摘要:
分类别记录博文列表,便于按需查找。 阅读全文
posted @ 2022-06-05 23:33
康行天下
阅读(118)
评论(0)
推荐(0)
 知识蒸馏是一种模型压缩方法,通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的教师模型,在不改变学生模型结构的情况下提高其性能。 阅读全文
知识蒸馏是一种模型压缩方法,通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的教师模型,在不改变学生模型结构的情况下提高其性能。 阅读全文
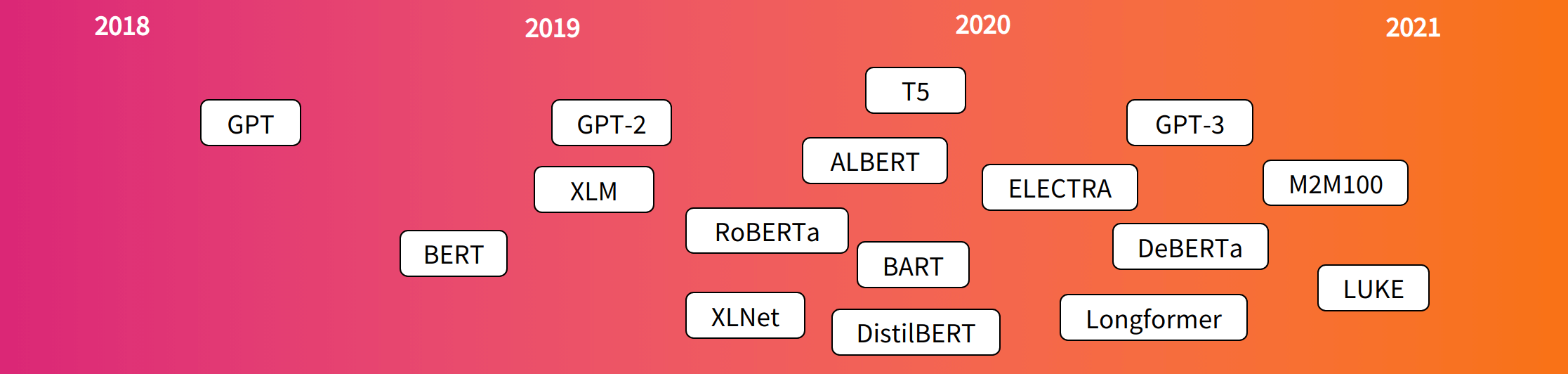 一网打尽十余个Transformer模型。
经典模型:Word2vec, ELMo, Transformer, GPT, BERT, XLNet, UniLM, T5, ALBERT, ELECTRA, DeBERTa, ERNIE. 阅读全文
一网打尽十余个Transformer模型。
经典模型:Word2vec, ELMo, Transformer, GPT, BERT, XLNet, UniLM, T5, ALBERT, ELECTRA, DeBERTa, ERNIE. 阅读全文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号