这些字段,返回一个数组。
部分行出现列错位的排查思路:Hive insert 字段表错位踩坑
对于textfile类型存储的hive表,其数据以指定的列分隔符和行分隔符明文存储到hdfs上,如果某些列包含了分隔符则会导致列错位。
比如 insert overwrite table A select * from table B, 是按B表的分隔符解析之后将字段按A表的分隔符拼接后再输出到A表的hdfs文件。社区hive的默认分隔符是\001(vim中显示为^M, 可通过ctrl+a来输入),而venus上创建hive表时默认是|。
建议:Hive 表尽可能使用 orc parquet 这类存储方式,空间占用,查询效率相对 textfile 有大幅提升,同时可以规避字段分隔符,错位等问题。
数据库理论
ACID
数据库事务的四大特性(ACID)^acid:
⑴ 原子性(Atomicity): 原子操作不可再分割,要么执行成功,要么失败
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,这和前面两篇博客介绍事务的功能是一样的概念,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
⑵ 一致性(Consistency): 数据库在事务执行前后都保持一致性状态。
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
⑶ 隔离性(Isolation): 多个并发事务之间要相互隔离, 一个事务所做的修改在最终提交以前,对其它事务是不可见的。
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
⑷ 持久性(Durability): 永久存储
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
数据库隔离级别由低到高依次为未提交读(Read-Uncommitted),已提交读(Read-Committed),可重复读(Repeatable-Read)和串行化(Serializables)。一般的关系型数据库的默认级别就是已提交读,该隔离级别避免了脏读。已提交读级别只允许事务读取已经被其他事务提交的修改。
范式
关系数据库设计理论中的范式理论:
高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
- 第一范式 (1NF)
属性不可分。 - 第二范式 (2NF)
每个非主属性完全函数依赖于键码。
可以通过分解来满足。 - 第三范式 (3NF)
非主属性不传递函数依赖于键码。 - BCNF范式: 排除了任何属性(不光是非主属性,2NF和3NF所限制的都是非主属性)对候选键的传递依赖与部分依赖。(即排除主属性依赖于非主属性的情况)
- 第四范式 :已经是BC范式,并且不包含多值依赖关系。
- 第五范式处理的是无损连接问题,这个范式基本没有实际意义,因为无损连接很少出现,而且难以察觉。
列式存储
我们以前常见的关系型数据库大多采用 行存 格式,即按行存储与查询。而在一些场景下用 行存(column-oriented) 会更加高效,如在数据分析系统中,列存经常是首选。
行式存储可以看成是一个行的集合,其中每一行都要求对齐,而列式存储则可以看成一个列的集合。行式存储擅长插入、更新,而列式存储一般适用于数据为只读的场景。业务场景只是查询(没有增删改),那么列式存储将带来极其可观的性能提升。
对于关系型数据,将一个记录的多列连续的写在一起。如对于(姓名,年龄,性别)三列数据的列式存储形式为:
| 赵 | 钱 | 孙 | 李 | 周 | 25 | 26 | 27 | 28 | 27 | 男 | 女 | 男 | 女 | 男 |
而对于嵌套数据,如protobuf数据格式中存在repeated、optional修饰的字段属于嵌套数据,则不能直接采用连续存储的这种简单形式,需要额外的字段存储其完整的信息,例如Google Dremel采用两个变量R (Repetition Level) 、D (Definition Level)来存储。
使用列存的常见原因:
- 是可以避免读取不需要的列,通常读取时只读取某几列,如果采用行存,那么要读取所有的列。因此通过列存可以降低 I/O . 对于列的聚合分析(计数、求和等统计操作)非常迅速,优于行式存储。
- 高压缩比。由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。每列的相似数据可以进行编码替代,如用0和1分别表示男女,岁数采用差值去存储,能够节省空间,同时能够降低 I/O .
列存开源实现
- Google Dremel论文《Dremel: Interactive Analysis of Web-Scale Datasets》提出了列式存储与多级执行树,其开源实现比较多:
- 实现 Dremel 的嵌套列式存储,如 Apache Parquet、Apache ORC。Parquet 支持几乎 Hadoop 生态圈的所有项目;ORC 提供 ACID 支持、也提供不同级别的索引,如布隆过滤器、列统计信息(数量、最值等),ORC 与 Presto 配合使用效果比较好。
- 实现 Dremel 的多级执行树查询架构,如 Apache Impala、Aapche Drill 与 Presto。
- Apache CarbonData
由华为开源的列式存储,专门为海量数据分析和处理而设计,配合Spark使用,性能很好。非 Dremel 系列。 - ClickHouse
是Yandex开源的列式存储数据库管理系统,用于高性能数据分析(online analytical processing of queries , OLAP)。基于磁盘与内存,不支持事务。Clickhouse没有走hadoop生态,采用 Local attached storage 作为存储。采用C++编写,利用多核并行处理,可以充分利用硬件优势。[2]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
