Spark最简单基础_欢乐的马小纪
Spark笔记
1. flatMap和map的区别
map函数会对每一条输入进行指定的操作,然后每一条输入返回一个对象;
flatMap函数则是两个操作的集合,即先映射再扁平化:
i.同map函数一样,对每一条输入进行指定的操作,然后为每一条输入返回一个对象;
ii.然后将所有对象合并成一个对象。
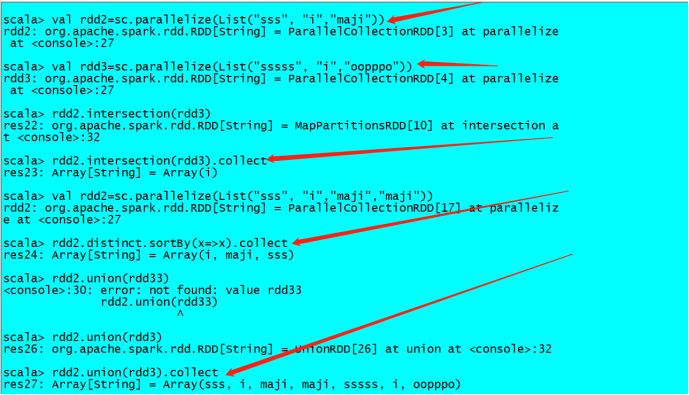
2. 交集并集
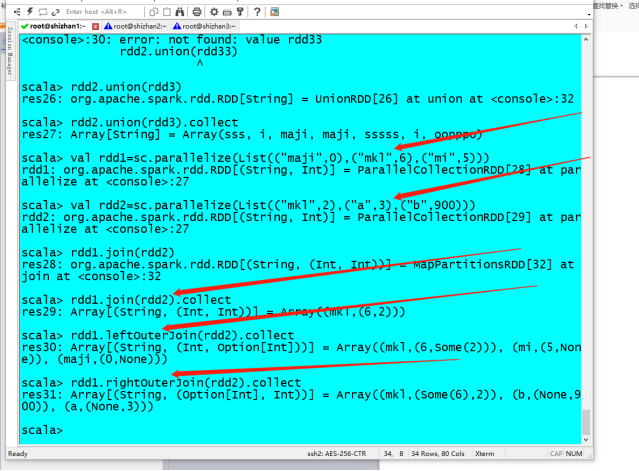
3. 三种join
4. reduceByKey 和 groupByKey 对比
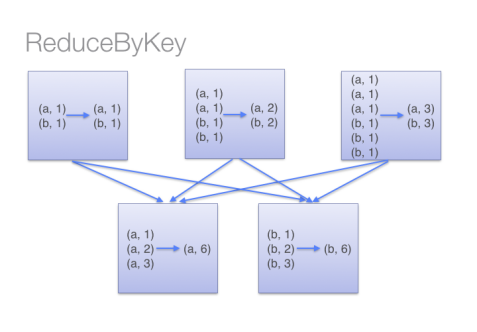
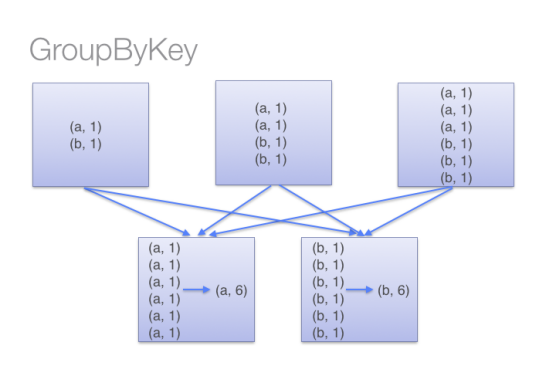
reduceByKey在分发之前做一次运算、分发之后做一次运算。
groupByKey只在分发后做一次运算
也就是说groupByKey主要有有两点缺点:额外的通信成本;分发后的同key记录堆积可能导致内存溢出
那groupByKey 什么必要存在?
reduceByKey groupByKey 就是两个运算框架,我们写业务代码的时候,需要的就是修改“运算”法则,框架规定了我们 reduceByKey 分发前后的运算是一样的。
以上两点缺点的前提是存在运算:只是收集同key的记录 ;需要必须所有数据一起的运算(比如方差)。此时缺点不成立
#WordCount, 第二个效率低
sc.textFile("/root/words.txt").flatMap(line=>line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
sc.textFile("/root/words.txt").flatMap(x=>x.split(" ")).map((_,1)).groupByKey.map(t=>(t._1, t._2.sum)).collect
5. Cogroup
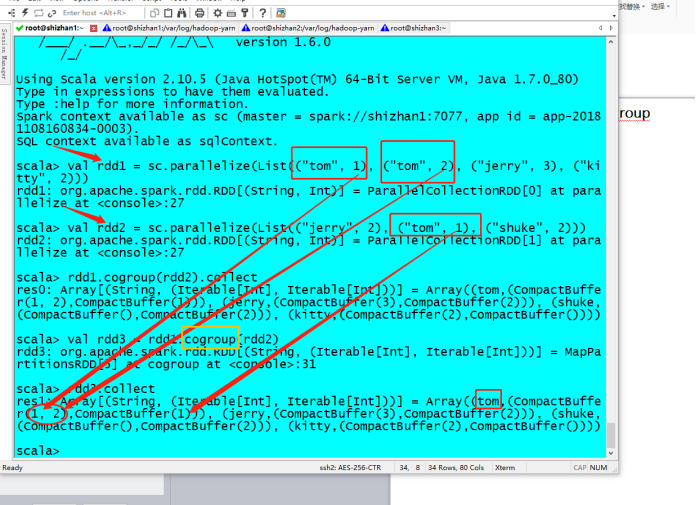
根据key求和
val rdd4 = rdd3.map(t=>(t._1,t._2._1.sum+t._2._2.sum))
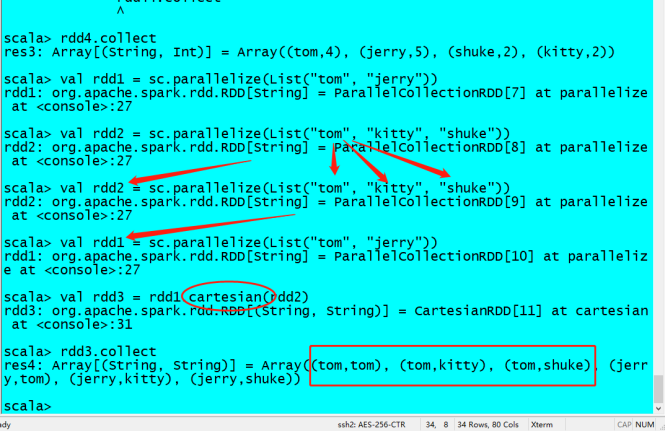
6. 笛卡尔积
7. take,top,first,count,takeOrdered
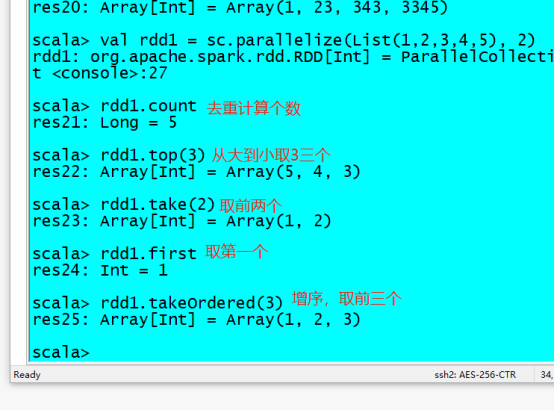
不去重 写错了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号