RNN 基础
RNN
RNN中循环应用如下公式在每步中处理序列x:
在每一步中使用的都是相同的\(f_W\),h'和h具有相同的维度.
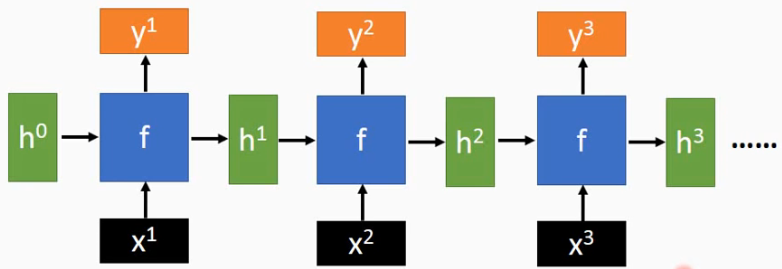
RNN的一般形式:
其中的\(\sigma\)可以是softmax(得到概率值):
RNN的一个优势是可以应对变长的输入和输出.
使用训练好的RNN进行测试时,如预测一个字符的后续序列采用sample而不是直接使用softmax的最大score的结果,是因为不同的序列可能有相同的前缀,进行sample可以增加预测结果的多样性.
基本的RNN原理简单,但是表现并不好.常使用LSTM和GRU,这两者所设计的additive interaction(联动)能够改善梯度的流动性.RNN的梯度爆炸可以通过梯度裁剪解决,而梯度消失通过additive interaction.
为什么RNN并行计算能力比较差?
因为隐藏单元的计算是串行的,依赖于前一个的计算,即 \(S_t=f(U\cdot X_t+W\cdot S_{t-1})\)。
如何改造RNN使之并行化?
- 隐层神经元之间并行化,Simple Recurrent Units for Highly Parallelizable Recurrence”中提出的SRU方法,本质的改进是把隐层之间的神经元依赖由全连接改成了哈达马乘积,这样T时刻隐层单元本来对T-1时刻所有隐层单元的依赖,改成了只是对T-1时刻对应单元的依赖。它的问题在于其并行程度上限是有限的,并行程度取决于隐层神经元个数,而一般这个数值往往不会太大。
- 类CNN:如Sliced RNN,将RNN打断成片段(如每两步打断一次)再通过层深来建立远距离联系,形式上很像跳表。片段之间的组成类似CNN并行,而片段内部仍然保持串行。
from RNN to LSTM 过渡
对RNN来说,需要使用通过时间的反向传播(BPTT)来训练,但是由于梯度消失(或爆炸)的问题,它经常导致较差的结果。

解决这一问题的一种方法是使用门控逻辑(类似ResNet),不把梯度相乘,而是把它们相加,如下所示:
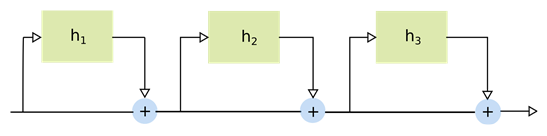
这种累加的方式由于引入了门控逻辑,其将隐藏层的输出与每个时间步的原始输入相加,从而减少了梯度递减的影响。这种门控架构构成了新型RNN(LSTM等)的基础。
典型的LSTM单元包括三个主要功能:
- 重置记忆(reset)
- 写入记忆(write)
- 读取记忆(read)
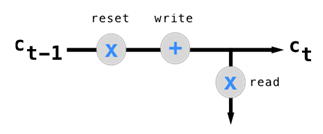
完整的LSTM单元结构如下:
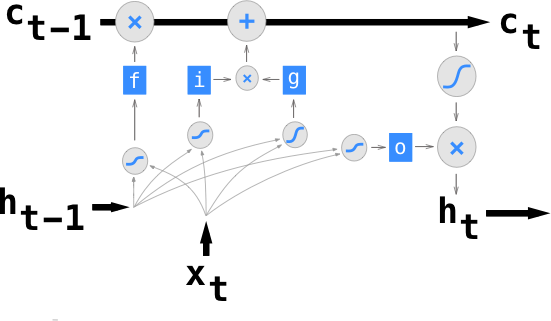
四个网关f,i,g,o的每一个都以前一个时间步的隐藏状态和当前时间步的输入为输入。
长短期记忆网络LSTM
相比普通的RNN增加了具有长期记忆的变量c作为输入,c改变较慢,而h改变较快.
LSTM的计算方式是将\([X^t,h^{t-1}]\)合并为一个矩阵后与权重W相乘再经过激活函数得到\(Z,Z^i,Z^f,Z^O\), 对应LSTM 内部的三个门控单元: 选择记忆门(information gate,也可简单理解成输入门)、遗忘门(forget gate)、输出门(output gate)。三个门均采用sigmoid得到(0,1)之间的gate值,而对于选择记忆门采用了tanh来得到当前输入,缩放区间(-1,1)。
输出的计算方式为:
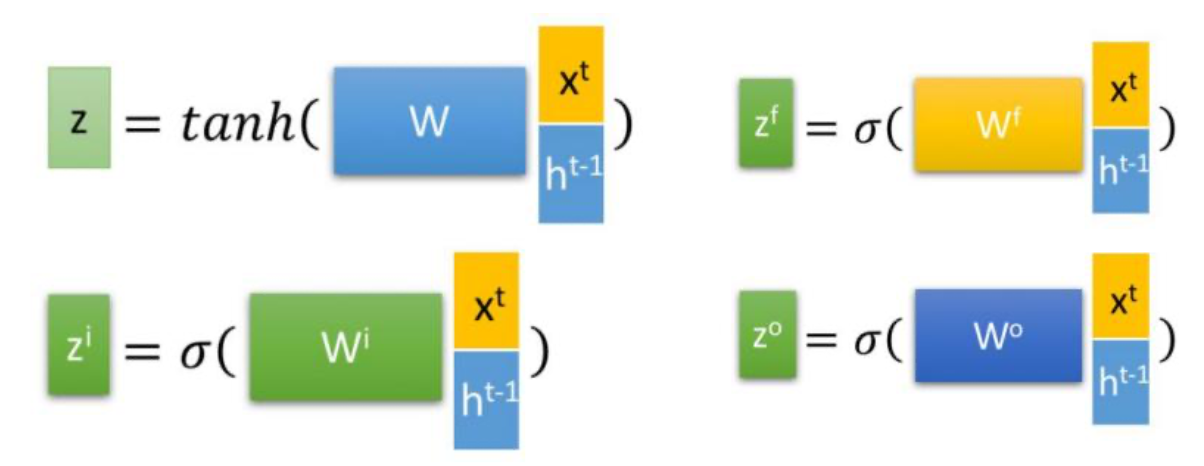
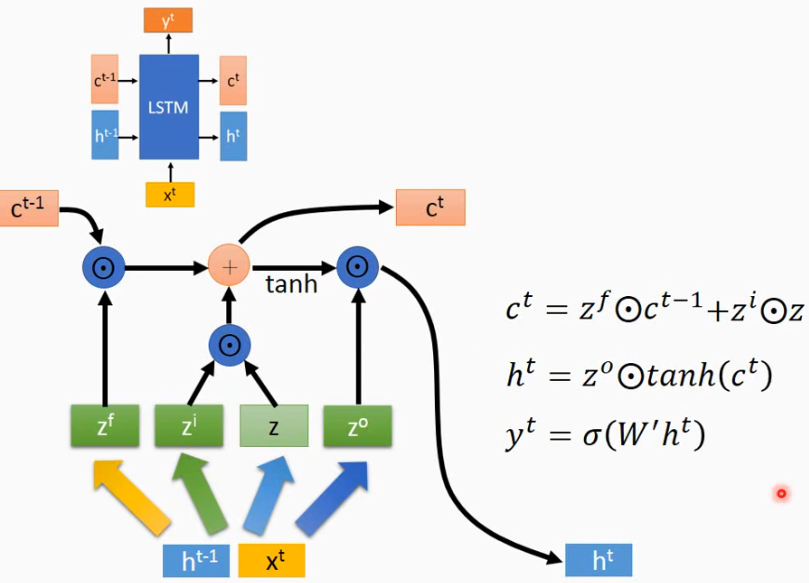
LSTM不受梯度消失的影响,但受梯度爆炸的影响,训练时需要采用梯度裁剪:
如果梯度超过阈值:\(|\hat g|>c\),那么设置\(\hat g={c\over |\hat g|}\hat g\).
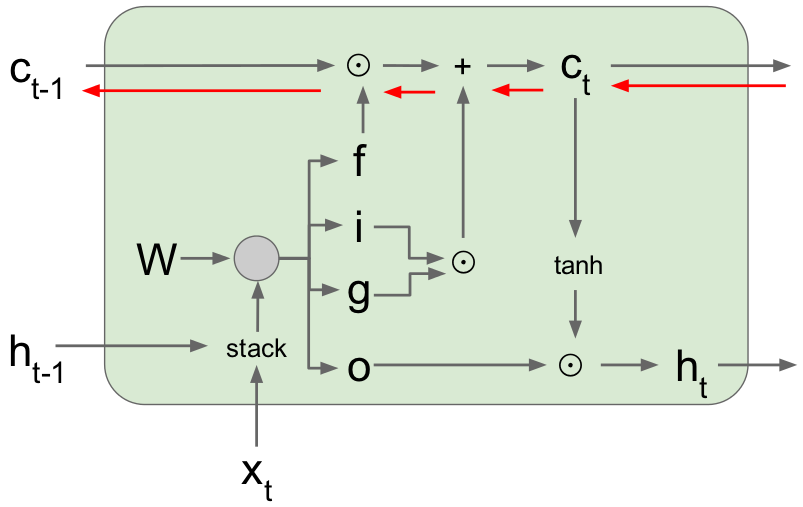
梯度信息流动如下图红色箭头:
语音辨识上的一些实验比较(准确率):
- LSTM > RNN > feedforward
- Bi-direction > uni-direction
keras作者说不需要理解LSTM的具体架构中每个单元是做什么的,只需要知道其容许过去的信息能够在后续的某一时刻被重新使用,这样能够解决梯度消失问题.
GRU
The gated recurrent unit (GRU) [Cho et al., 2014a] 相比LSTM设计更简单一些,包含两个门:重置门与更新门。
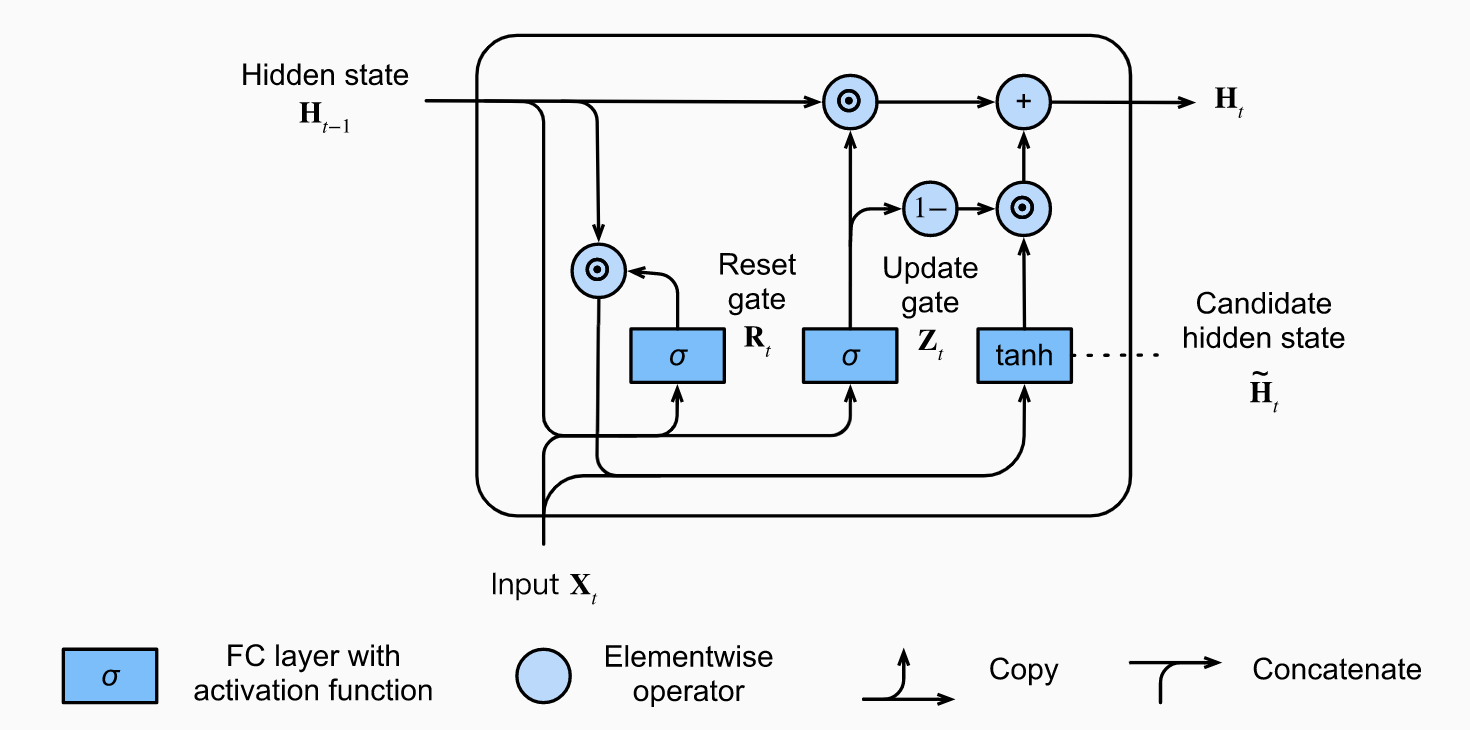
- Reset gates 有助于捕捉短期依赖。
- Update gates 有助于捕捉长期依赖。
参考:https://d2l.ai/chapter_recurrent-modern/gru.html
GRU 和 LSTM 异同
- LSTM 和 GRU 的性能在很多任务上不分伯仲;
- GRU 参数更少,因此更容易收敛,但是在大数据集的情况下,LSTM 性能表现更好;
- 从结构上说,GRU 只有两个门,LSTM 有三个门,GRU 直接将 hidden state 传给下一个单元,而 LSTM 则用 memory cell 把 hidden state 包装起来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
